
随着ChatGPT、文心一言、Claude等大语言模型(LLM, Large Language Models)的崛起,AI 正在以惊人的速度改变人类与知识、语言、甚至创作的互动方式。但你是否遇到过这种情况:一个能写诗的模型,却看不懂医疗报告;一个能聊哲学的AI,却处理不好客服话术?对于开发者和企业来说,如何让这些“通才”模型变成适应特定任务的“专家”模型?微调(Fine-tuning) 正是关键一步。
这篇文章将带你初步了解大模型微调的基本概念、方法分类、应用场景与实践建议。
一、什么是大模型微调?
大模型微调是指在预训练模型的基础上,使用特定领域或任务的数据进行二次训练,使模型适配专业需求的技术。它不是从零开始训练模型(这叫 pretraining),而是以已有的预训练权重为基础进行“二次雕琢”。
PS:注意微调(Fine-tuning)的核心定义是:在预训练模型基础上,通过新任务数据调整模型参数,使其适应特定需求。而Embedding和VAE这种属于微调的工具,并不是微调的方法。所以它们不属于微调模型本身,但可以作为微调的对象或组成部分。
举个例子:
假设你已经有一个训练好的 GPT 模型,它可以流畅地写作。但你想让它变成一个法律顾问机器人,它就需要通过“法律领域的数据”进行微调,增强专业知识、术语理解和风格适应能力。
二、为什么要微调?
虽然通用大模型“什么都懂一点”,但在实际业务场景中常常存在以下问题:
领域知识不足:通用模型缺乏垂直行业的术语与逻辑
风格定制需求:调整模型输出语气
任务精准优化:提升特定任务效果
通过微调,我们可以实现:
提升模型在特定任务的表现
注入领域知识和语料
降低推理时对 prompt 工程的依赖
增强模型的稳定性和风格控制
三、微调 vs 提示词工程 vs RAG
在构建特定场景的 AI 应用时,下面这三种概念经常让人混淆:提示词工程(Prompt Engineering)、微调(Fine-tuning)和RAG(Retrieval-Augmented Generation)。它们本质不同,适用的业务场景也有差异。
下面是三者的详细对比:
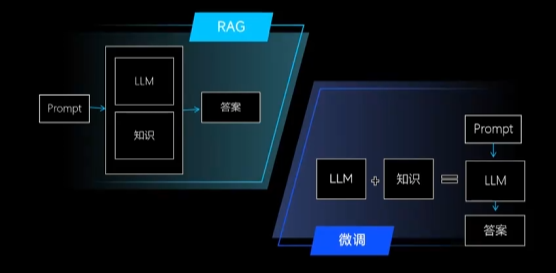
简单理解:
提示工程 = 不动模型,巧妙提问
微调 = 改造模型,让它变聪明
RAG = 外挂知识库,实时查再答,也是不动模型的
四、微调方法
根据资源与目标,可选择不同微调方案:
全参数微调(Full Finetuning)
参数高效微调(PEFT):LoRA、QLoRA、Adapter Tuning、Prefix Tuning、Prompt Tuning、P-Tuning、P-Tuning v2
