
当我的RTX 4060在运行FLUX.1模型时,满显存的占用在我的资源监视窗格刺眼的展示,生成进度卡在采样器部分无法继续,8GB显存已成为SD创作瓶颈。 作为低端显卡用户,过去常被迫在“降低分辨率”和“裁剪模型精度”间妥协,直到尝试了MIT Han Lab开源的Nunchaku推理引擎。
这个基于SVDQuant量化技术的工具彻底颠覆了我对低精度模型能力的认知——它竟能在4-bit精度下保持近乎无损的生成质量,同时将12B参数模型的显存需求压到惊人的8GB以内,让小显存显卡也能流畅运行顶级扩散模型
一、Nunchaku 是什么?
Nunchaku 是由 MIT Han Lab 开发的高性能 4-bit 扩散模型推理引擎,基于其开创性论文 《SVDQuant》技术构建。它通过量化压缩技术,将模型显存占用大幅降低 ,推理速度也得到了巨幅提升 ,同时保持生成质量几乎无损,成为当前AI绘图领域最快的本地化加速方案之一。
注意:最低支持图灵架构(20系)显卡,AMD暂不支持
核心优势:
极速出图: 根据Github上的数据,RTX 4090 在使用FLUX.1-dev BF16模型时,实现 高分辨率图像13秒左右生成
显存优化:12B FLUX.1 模型显存占用从 22.7 GiB 降至 6.3 GiB,笔记本显卡也能流畅运行
全兼容性:支持 FLUX 全系模型、LoRA、ControlNet、Redux 工作流,无缝接入 ComfyUI 节点系统

二、Nunchaku技术原理:SVDQuant 量化与引擎优化
1. SVDQuant 三阶段量化流程
Stage 1|异常值检测:定位激活值(
X)和权重(W)中阻碍4-bit量化的极端数值;Stage 2|异常值迁移:将激活中的异常值迁移至权重,生成新权重
Ŵ;Stage 3|低秩分解:对
