
前言
近年来,大语言模型(LLM)席卷了整个 AI 开发圈。它们预训练能力强、通用性高,但在具体业务中往往存在两个核心问题:
泛化太强,缺乏领域专精能力
部署复杂,接口调用不够灵活
为了解决这两个问题,我们可以通过 LoRA(Low-Rank Adaptation) 技术进行轻量级微调,提升模型在特定任务/行业场景下的表现;再结合 FastAPI 快速搭建 REST 接口,让模型更容易被接入其他系统或前端服务中。
技术介绍
下面是这篇博客所使用的技术
微调框架: LLama-Factory
算法: LoRA
基座模型:DeepSeek-R1-Distill-Qwen-1.5B
部署:FastAPI(一个基于 python 的 web 框架)
web后端调用:通过 HTTP 请求交互
1.LLama-Factory
LLama-Factory 是一个开源的大模型微调训练框架,专为 LLaMA 系列和兼容模型(如 Qwen、Baichuan、DeepSeek 等)提供支持。它基于 HuggingFace 的 transformers 和 peft 库构建,支持全参数微调和多种参数高效微调方法,同时还集成了多卡训练、多数据格式和开箱即用的训练/推理脚本。
特点包括:
简单易用:只需配置参数文件即可启动训练
高度模块化:支持自定义数据集格式和训练逻辑
多模型兼容:支持 HuggingFace 格式的大量开源模型
快速部署:配合 Gradio、Streamlit、FastAPI 可快速上线服务
补充微调常见实现框架
Llama-Factory:由国内北航开源的低代码大模型训练框架,可以实现零代码微调,简单易学,功能强大,且目前热度很高,建议新手从这个开始入门
transformers.Trainer:由 Hugging Face 提供的高层 API,适用于各种 NLP 任务的微调,提供标准化的训练流程和多种监控工具,适合需要更多定制化的场景,尤其在部署和生产环境中表现出色
