
在当今信息爆炸的时代,如何有效地组织和检索知识,提供准确的问答服务,是 intelligence 和 technology 领域面临的重大挑战。RAG(Retrieval Augmented Generation)技术,作为一种高效的 AI 问答方案,为我们提供了一种新的解决方案。本文将深入探讨 RAG 技术的工作原理和实现流程,帮助大家更好地理解和应用这一前沿技术。
RAG 技术概述
RAG 技术的全称是 Retrieval Augmented Generation,即 “检索增强生成”。它的核心思想是,当系统收到用户的问题时,首先从已有的知识库中检索与问题相关的信息,然后基于这些信息生成回答。这种方法的优势在于能够处理大量的文档数据,并且提供更准确、更快速的问答服务。
举例说明:
假如用户问:“量子计算的基本原理是什么?”
RAG 系统不会直接从记忆中生成答案,而是先检索知识库中与“量子计算”相关的权威资料(如教材片段、论文内容),再在此基础上进行内容生成。这样,回答既有来源支撑,也更准确。
关键优势:
可处理大量文档数据
提供更精准的答案
减少幻觉(hallucination)
适应性强,可更新知识库
RAG的基本流程
接下来,我会通过一张清晰的流程图,一步步解析RAG的核心工作流程
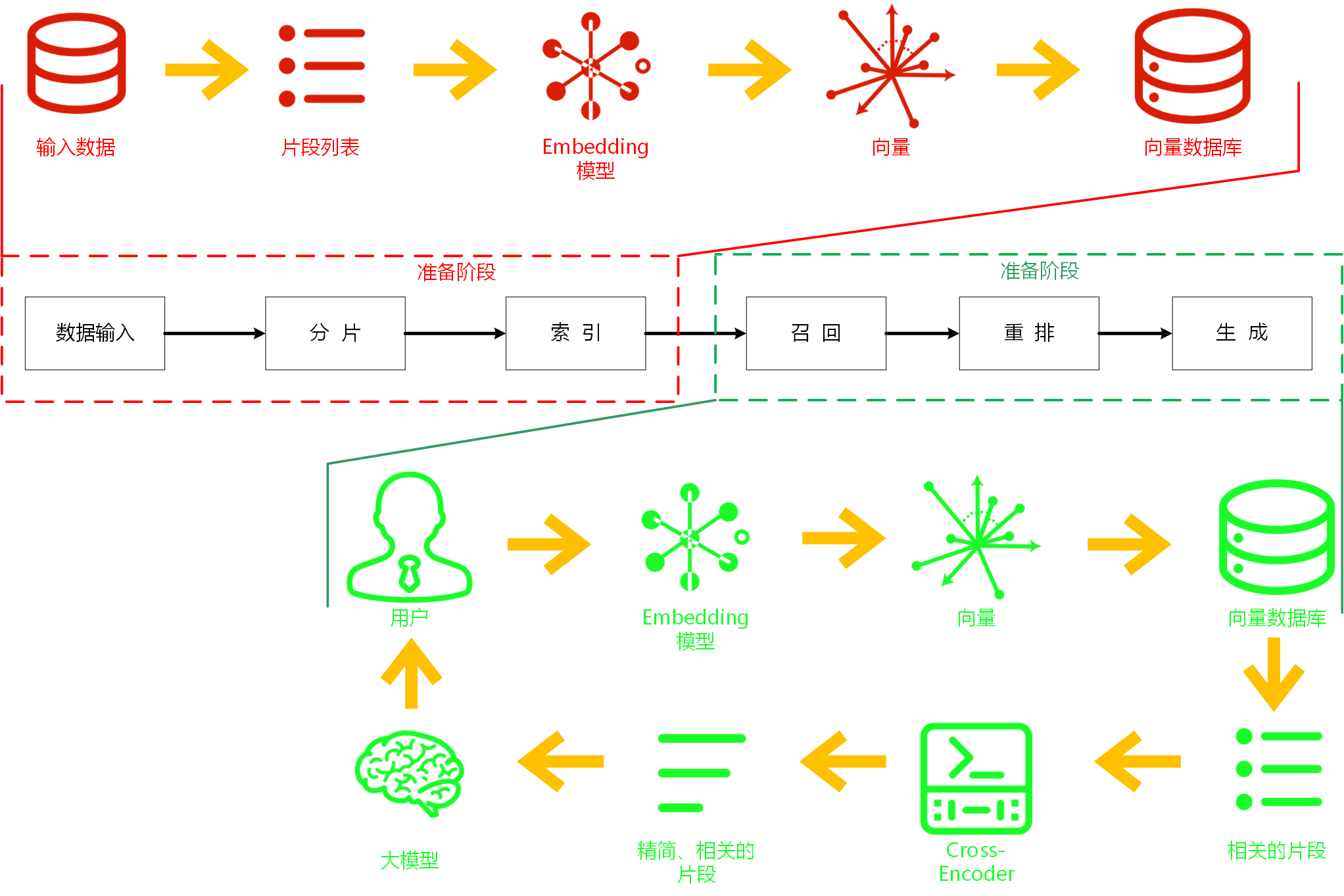
如图所示,整个RAG流程可以清晰地分为两个主要阶段:第一阶段(红色区域):回答前准备 - “养兵千日”和第二阶段(绿色区域):回答时的过程。
数据准备阶段:分片与索引
数据输入 (Data Input): 这通常是您希望模型掌握的核心知识来源,比如公司文档、产品手册、百科全书、甚至网页内容等原始信息。
分片 (Chunking): 原始文档通常太大,无法直接处理。这一步将它们切割成更小的、语义相对完整的片段 (Segment List)。比如按段落、小节或特定长度分割。
索引 (Indexing): 这是构建可查询知识库的关键:
先将文本片段通过 Embedding 模型 (Embedding Model) 进行处理。这个模型就像一台“翻译机”,将每个文本片段转化为高维空间中的一个数值向量 (Vector)。这些向量奇妙地捕捉了文本的语义信息(词句的意思和关系)。
所有生成的向量存储到向量数据库 (Vector Database) 中。这种数据库的专长就是高效存储和检索向量数据。
举例说明:
原始文档:人工智能教程,含 10 页内容
分片策略:每段为一个片段,共 120 个片段
优势:更精细的内容定位
回答阶段:召回、重排与生成
当用户提出问题,系统就开始运转这个“召回(查询)→重排→生成”的流程:
用户提问 (User): 流程的起点是用户的自然语言问题 (如 “什么是RAG的最佳实践?”)。
问题向量化 (Embedding Model): 用户的原始问题也要经过相同的 Embedding 模型处理,转化为一个代表问题语义的向量 (Vector)。