Ŵ做奇异值分解(SVD),拆解为 低秩矩阵(16-bit) + 残差(4-bit),显著降低量化误差。
2. 引擎级加速技术
首块缓存(First-Block Cache):缓存首层计算结果,50步推理速度大幅提升;
内核融合:合并 Down Projection和 Quantize 、Up Projection 和 4-Bit Comput等操作,减少数据移动开销;
三、Nunchaku在ComfyUI的应用
https://github.com/mit-han-lab/ComfyUI-nunchaku
首先到上方的地址下载插件,有两种方法
1.下载zip压缩包,解压到comfyui根目录下的custom_nodes文件夹,重启ComfyUI启动器。
2.使用git:在custom_nodes文件夹的目录输入cmd,回车,用git clone下载原码,重启启动器。
git clone https://github.com/mit-han-lab/ComfyUI-nunchaku.git配置需求:
Python>=3.10
PyTorch>=2.6
CUDA>=12.6
注意:50 系列显卡请使用 CUDA>=12.8 ,PyTorch>=2.7
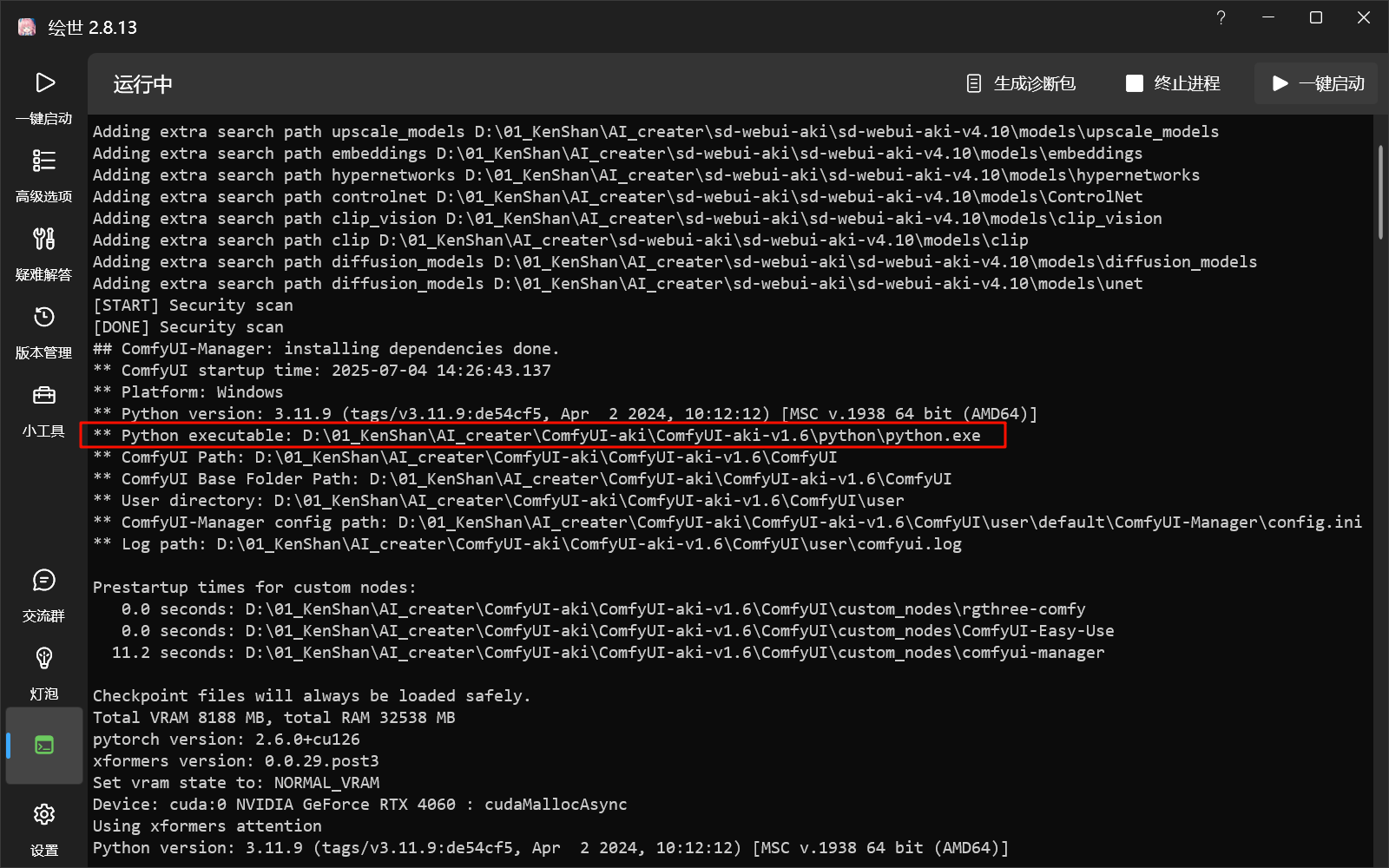
在启动器的控制台可以看到版本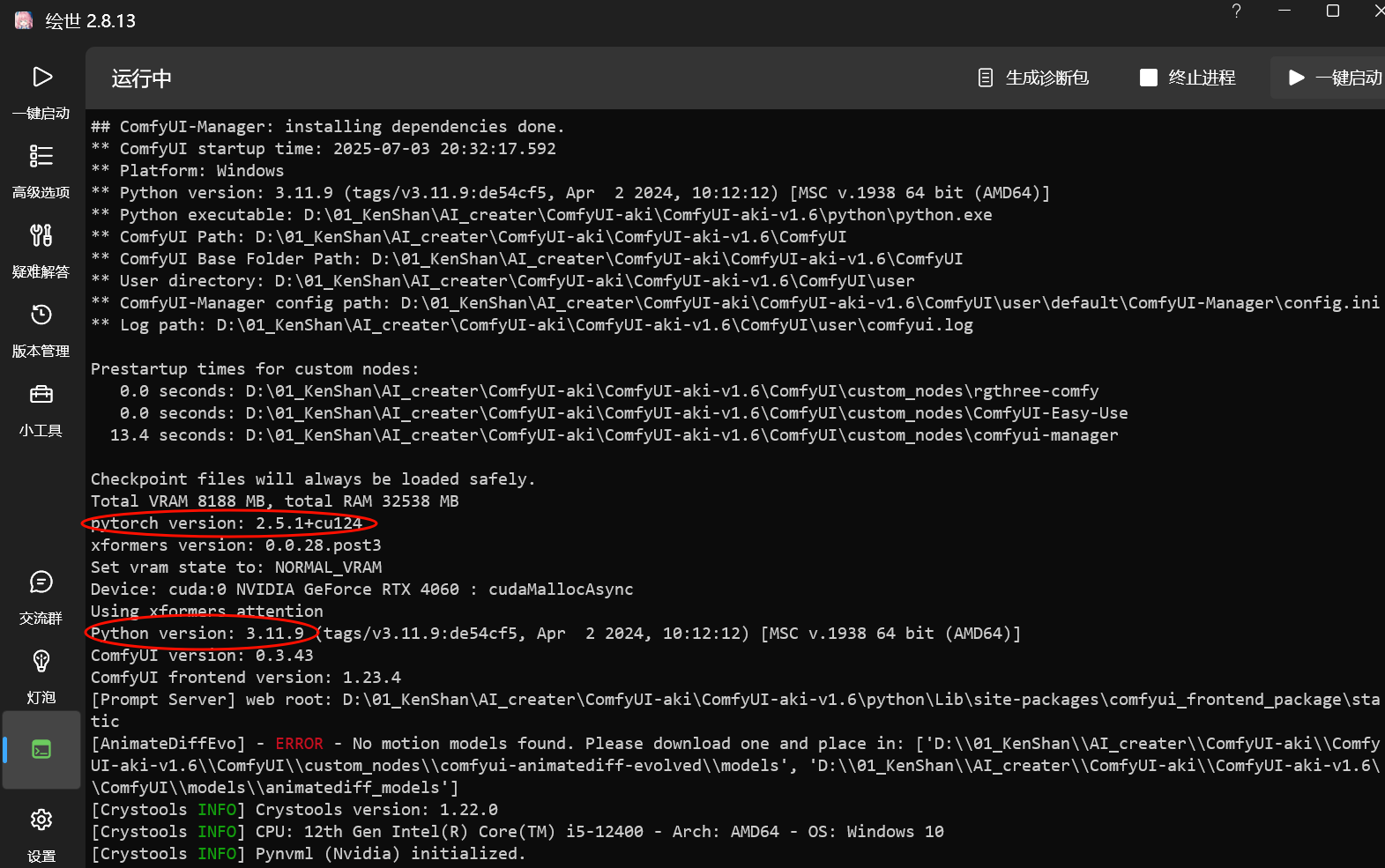
安装需求配置:
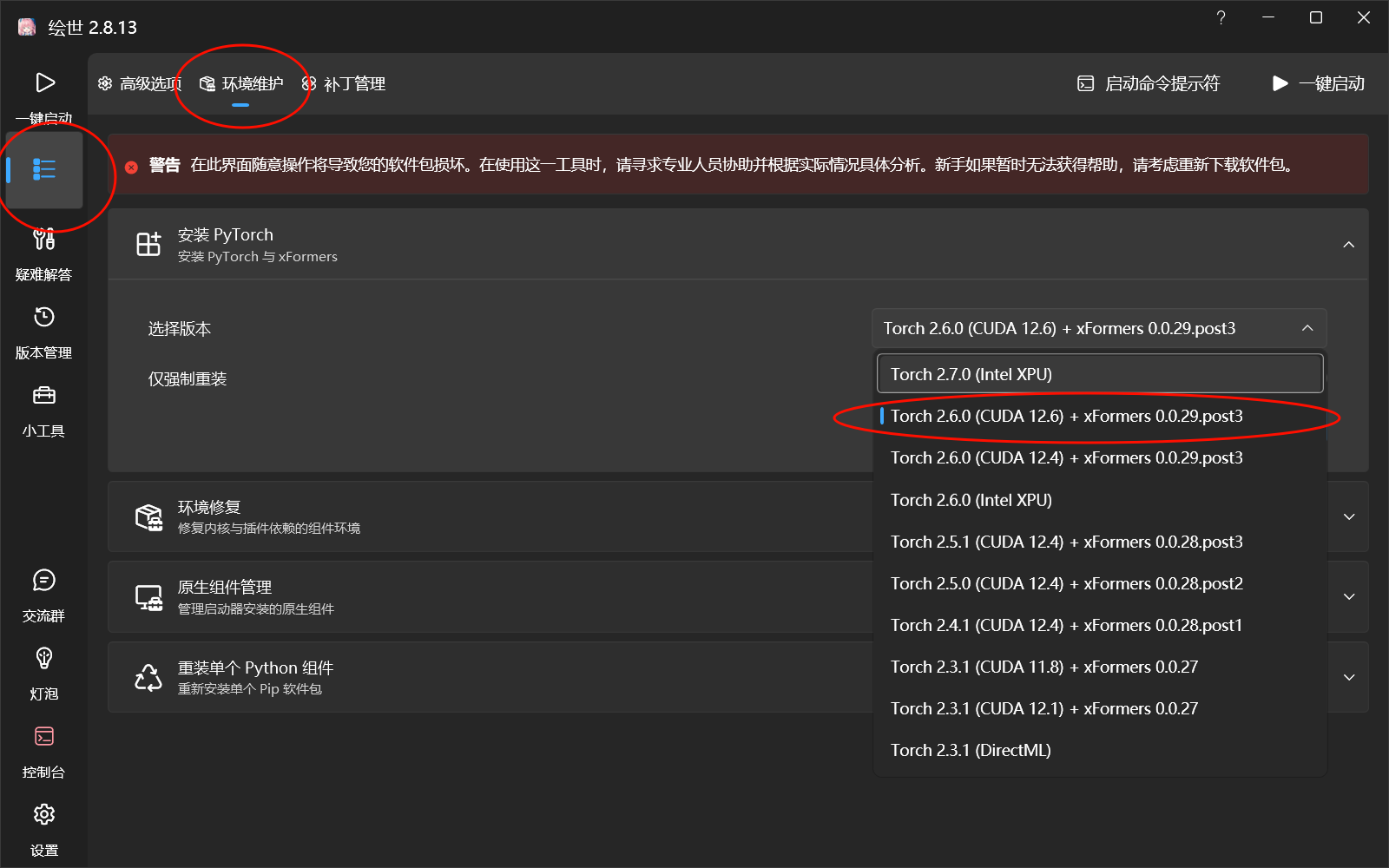
在启动器内一次点击高级选项→环境维护→选择“Torch 2.6.0 (CUDA 12.6) + xFormers 0.0.29.post3”→安装
注意:50系显卡选择“Torch 2.7.0 (CUDA 12.8) + xFormers 0.0.30”