DeepSpeed:由微软开发的开源深度学习优化库,适合大规模模型训练和分布式训练,在大模型预训练和资源密集型训练的时候用得比较多
2.LoRA算法
LoRA(低秩适配) 是一种参数高效微调技术,用于大语言模型(LLMs)等预训练模型的快速适配和微调。它的核心思想是:将模型中的部分权重矩阵分解为两个较小的低秩矩阵进行训练,从而冻结原始模型参数,只训练少量可调参数。
主要优势:
减少训练参数量,显著降低显存和计算资源消耗
提升微调效率,更适用于中小型GPU环境
支持多任务适配,通过多个LoRA权重组合切换任务风格
3.FastAPI
FastAPI 是一个基于 Python 的现代 Web 框架,专注于快速构建高性能 API 接口,特别适合用于部署 AI 模型推理服务。
核心特性:
使用 Python 类型注解,自动生成 Swagger 文档和接口校验
基于
Starlette和Pydantic,性能媲美 Node.js 和 Go天然支持异步,适合高并发应用
可与模型框架(如 PyTorch、Transformers)无缝集成
FastAPI 常用于将训练好的模型部署为 HTTP API 服务,配合前端或第三方应用调用。
项目实操
考虑到有的人可能会因为硬件条件不足而去租实例,所以这部分内容我会把两个环境都来介绍。
连接云服务器:
如果不需要租云服务直接到下一步“LLaMA-Factory 安装部署”
具体步骤如下:
1.在云平台租服务器;
2.按下面我给的链接,打开VS Code下载插件Visual Studio Remote远程连接到你租用的服务器;
部署llama-factory:
项目地址:https://github.com/hiyouga/LLaMA-Factory