召回/检索 (Retrieval): 拿着用户问题的向量,系统在向量数据库 (Vector Database) 中进行搜索。数据库的核心功能是比较向量的相似度。它找出那些与用户问题向量最相似的、代表文档片段的向量,从而快速召回 (Retrieve) 一批与问题相关的文本片段。上一步到这一步通常叫“召回阶段”。
(可选) 重排 (Reranking - Cross-Encoder): 初始召回的相关片段可能数量众多且质量不一。为了提高最终结果精度,系统可以使用更复杂但计算量也更大的 Cross-Encoder 模型(图中未展示具体位置,但Cross-Encoder标签旁标注“相关的片段”表示其作用)对这些片段进行精细化排序 (Reranking)。Cross-Encoder 直接比较问题和片段之间的关系细节,挑选出最精简、最相关的那几个关键片段 (Relevant Fragments / Top-K Documents)。这是“重排阶段”。
生成 (Generation): 大语言模型 (Large Language Model) 正式登场!它将用户的原始问题 (Query) 和从上一步获得的最相关的文本片段 (Relevant Context) 一起作为输入。模型利用自身的理解能力和生成能力,融合上下文知识,输出最终的、信息丰富且相关的回复 (Response) 给用户。这步就是“生成阶段”。
RAG项目实操
现在,我来讲讲RAG用python怎么实现。
这里使用的工具是anaconda(管理环境)和jupyter notebook(分步骤运行比较直观,PyCharm+jupyter插件效果也是一样的),jupyter notebook不用另外下载,anaconda里会附带。
环境搭建
运行命令窗口cd到合适的路径,输入下面的命令行创建虚拟环境并激活虚拟环境:
conda create -n RAG python=3.12
conda activate RAG接下来,运行下面的命令行安装依赖:
pip install sentence_transformers chromadb google-genai python-dotenv sentence_transformers用于加载语义嵌入向量(Embeddings)模型和Cross-Encoder模型,生成句子、段落或图像的语义嵌入向量(Embeddings);
chromadb轻量级开源向量数据库,专为存储和检索高维嵌入向量设计,支持快速语义搜索与元数据管理;
接下来,要把jupyter notebook的内核更改为虚拟环境内核
先退出已经激活的虚拟环境
conda deactivate然后,输入下面的命令行添加插件
conda install nb_conda_kernels准备文档
这里我准备了《诡秘之主》小说的前5章,格式是md格式,如果用langchaim中的document_loaders可以识别pdf、docs格式。
编写代码
在命令行输入jupyter notebook,打开jupyter notebook;注意要在虚拟环境内打开!!!