其他微调策略:知识蒸馏、多任务学习、持续学习、领域自适应
4.1 全参数微调(Full Finetuning)
这是最传统、也最直接的微调方法:将预训练模型的所有参数作为可训练参数,在下游任务上进行梯度更新。
优点:
表现最强,理论上能充分利用所有模型能力。
对复杂任务适应性好(如长文本生成、复杂推理等)。
缺点:
成本高:大模型参数量庞大,训练计算资源消耗极大。
存储压力:每个任务都要存储一份完整模型副本。
易灾难性遗忘(Catastrophic Forgetting):对原始能力影响较大。
4.2 参数高效微调(PEFT)
PEFT类方法的核心思想是:在尽可能不动原始大模型参数的基础上,少量引入新的可训练模块或结构来完成微调任务。它大幅降低了资源开销和存储成本,成为近年来微调研究的热点。
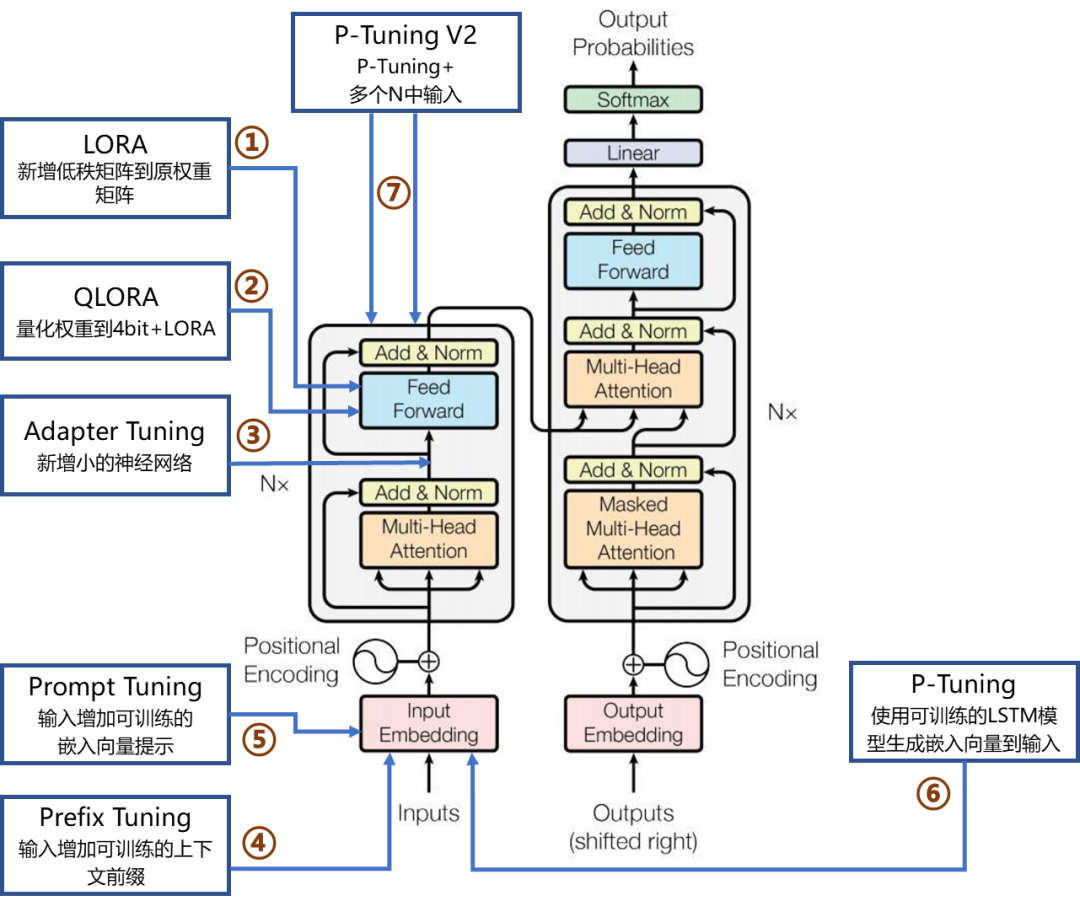
1. LoRA(Low-Rank Adaptation,低秩适应)
LoRA在Transformer中的注意力和前馈层引入可训练的低秩矩阵,以近似原始参数的更新。
原始权重保持冻结,新增少量可训练参数(通常减少90%+训练参数量)。
理论基础扎实,已被广泛用于LLaMA、ChatGLM、BLOOM等模型。
优点:
高效、轻量;与原始模型解耦;
支持不同任务共享底座模型。
2. QLoRA(Quantized LoRA)
在LoRA基础上进一步发展,QLoRA将原始模型量化为4-bit权重,同时配合LoRA进行训练,显著减少显存占用。
引入double quantization 和 NF4量化格式(normal float 4)。
可在消费级GPU上完成130B模型的微调。
优点:
极低内存需求;
保留性能的同时,实现廉价训练。
初学者首选LoRA/QLoRA:在效果接近全参数微调的同时,显存占用大幅降低,且支持多任务适配器切换
3. Adapter Tuning(适配器调整)
在Transformer的每一层插入一个小型瓶颈结构(通常是下降-上升的MLP),只训练这些适配器层,冻结原模型。
最早由Google在BERT中提出;
类似“插拔式”组件,不同任务可加载不同adapter。
适用场景:
多任务共用底座模型;
移动端部署任务特定插件。
4. Prefix Tuning(前缀调整)
为每一层的注意力机制添加可训练的前缀向量(Prompt Embeddings),引导模型产生任务相关输出。
原始模型保持冻结;
与prompt tuning不同的是,其操作作用于注意力KV空间。
优点:
训练效率极高;
适合多轮对话、文本生成任务。
5. Prompt Tuning(提示调整)