等待片刻
重启启动器,重启后观察控制台是否有变化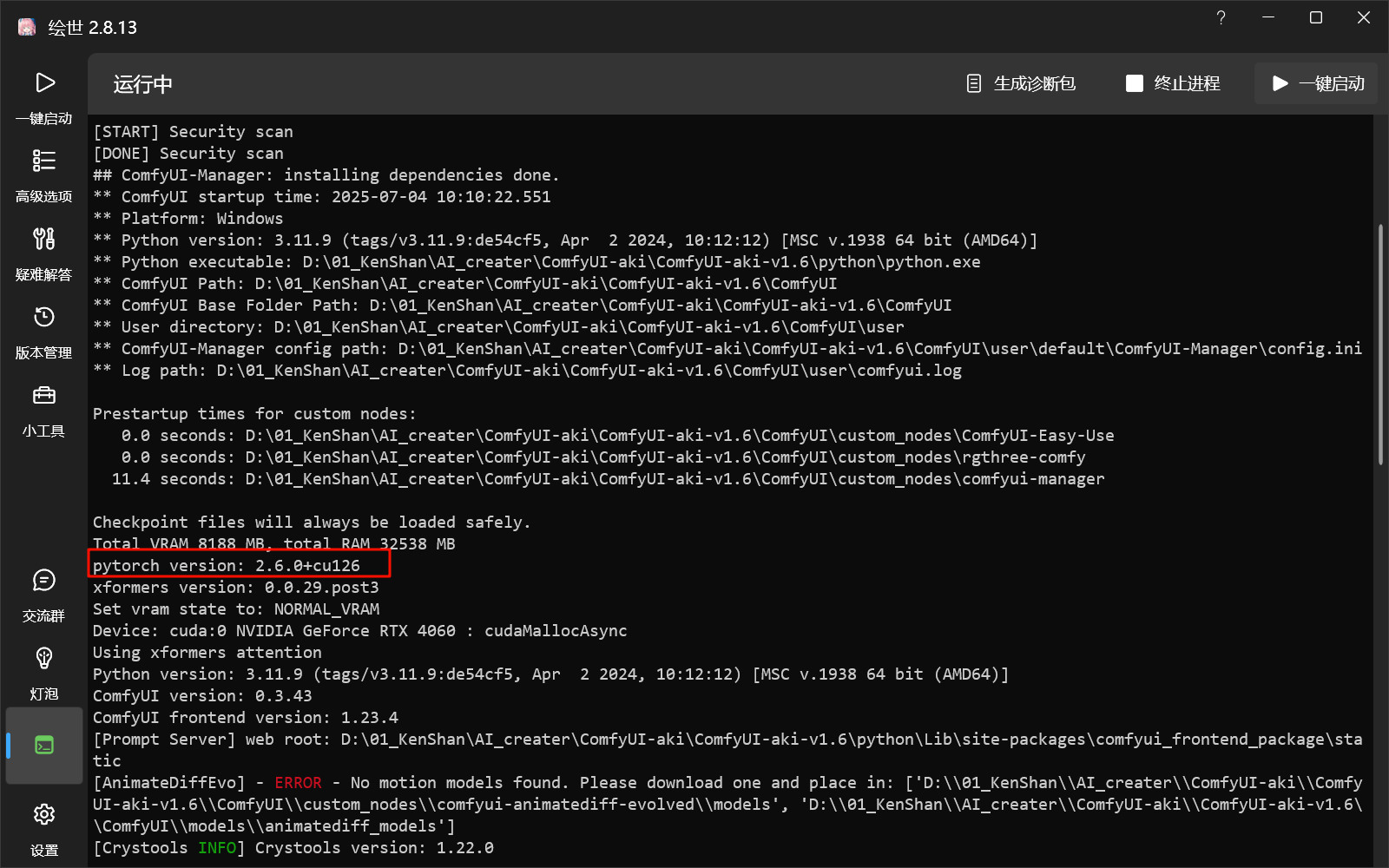
注意:如果在发现配置安装失败,请把ComfyUI更新到一个比较新的版本
更改ComfyUI版本:启动器左侧栏版本管理→切换(你想要的版本)
安装正确版本的轮子文件(wheel file)
接下来是,我们要根据python、pytorch、cuda的版本来下载nunchaku所需的配置文件(wheel file)。
https://github.com/mit-han-lab/nunchaku/releases
进入上面的地址,选择你想要版本的wheel file,点击链接下载。
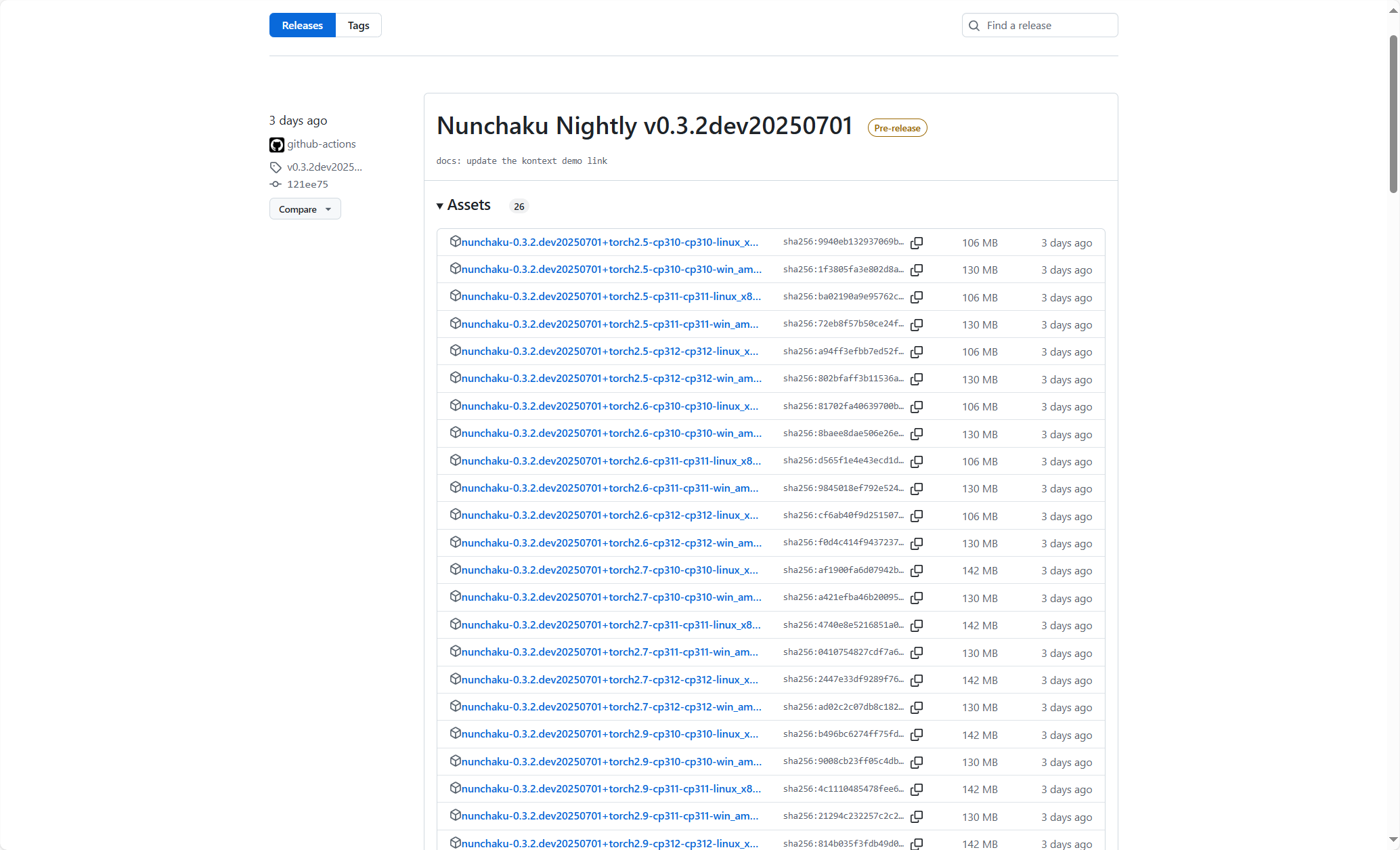