接着点击new→Python[conda env:虚拟环境名]新建项目;

分片:
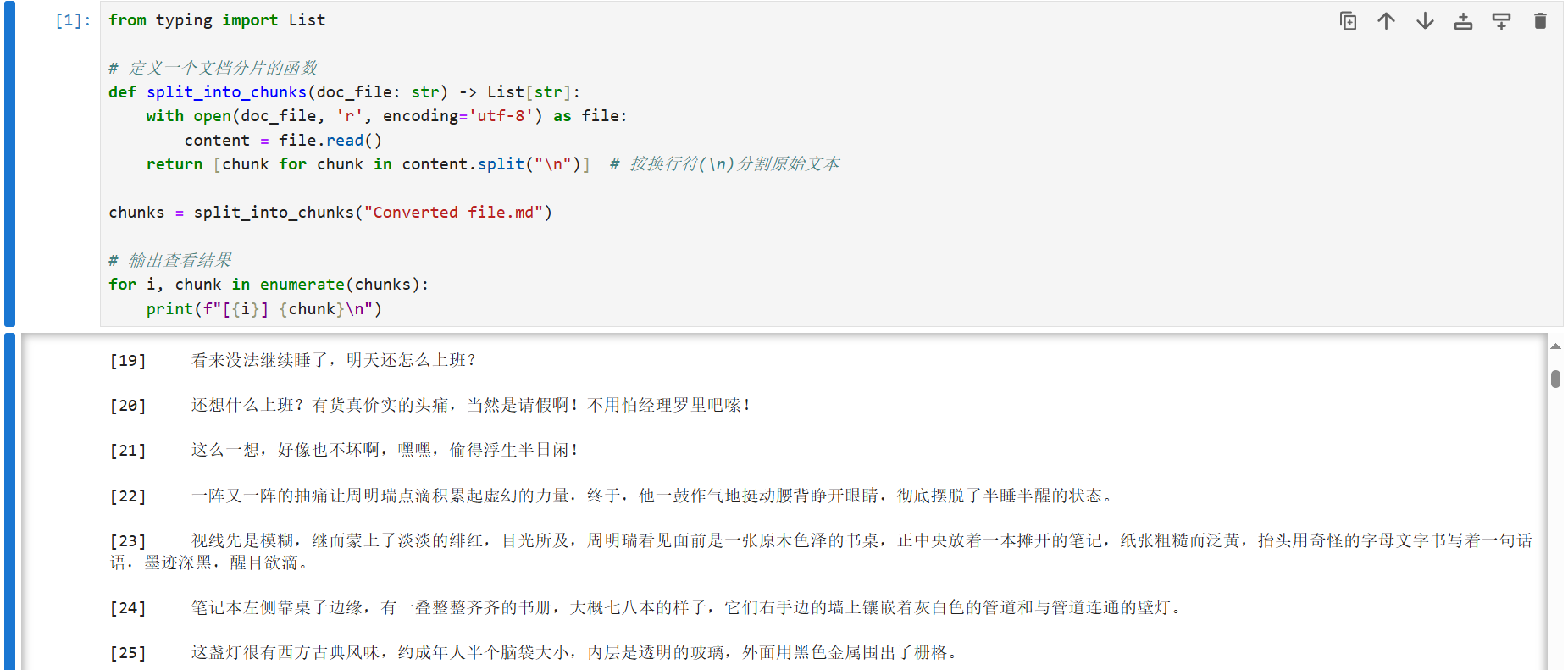
导入 List 这个对象用于标识函数返回结果的类型,然后我们创建一个函数用来处理分片的逻辑,函数名就叫做 split_into_chunks,其中的 chunk 就是片段的意思。
这个函数有一个参数叫做 doc_file,我们待会就把我们的文档名作为 doc_file 传入进来;这个函数的返回值是一个字符串列表(片段列表)。