1.cd到合适的文件路径,克隆llama-factory项目
git clone https://github.com/hiyouga/LLaMA-Factory.git2.创建 anaconda 虚拟环境,根据官网环境要求选择Python版本(我这里用的是python 3.10)
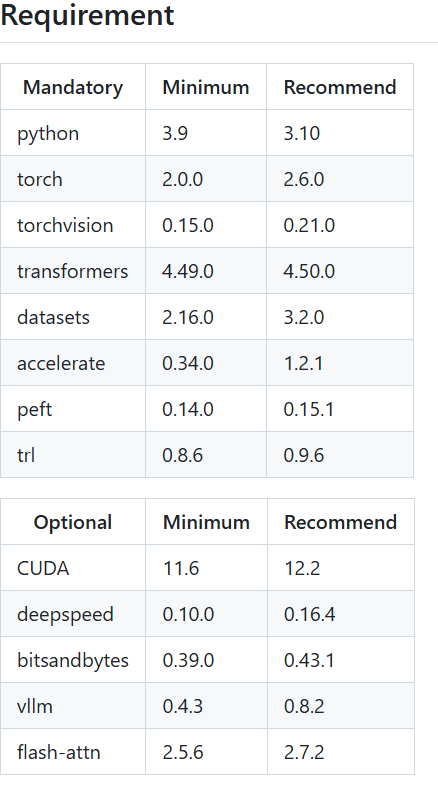 打开Anaconda Prompt,输入命令行,按y回车
打开Anaconda Prompt,输入命令行,按y回车
conda create -n llama-factory python=3.10验证并激活虚拟环境
#依次输入,第一行查看是否有新建的虚拟环境,第二行激活虚拟环境
conda env list
conda activate llama-factory3.在虚拟环境中安装 LLaMA Factory 相关依赖
pip install -e ".[torch,metrics]"注意:上面这个命令默认是下载最新的pytorch,而且不下cuda,需要再此输入下述命令【pytorch版本和cuda版本按要求即可】
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu1214.检验是否安装成功
llamafactory-cli version5.启动llama-factory的web端
llamafactory-cli webui6.配置端口转发
如果你是使用云端的实例,则需要进行端口转发
https://vscode.github.net.cn/docs/editor/port-forwarding
从Hugging Face下载底模:
如何从Hugging Face上下载模型,可以参考这篇文章:https://zhuanlan.zhihu.com/p/663712983