下载后,按照下面复制路径地址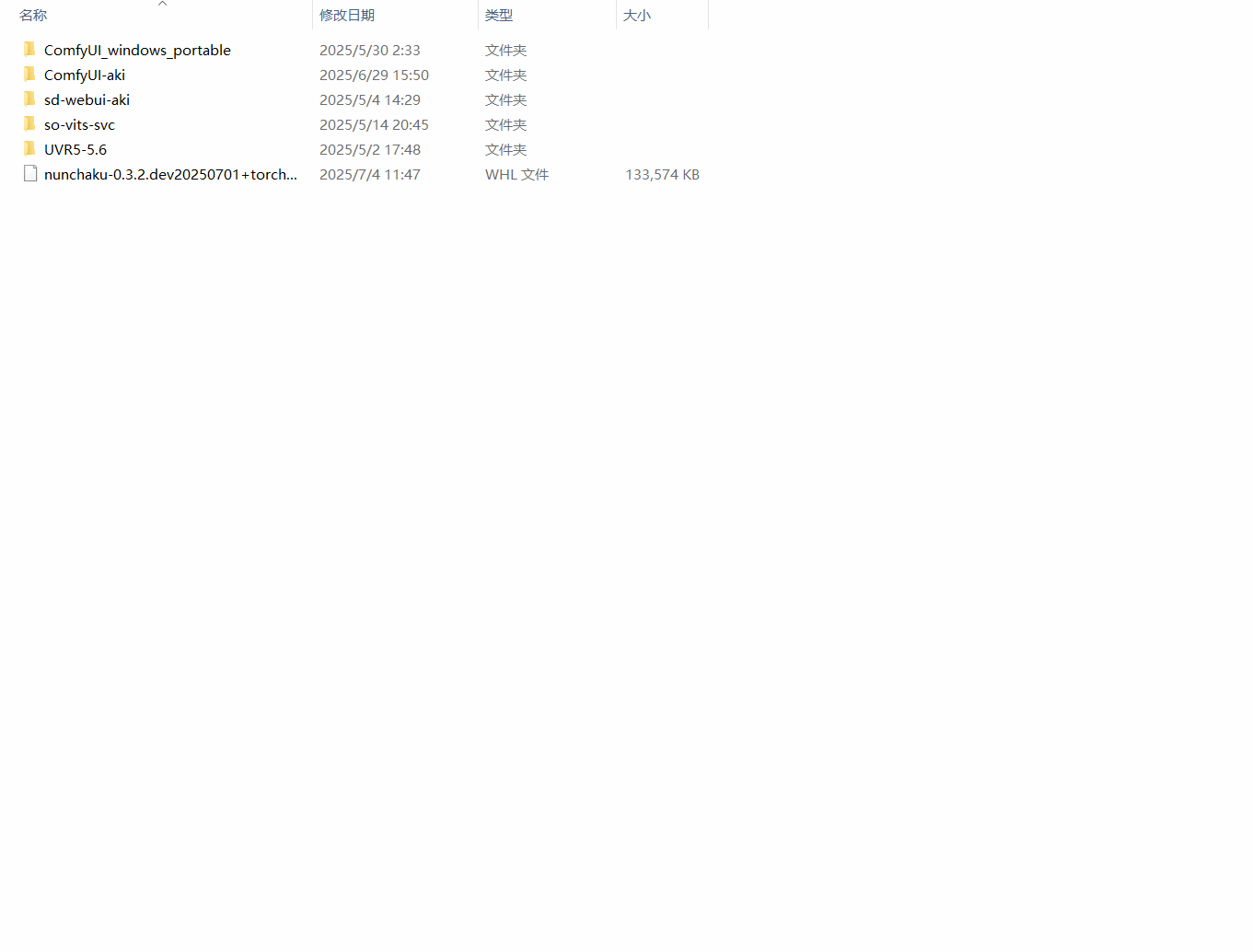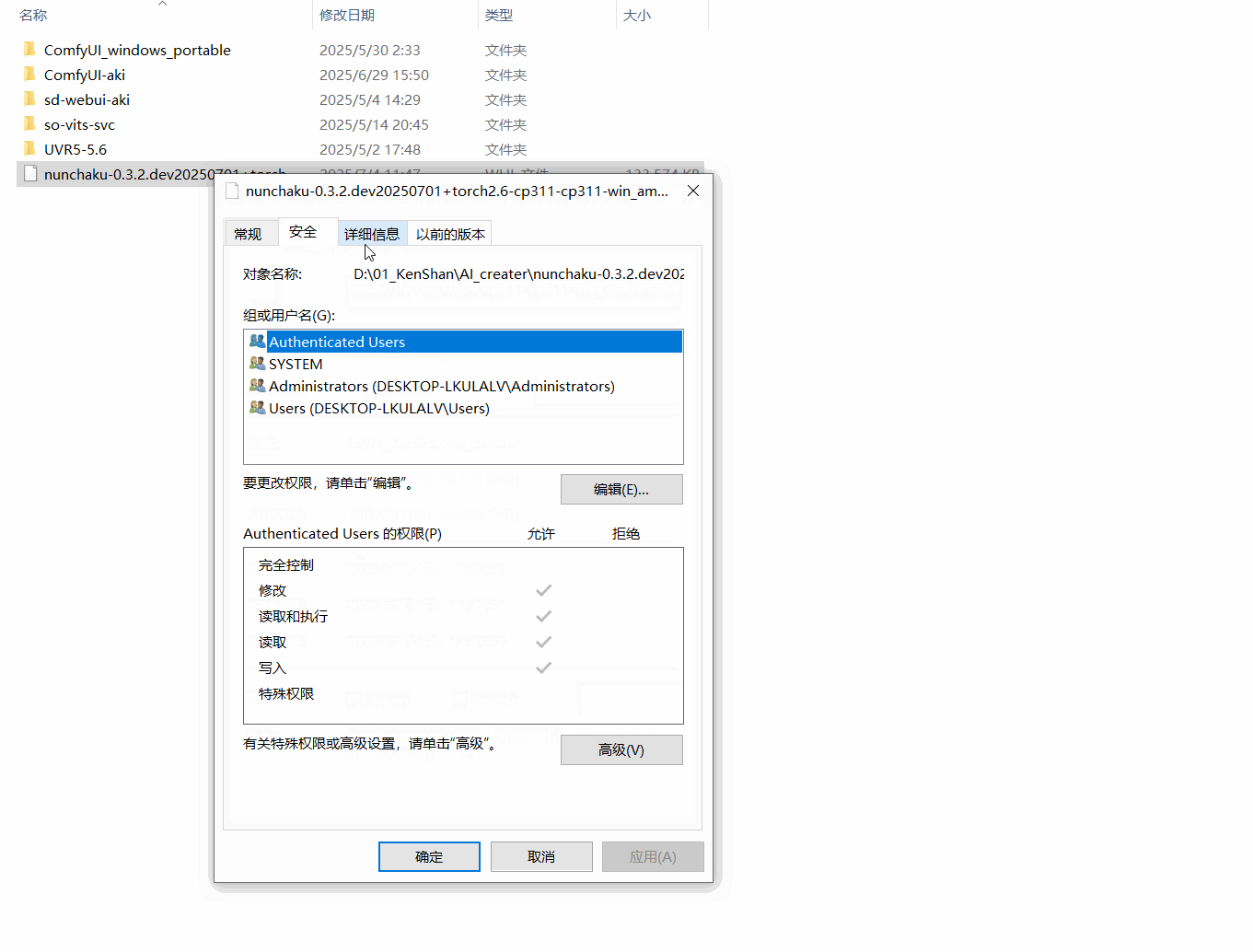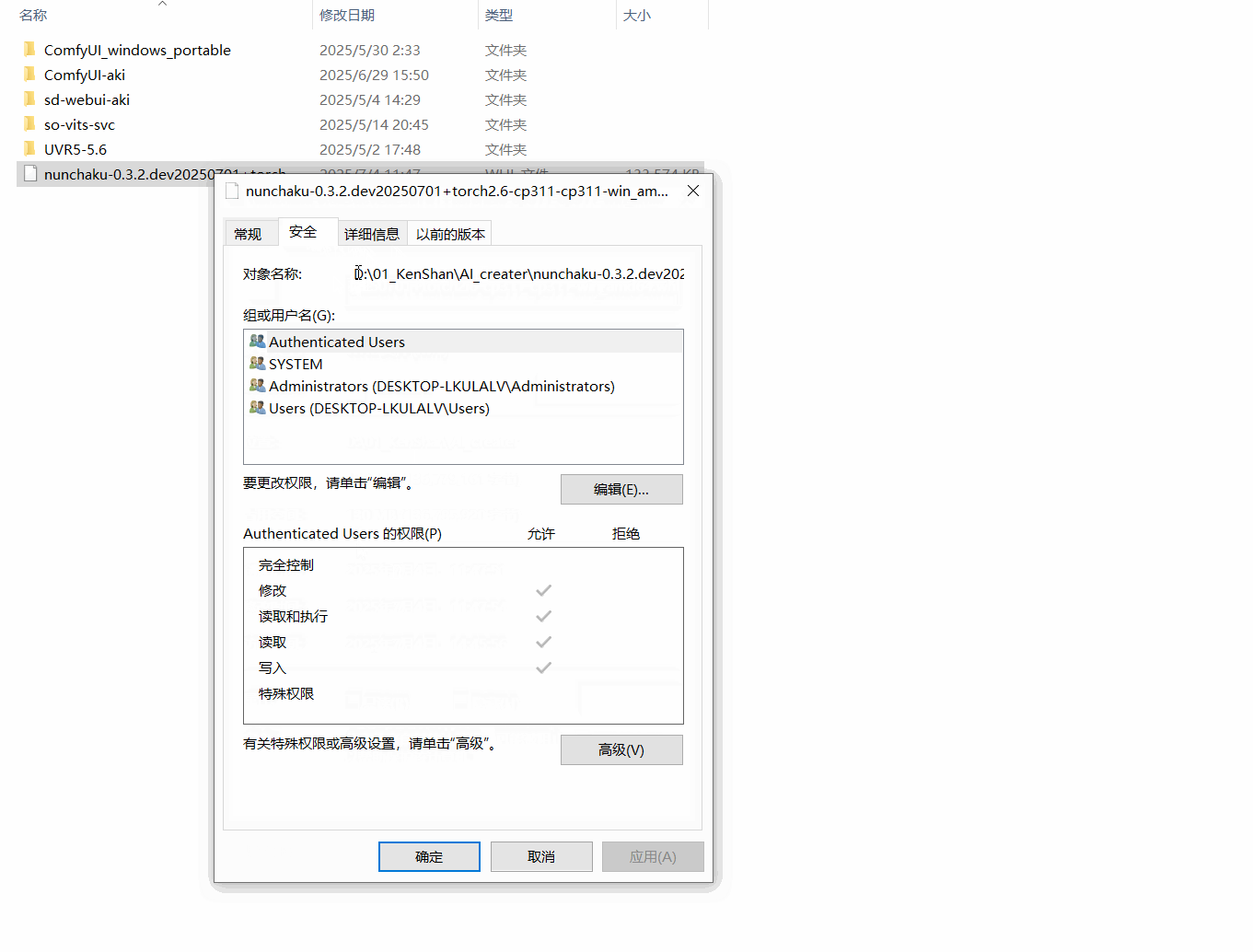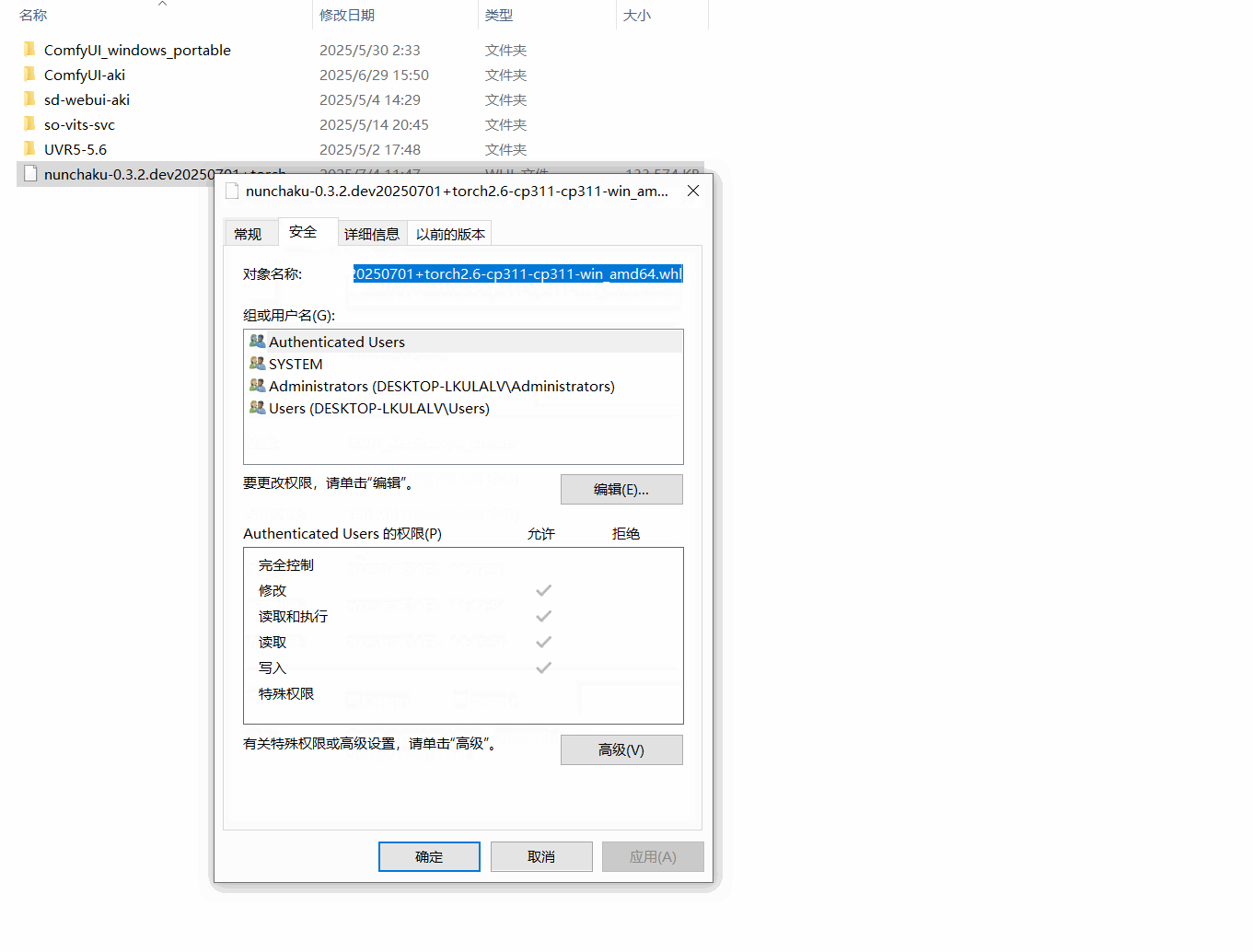
在启动器控制台界面内,找到python解释器的路径地址
打开python解释器路径目录文件夹,操作:1)地址栏输出cmd,回车;2)输入下面命令行
python.exe -m pip install <刚才复制的你的轮子文件所在地址>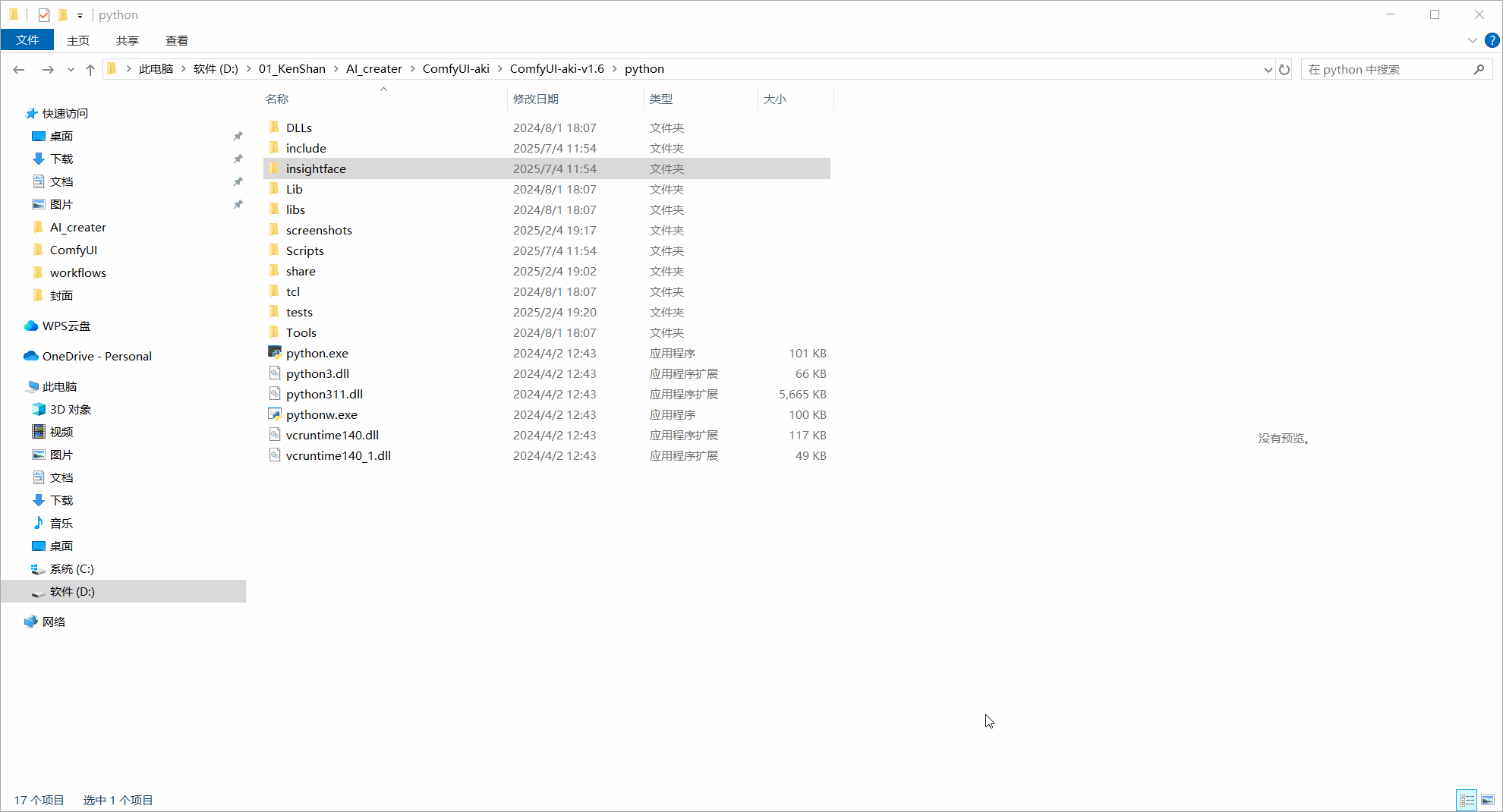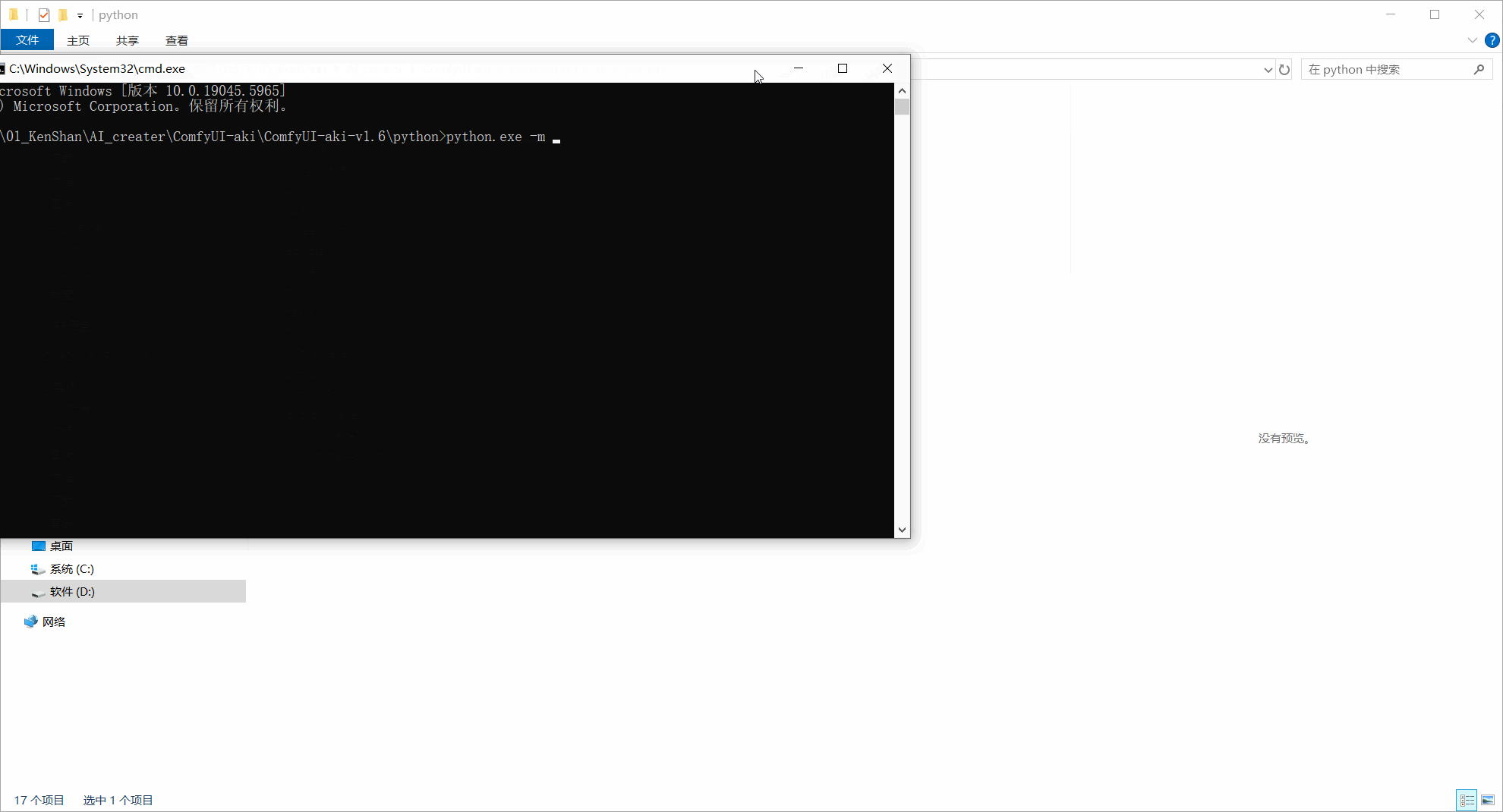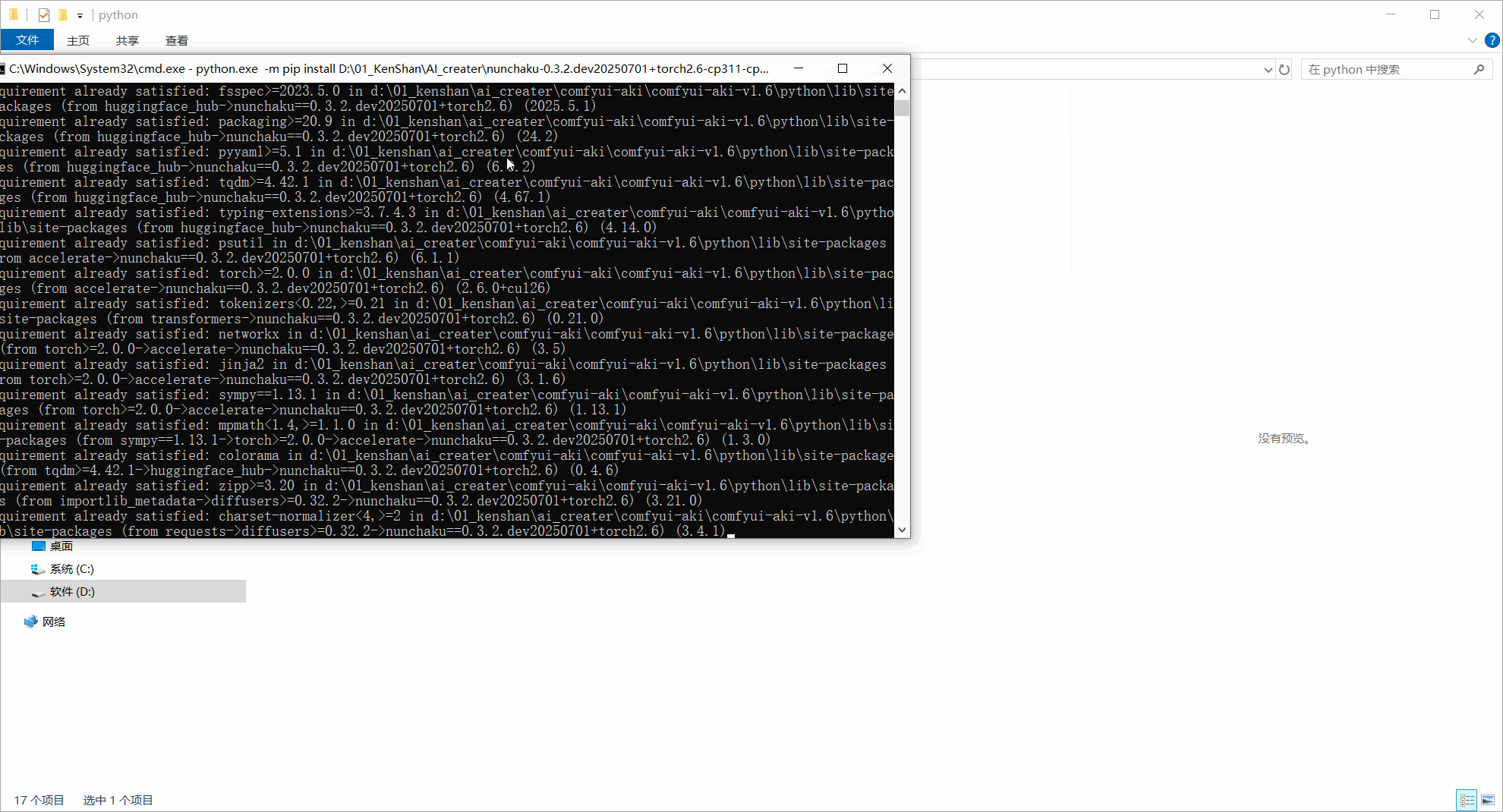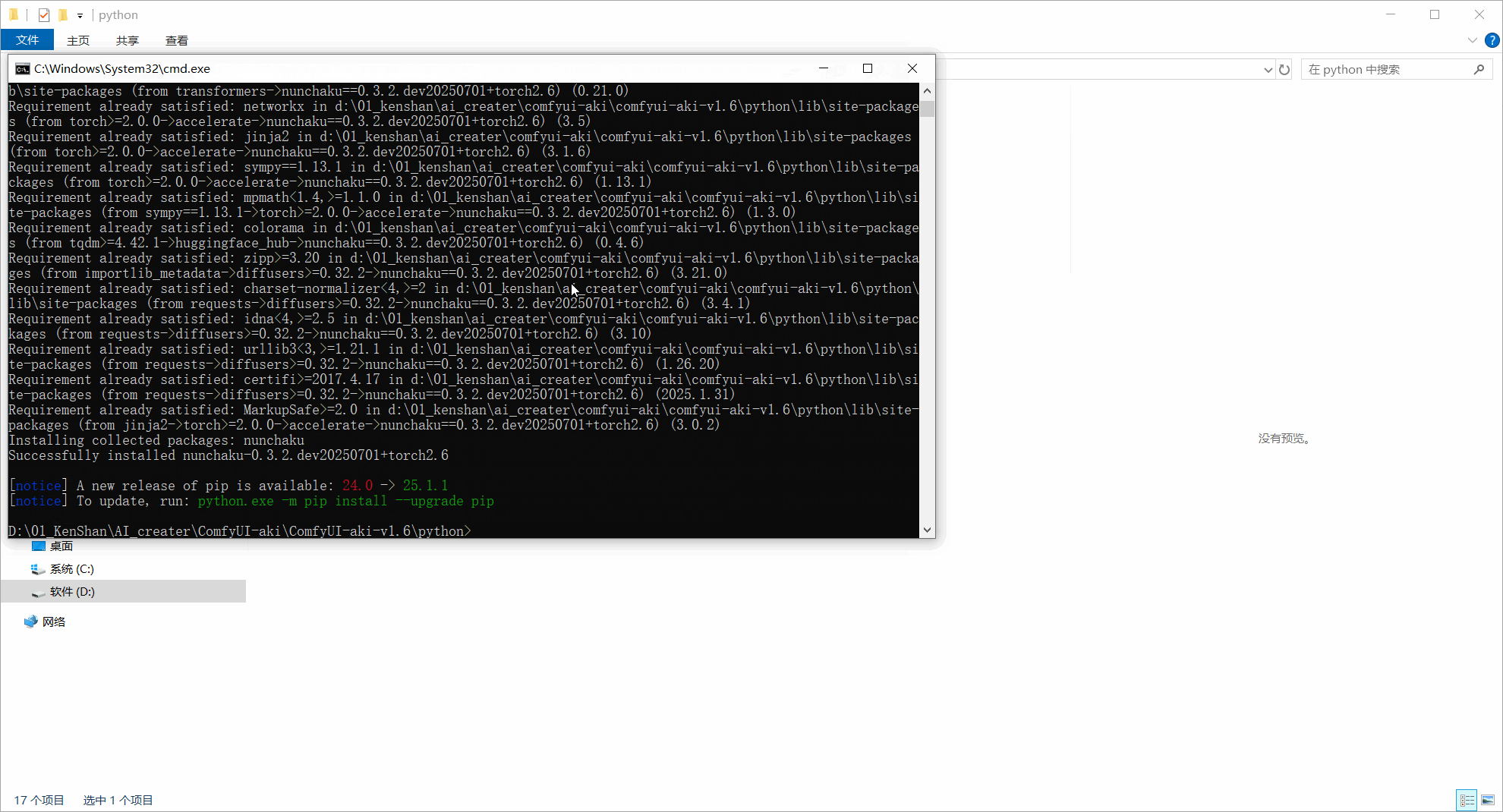