在函数的内部,我们首先读取文件内容,把它放在 content 变量里面,然后按行来拆分,把这个 content 切分为多个 chunk,然后我们调用一下这个函数,并且循环遍历,拿到所有的片段,把片段的编号和对应的内容都打印出来,观察结果如何。
索引:
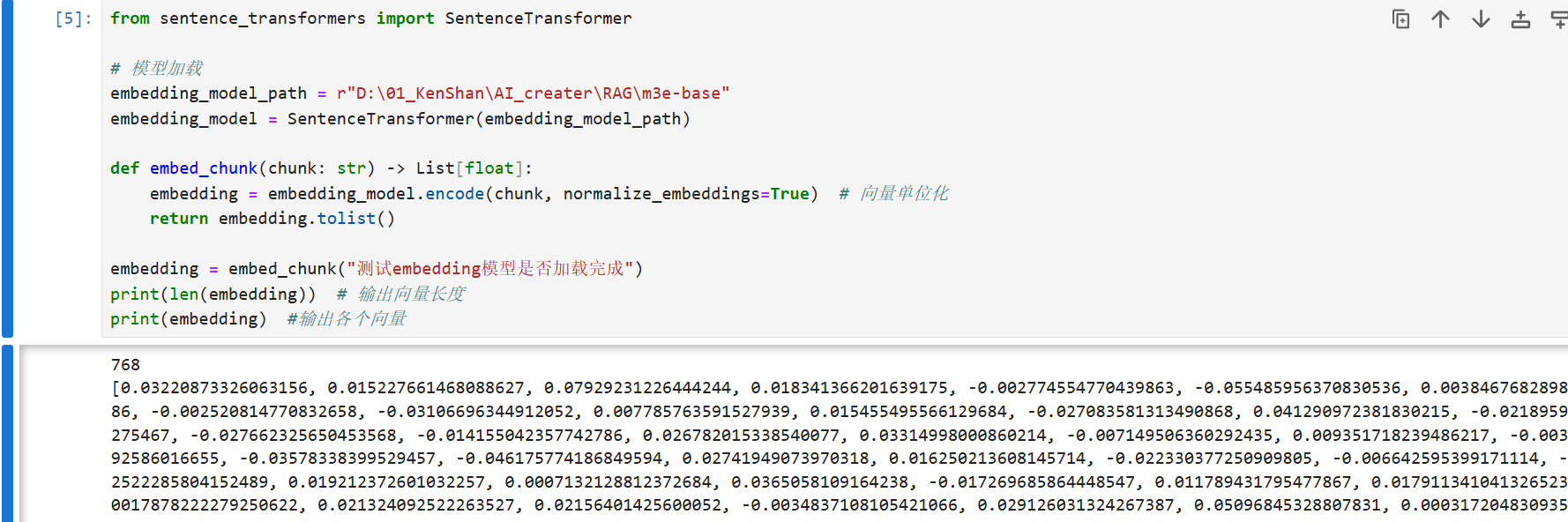
首先先引入 SentenceTransformer 对象,然后用它来加载一个 Embedding 