Prompt Tuning仅优化输入嵌入层前的一组可学习Prompt向量,用于“激发”大模型预训练知识。
模型架构和参数完全不变;
训练参数量极小(可低至几百个向量)。
限制:
适用于生成式任务(如文本生成、代码生成);
表达能力有限,不适合复杂任务。
6. P-Tuning
P-Tuning v1 引入 可训练连续嵌入向量,将其插入到原始输入前,提升提示表达能力。
通常配合BERT类模型使用;
不改变原始模型参数。
优点:
表达更灵活;
可兼容分类等判别任务。
7. P-Tuning v2
P-Tuning v2在v1基础上进一步发展,采用深层Prompt嵌入结构(Deep Prompt Tuning),在Transformer的多个层中插入提示向量。
更适合多轮对话、生成类任务;
提示嵌入从浅层扩展到深层,效果优于浅层Prompt。
特点:
能在冻结参数的基础上逼近全参微调性能;
与LoRA、Prefix等可结合使用。
4.3 其他微调方法补充
1. 知识蒸馏(Knowledge Distillation)
通过让一个小模型(学生模型)模仿大模型(教师模型)的输出,实现压缩和加速。
蒸馏输出包括:soft logits、attention map、中间隐藏层;
适用于推理速度敏感场景。
2. 多任务学习(Multi-task Learning)
多个相关任务共享底座模型进行微调,通过任务之间的正迁移提高泛化能力。
常用于对话、问答、文本生成等自然语言任务;
BERT、T5在预训练阶段就是一种多任务结构。
3. 持续学习(Continual / Incremental Learning)
在不忘记已有任务的前提下,不断学习新任务。重点解决“灾难性遗忘”问题。
常结合正则化(如EWC)、回放机制(replay)、参数隔离等方法;
挑战大,应用于动态场景。
4. 领域自适应(Domain Adaptation)
针对训练分布与目标分布不同的问题,适配预训练模型到新领域(如医学、金融等)。
包括无监督、自监督领域适配;
方法如DAPT、TAPT、meta-transfer等。
4.4 总结
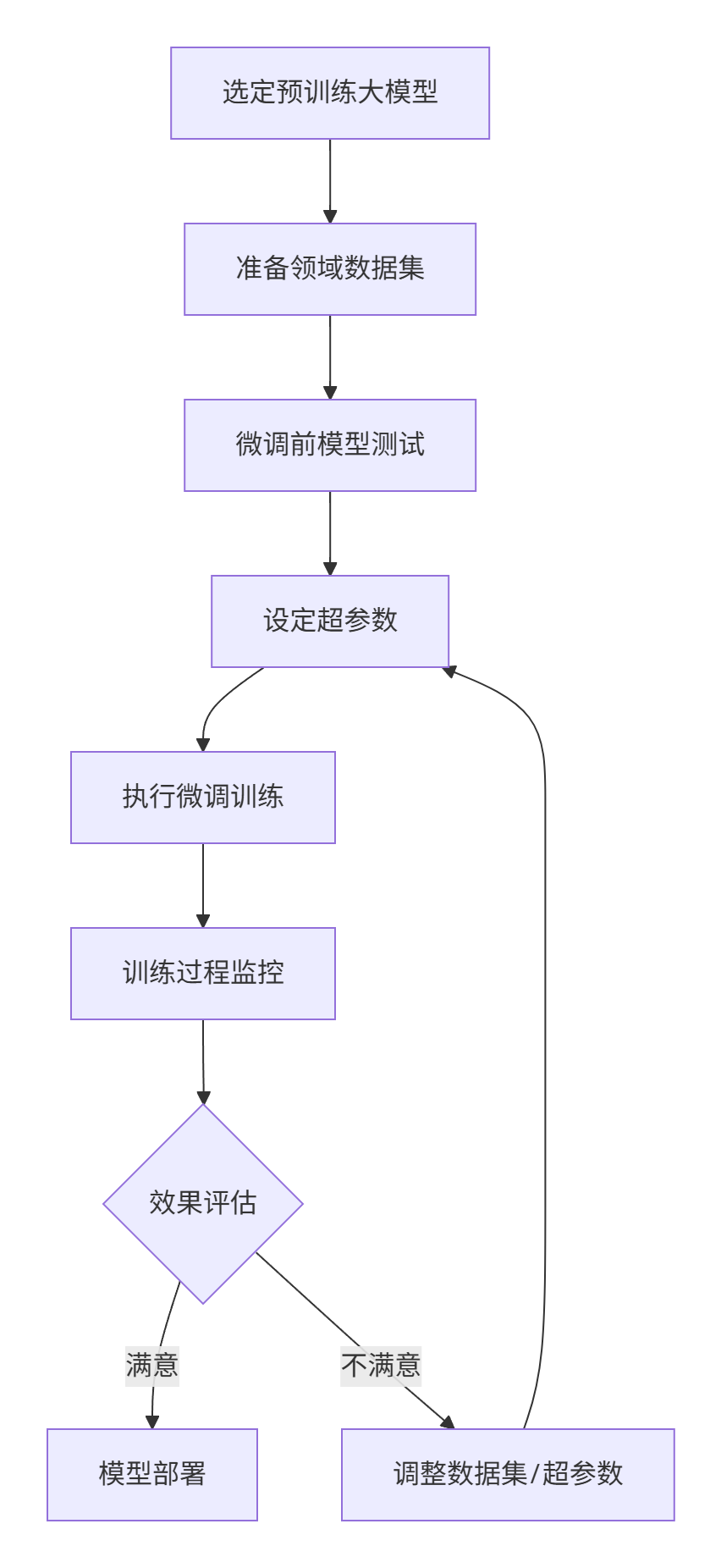
五、微调的基本流程
选定一款用于微调的预训练模型、准备好用于模型微调的数据集、准备一些问题,对微调前的模型进行测试(用于后续对比)、设定模型微调需要的超参数、执行模型微调训练、观测微调过程、对微调后的模型进行测试,并对比效果、如果效果不满意,继续调整前面的数据集以及各种超参数,直到达到满意效果、导出并部署微调好的模型。
实操
这部分笔者专门新开一篇新的博客讲解,地址如下:



评论区