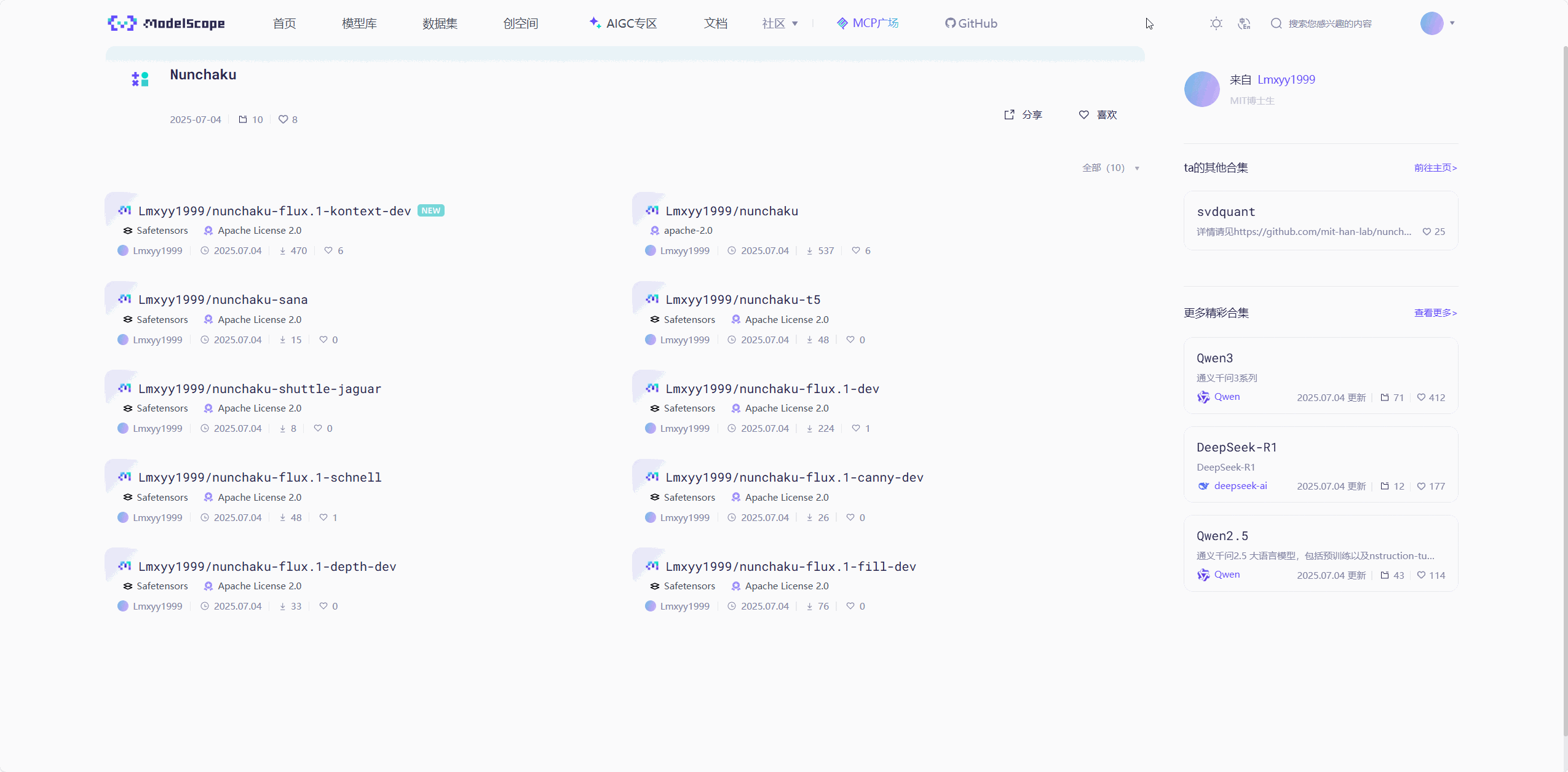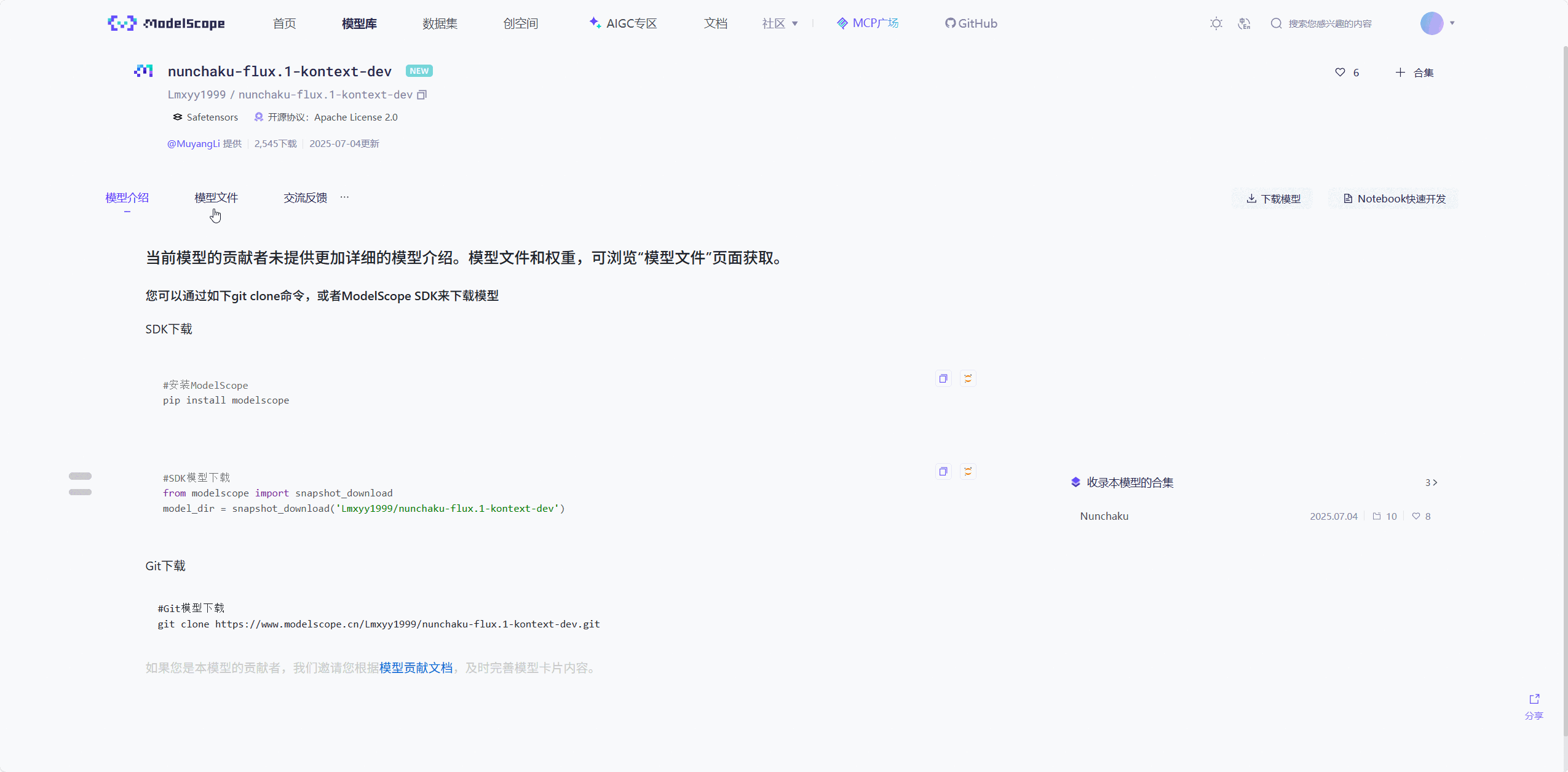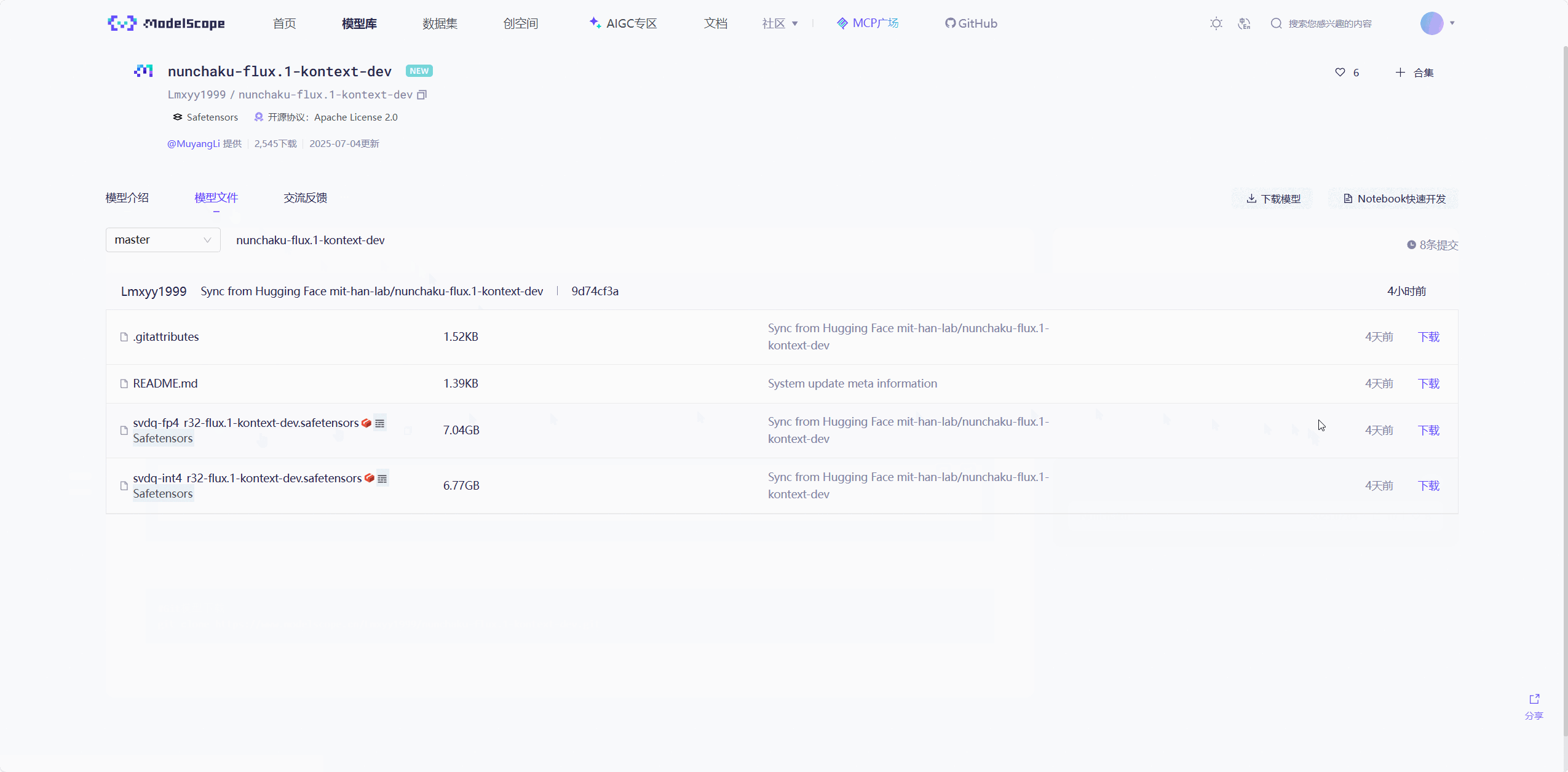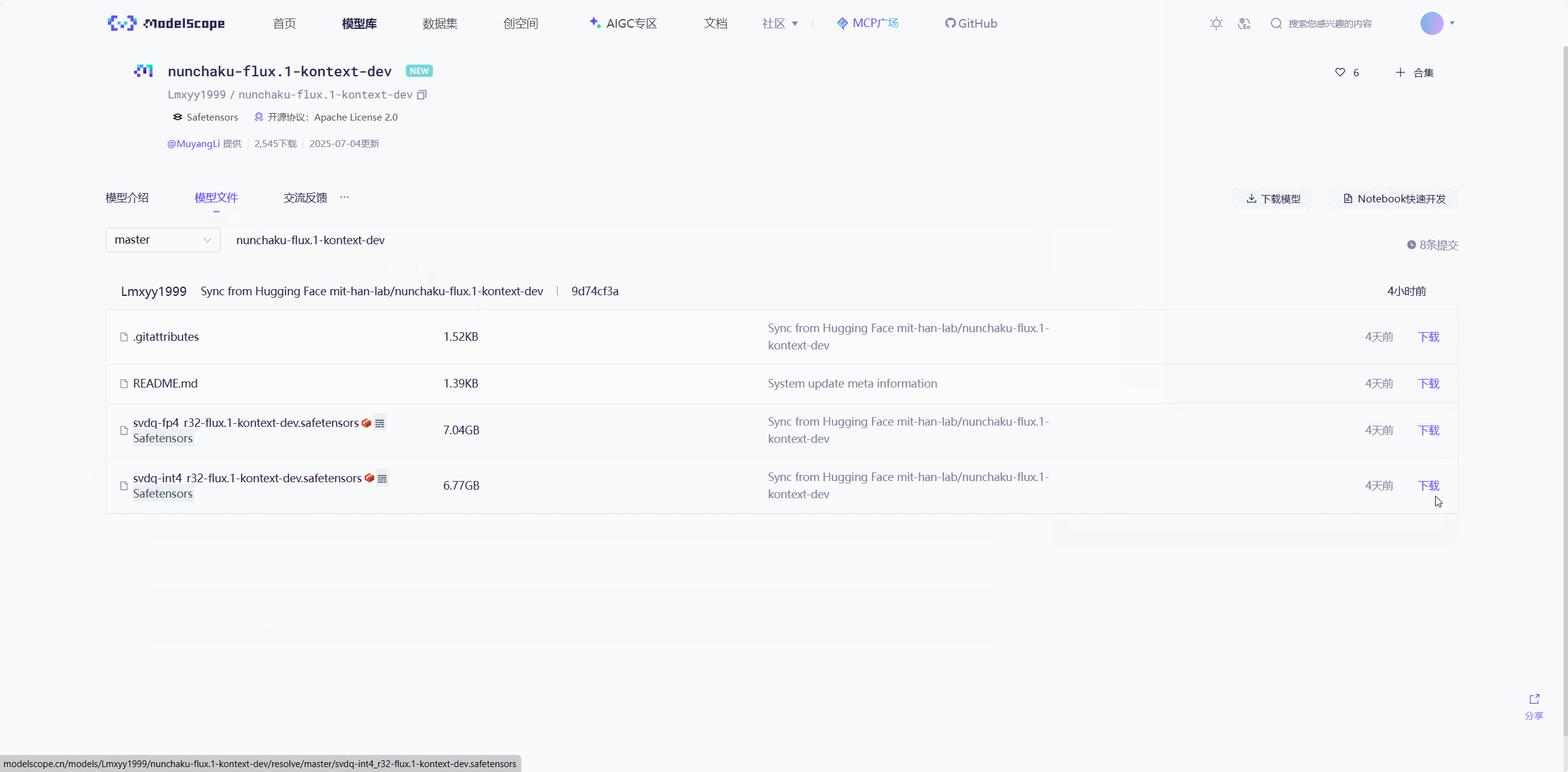
量化模型下载:
Huggingface: https://huggingface.co/collections/mit-han-lab/nunchaku-6837e7498f680552f7bbb5ad
ModelScope(魔搭): https://modelscope.cn/collections/Nunchaku-519fed7f9de94e
接下来我们需要下载nunchaku官方给我们的量化模型地址,根据上面的两个网站来下载