模型,然后编写函数 embed_chunk获取片段的向量;
encode()方法:将文本输入(chunk)转换为固定维度的向量;
normalize_embeddings=True:对生成的向量进行 L2 归一化,使所有向量模长为 1,提升余弦相似度计算的准确性;
tolist()转换:将 NumPy 数组转为标准 Python 列表,便于序列化存储(如 JSON)或兼容非 NumPy 环境。
接下来,就把分片的List用循环一一调用函数 embed_chunk;
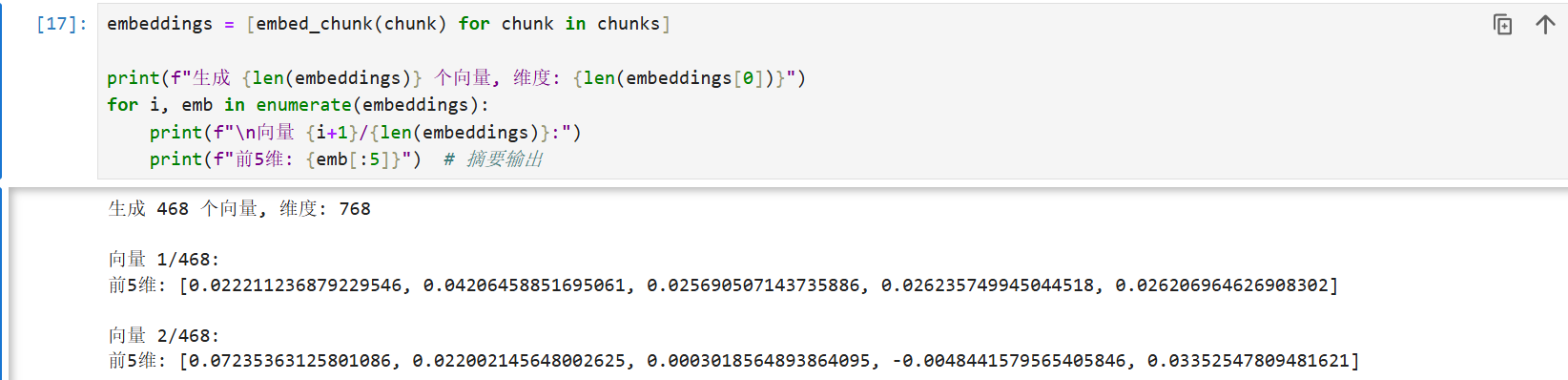
片段转化为向量后,就需要把这些向量存入到向量数据库;
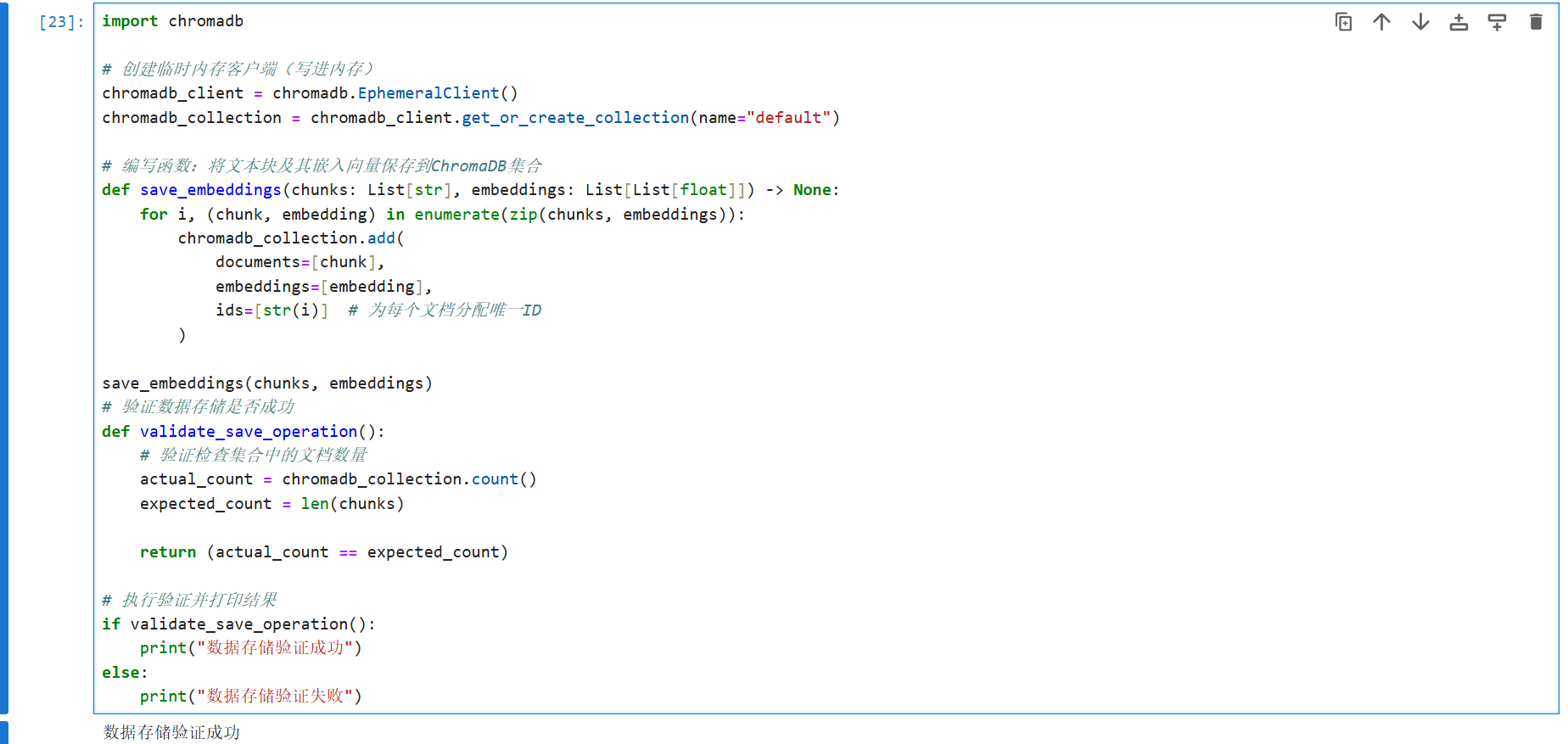
召回(检索):
编写检索召回的函数retrieve:用 embed_chunk 函数把用户问题转化为向量,查询与用户问题最为相似的前 k个结果,再把这些片段列表都返回回去。
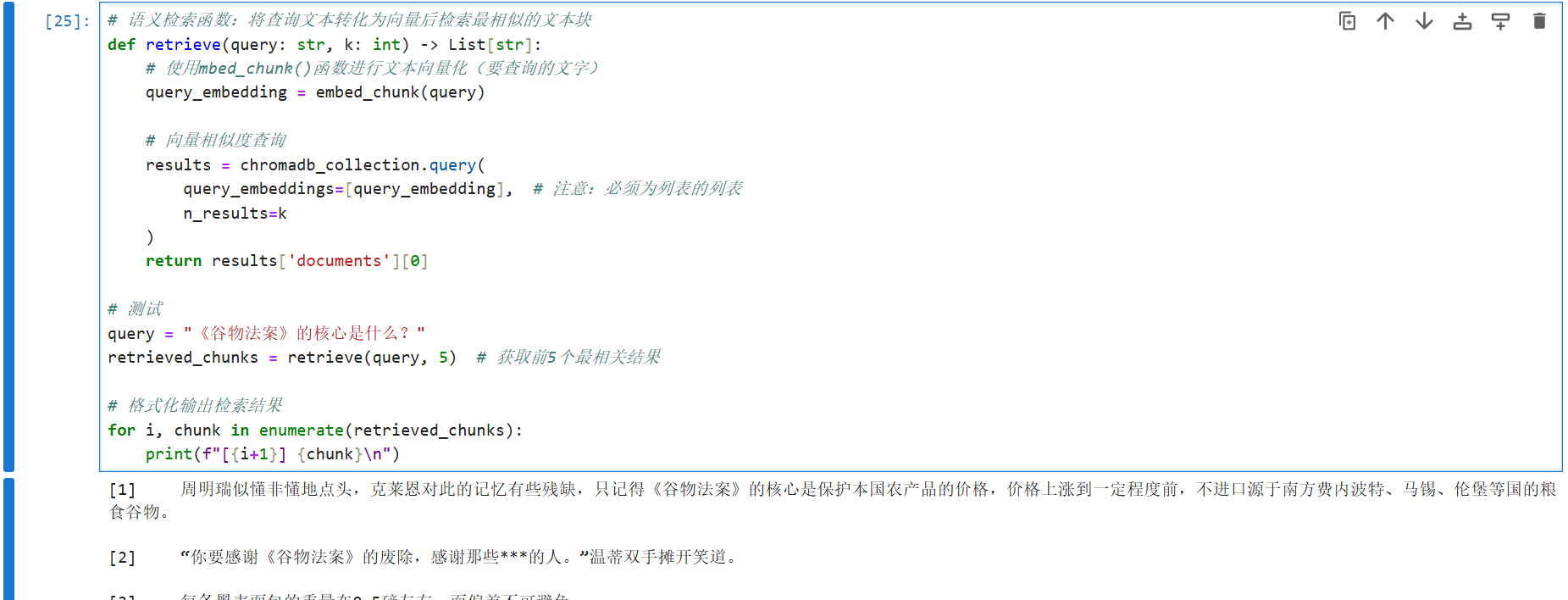