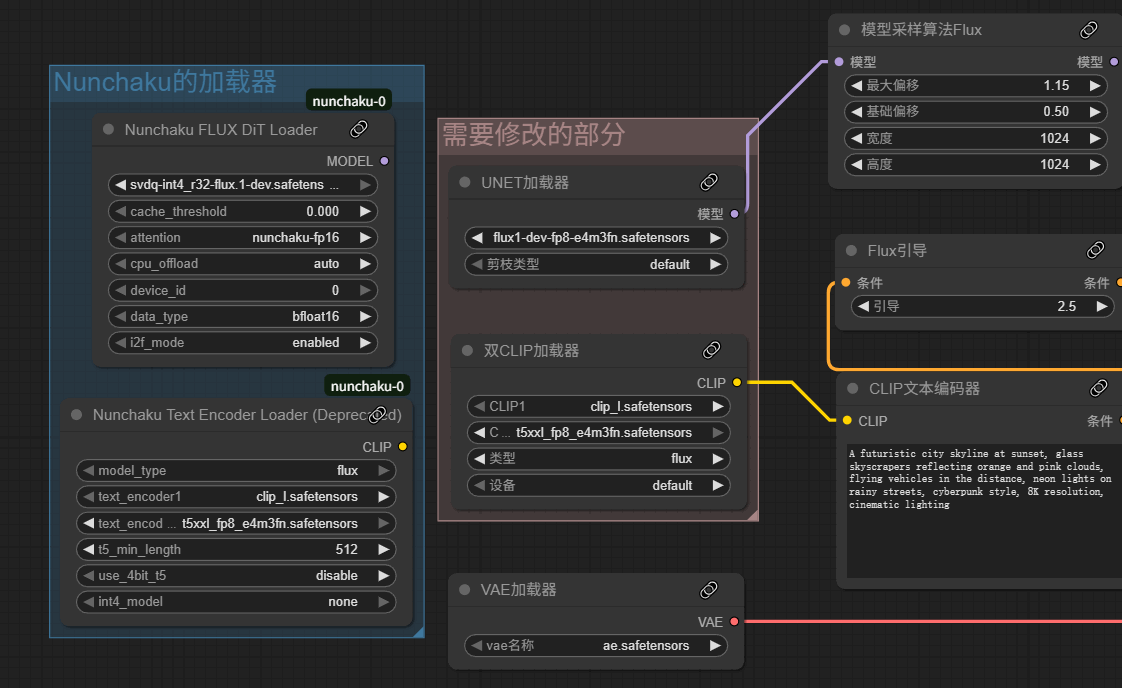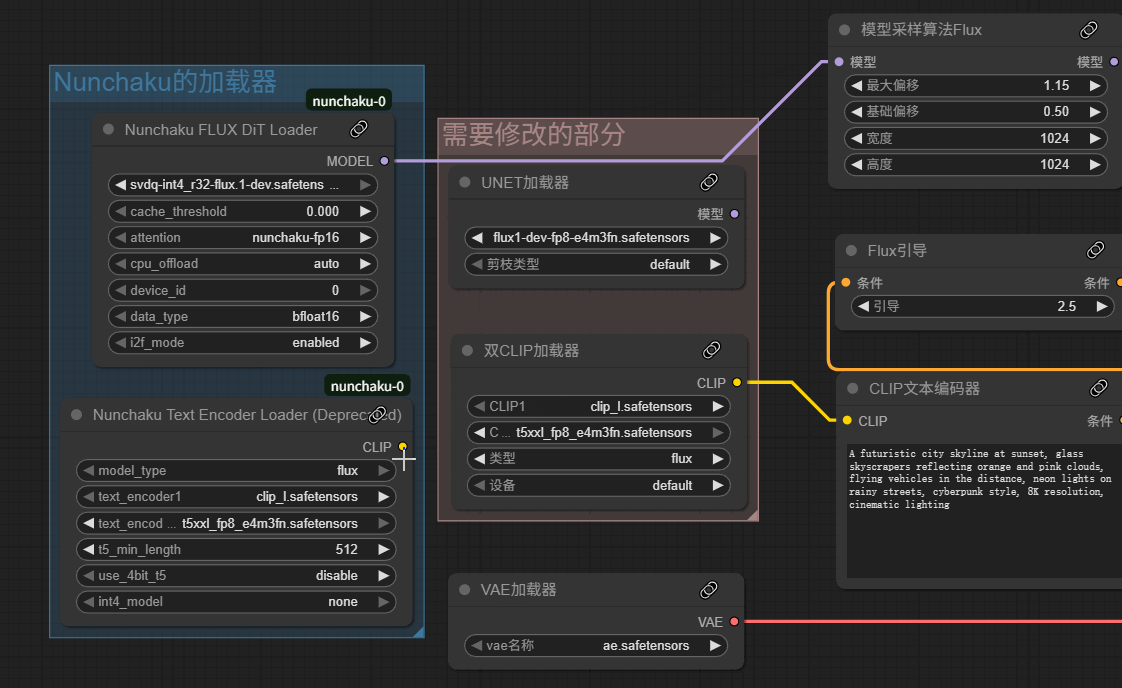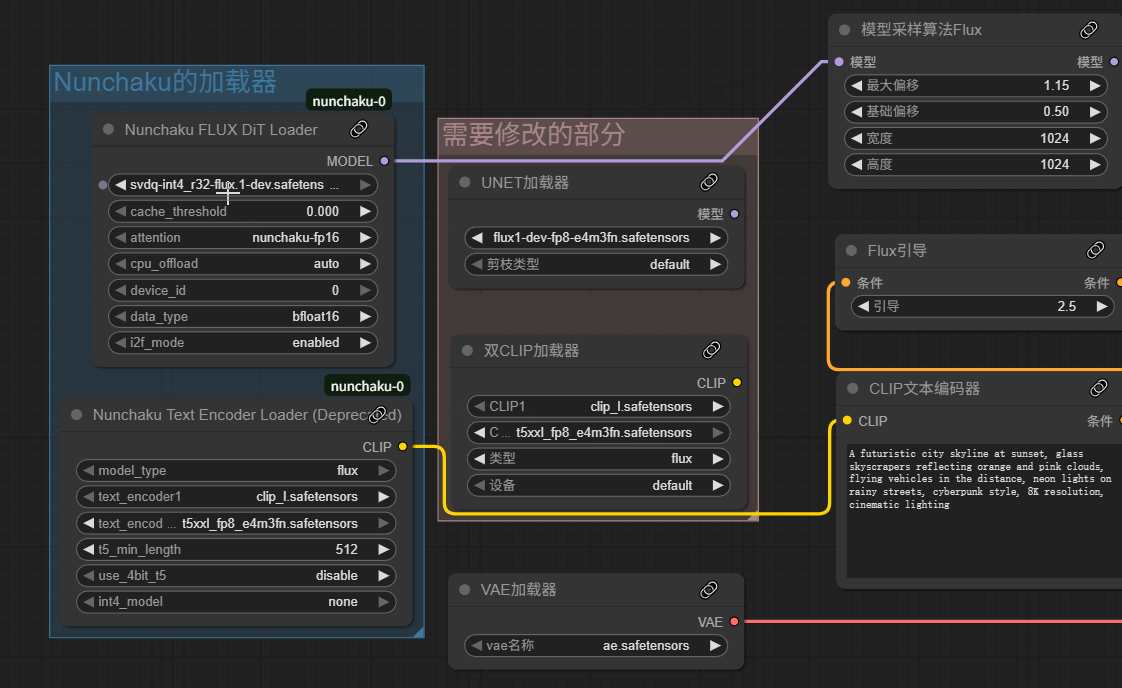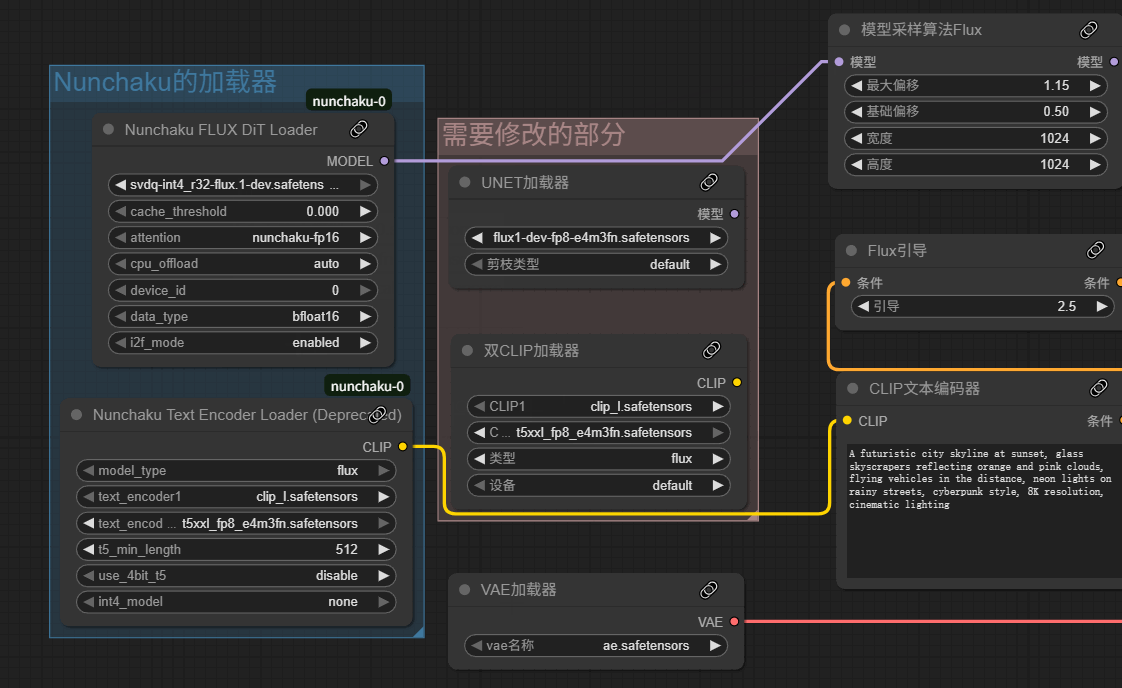
具体应用:
nunchaku的使用很简单,自己找或者搭建一个工作流,把主模型加载器和双Clip加载器改成nunchaku的就可以了
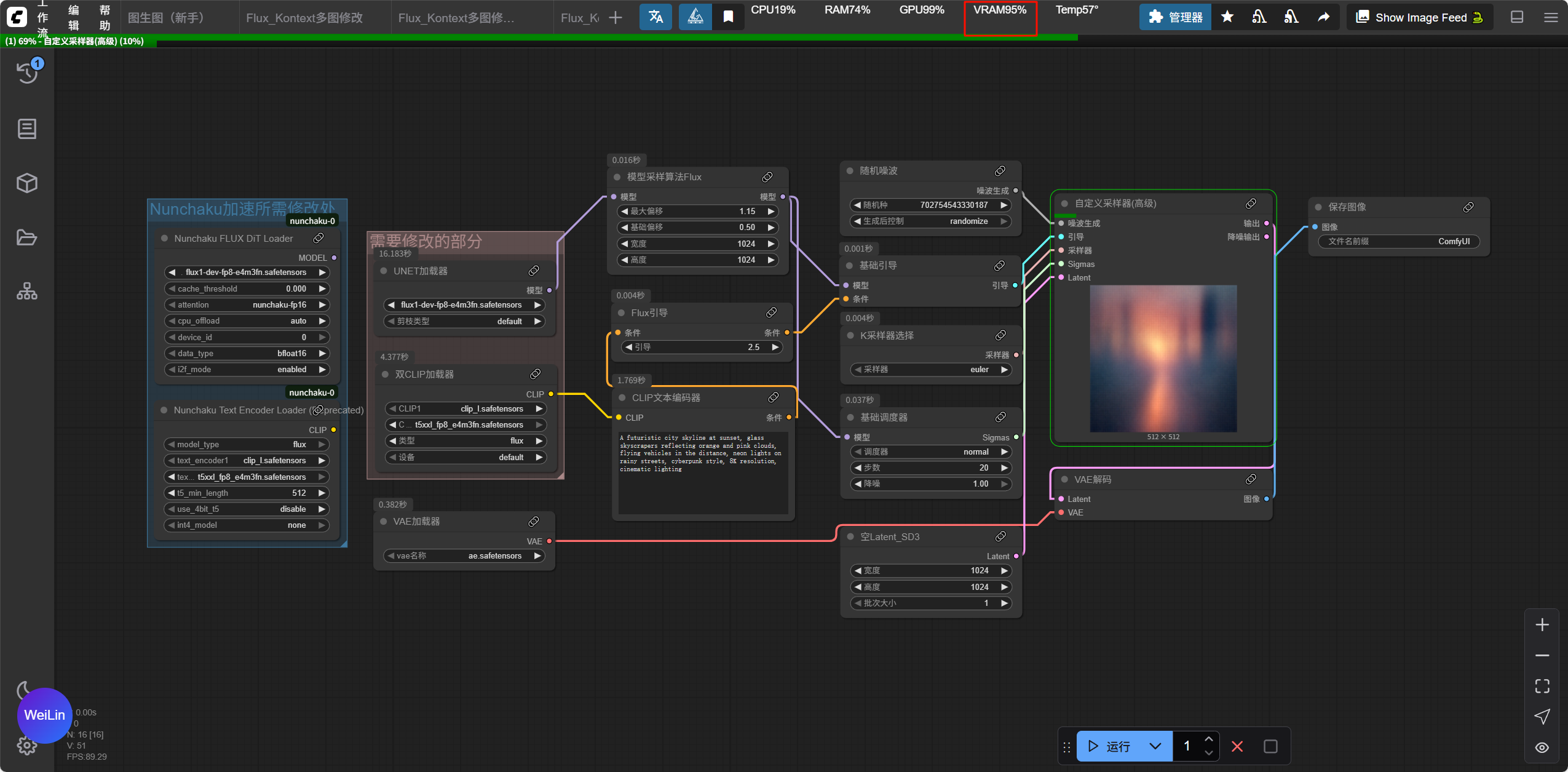
在未修改时,我的显存很明显已经爆了
注意:Nunchaku FLUX Dit加载器需要用我们刚刚下载的量化模型
更改后,显存占用小了近50%
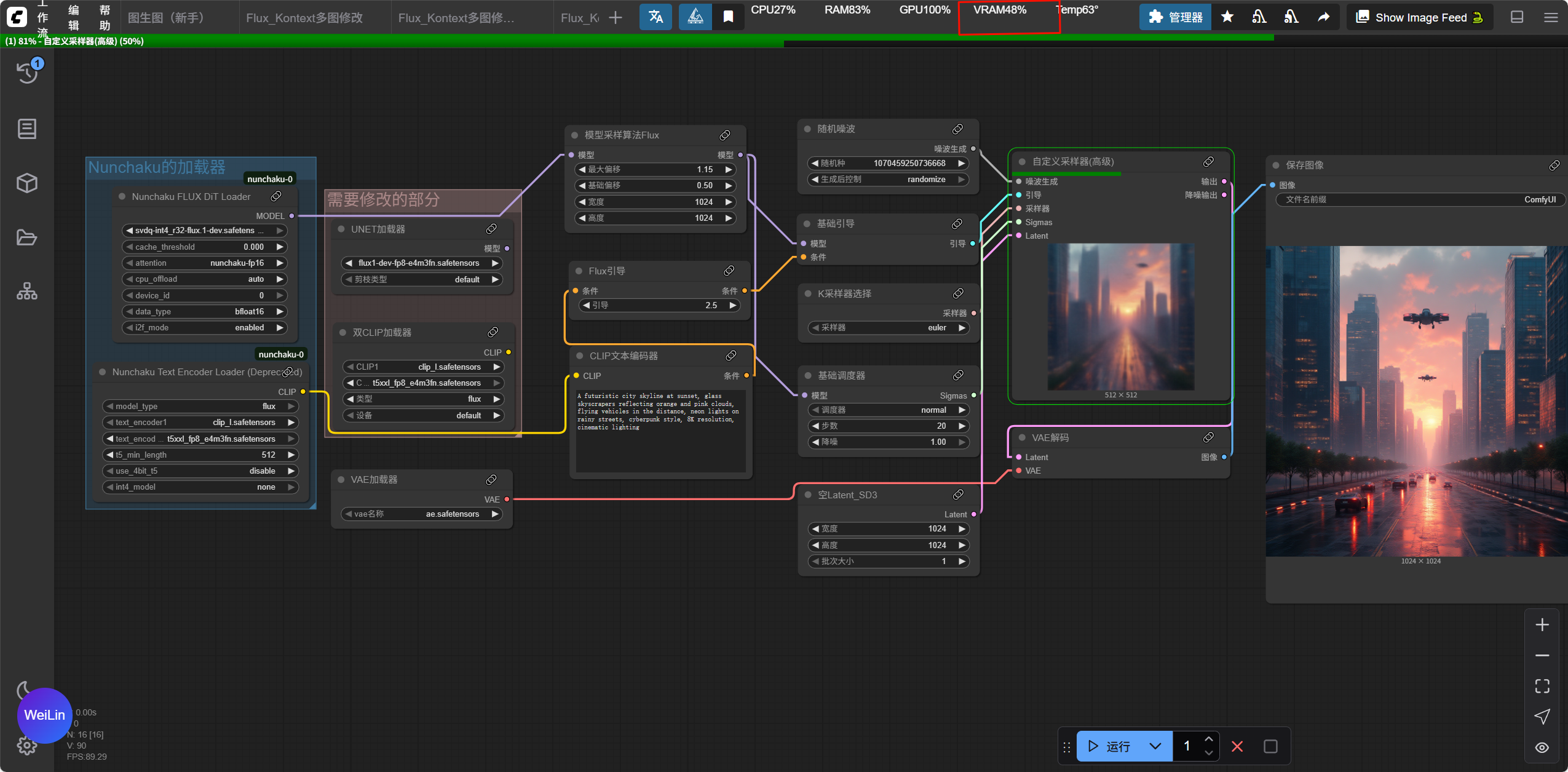
输出时间大幅减少,质量也没有什么损失



评论区