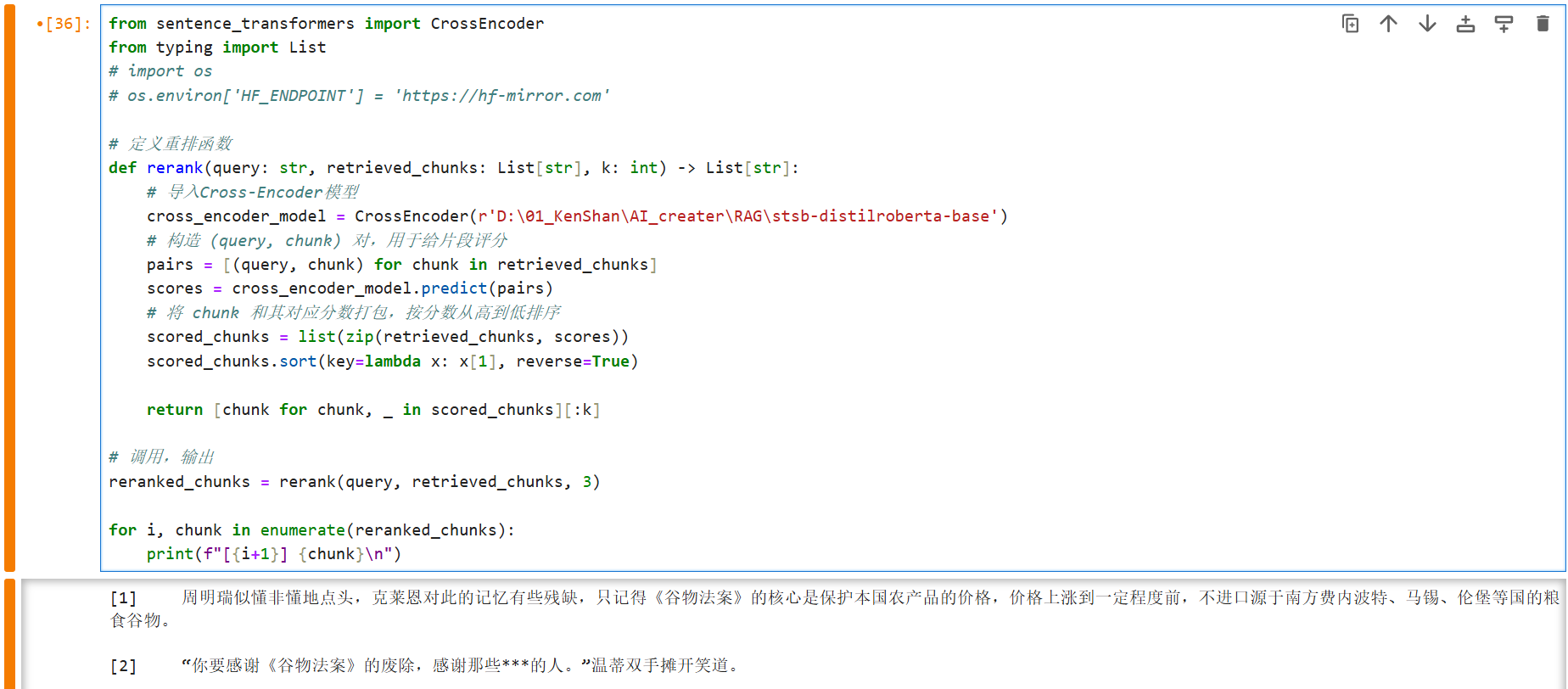
重排:
首先引入 sentence_transformers 的 CrossEncoder 包,然后写重排函数 rerank:函数内部,我们首先创建一个 cross-encoder 模型,然后把用户问题 query 的召回片段添加进一个列表,然后我们把这个列表发给 cross-encoder 模型,让它给每一个片段打分,分值就代表了用户问题与召回片段内容的相似程度,然后排序(从高到低);
生成:
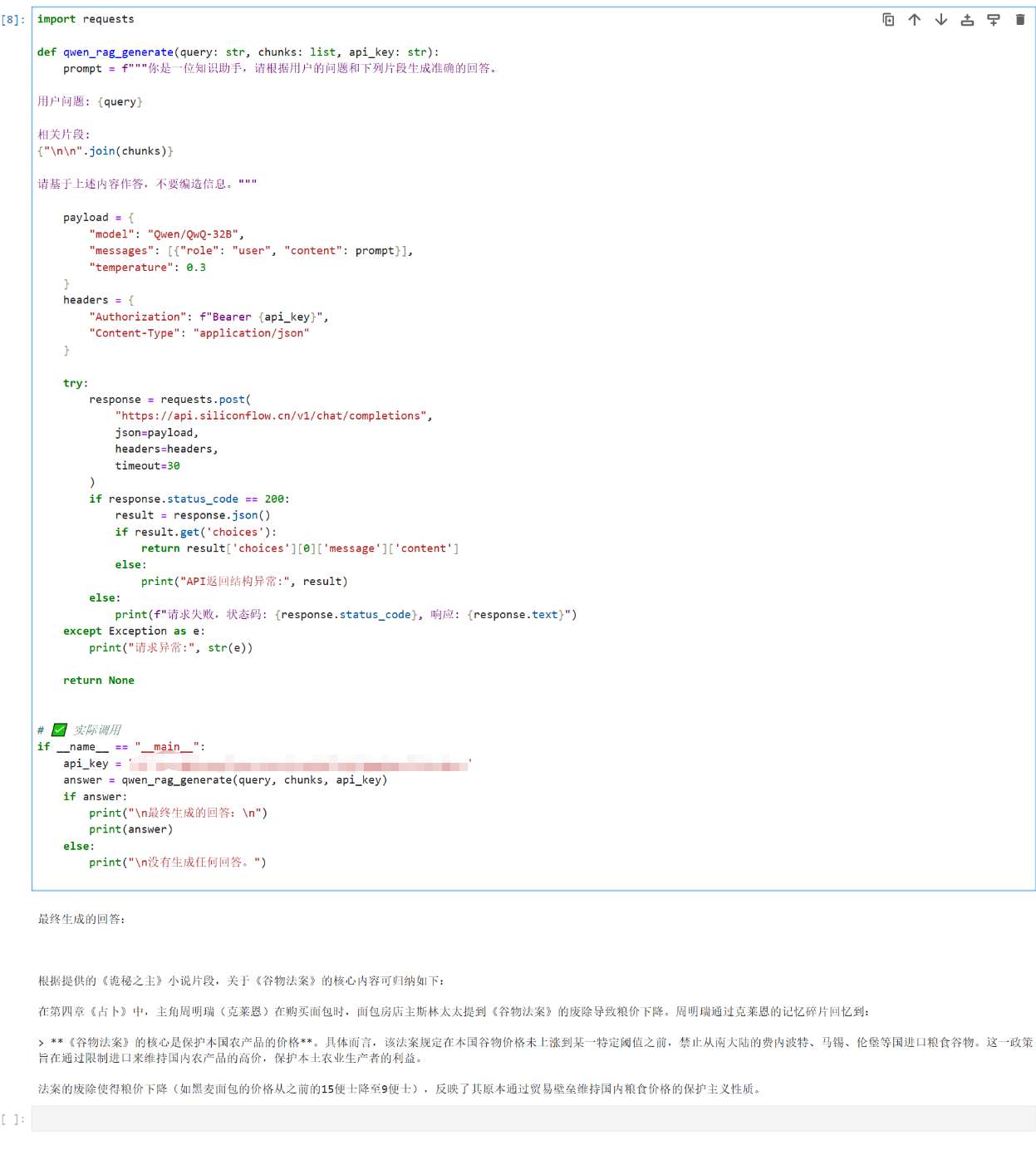
定义了一个函数 qwen_rag_generate,用于将用户的问题和相关文档片段(chunks)构造成提示词(prompt),通过调用 大语言模型(我这里是Qwen-32B),生成基于上下文的回答,并采用 HTTP POST 请求向 API 发送内容,设置合适的参数和请求头,接收并解析模型的回答结果



评论区