不过llama-factory已经可以从网络上下载模型了,这一步可以跳过,不过需要本地部署的话,还是要做的。
在网站搜索,选择合适的模型,点击进入;

点击下图所指处
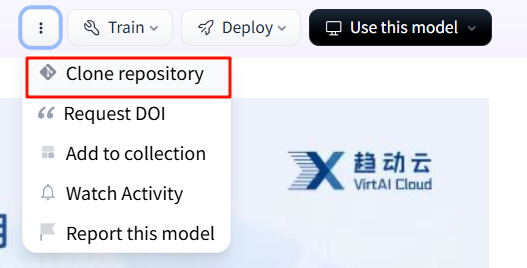
我推荐两种方式下载模型:
1.git:确保电脑有git,依次输入下面的命令:
git clone https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B2.hf CLI:依次输入下面的命令:
pip install -U "huggingface_hub[cli]
hf download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B做完上述工作后,llama-factory页面才会显示你的数据集。
准备用于训练的数据集:
微调数据集一般是JSON格式的,可以使用多种风格
具体可以参考我之前写的文章“微调数据集该如何准备”,链接如下:
http://www.hweiblog.xyz/archives/wei-diao-shu-ju-ji-gai-ru-he-zhun-bei
准备完数据集后,要把数据集放在合适的位置并修改配置文件
数据集要放在...\LLaMA-Factory\data
并且修改...\LLaMA-Factory\data\dataset_info.json,新增文件指引,示例如下:
#注意下面的xxx是你的数据集的名字
"xxx": {
"file_name": "xxx.json"
},在Llama Factory设置微调参数,开始微调:
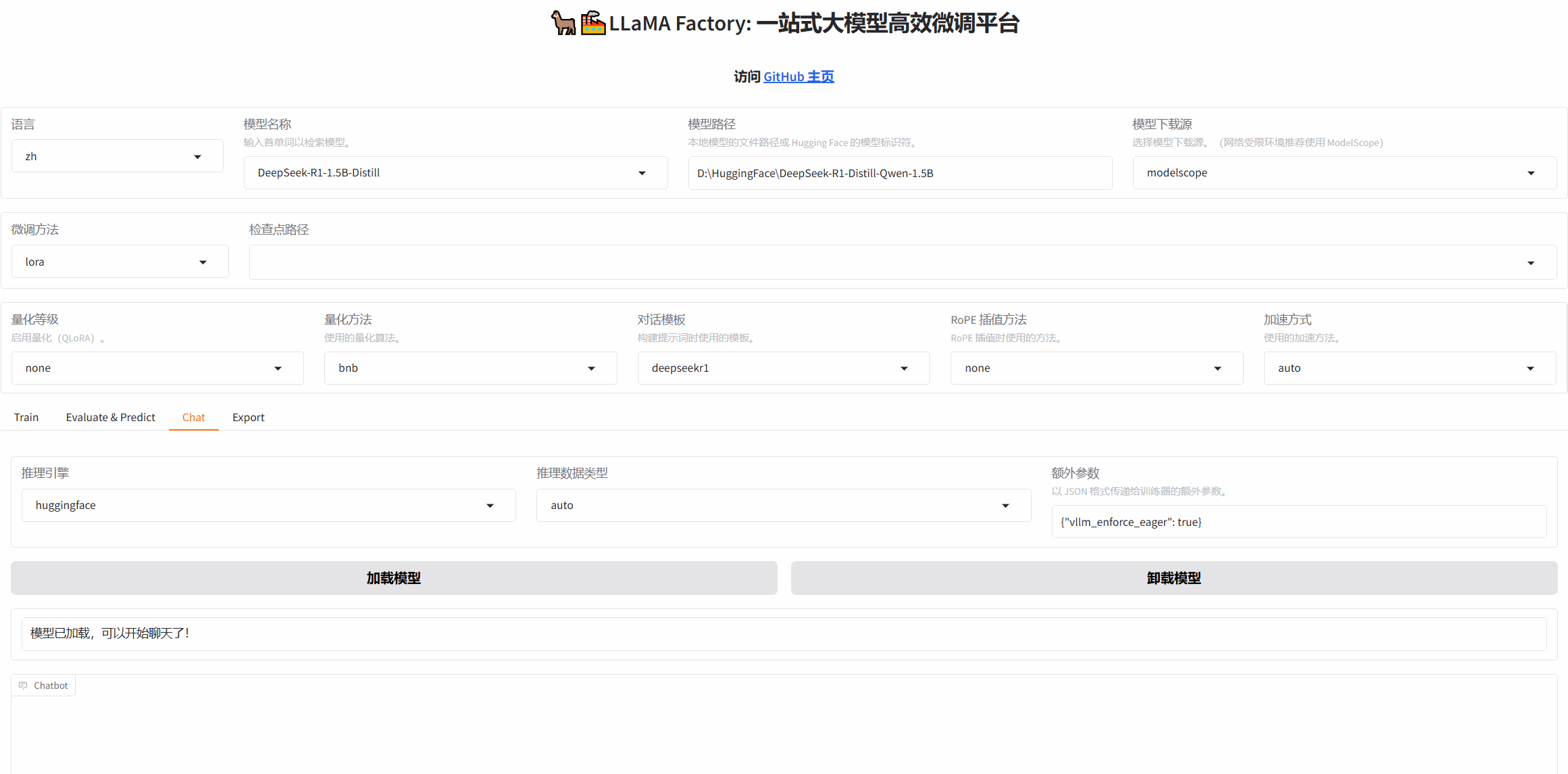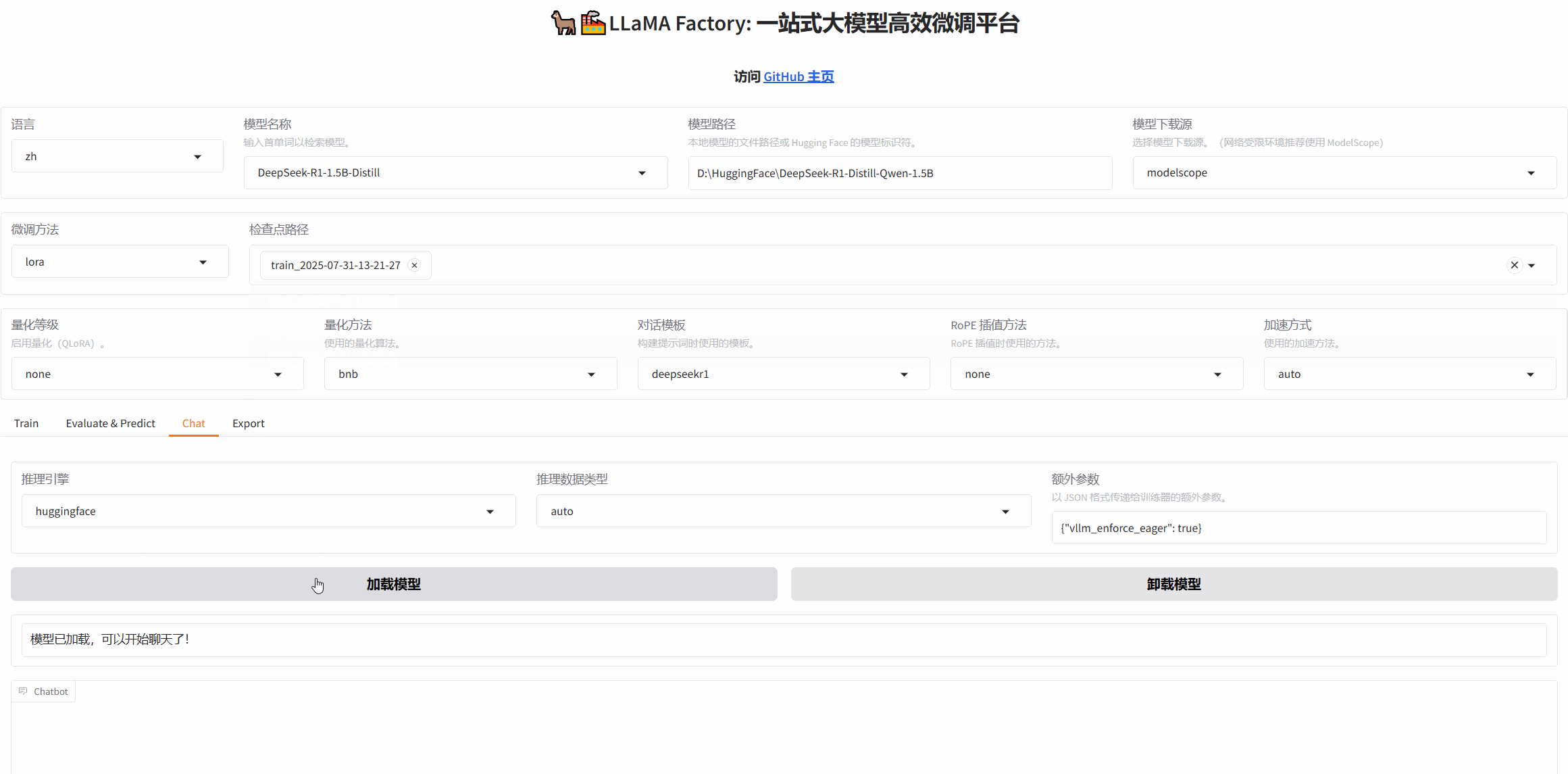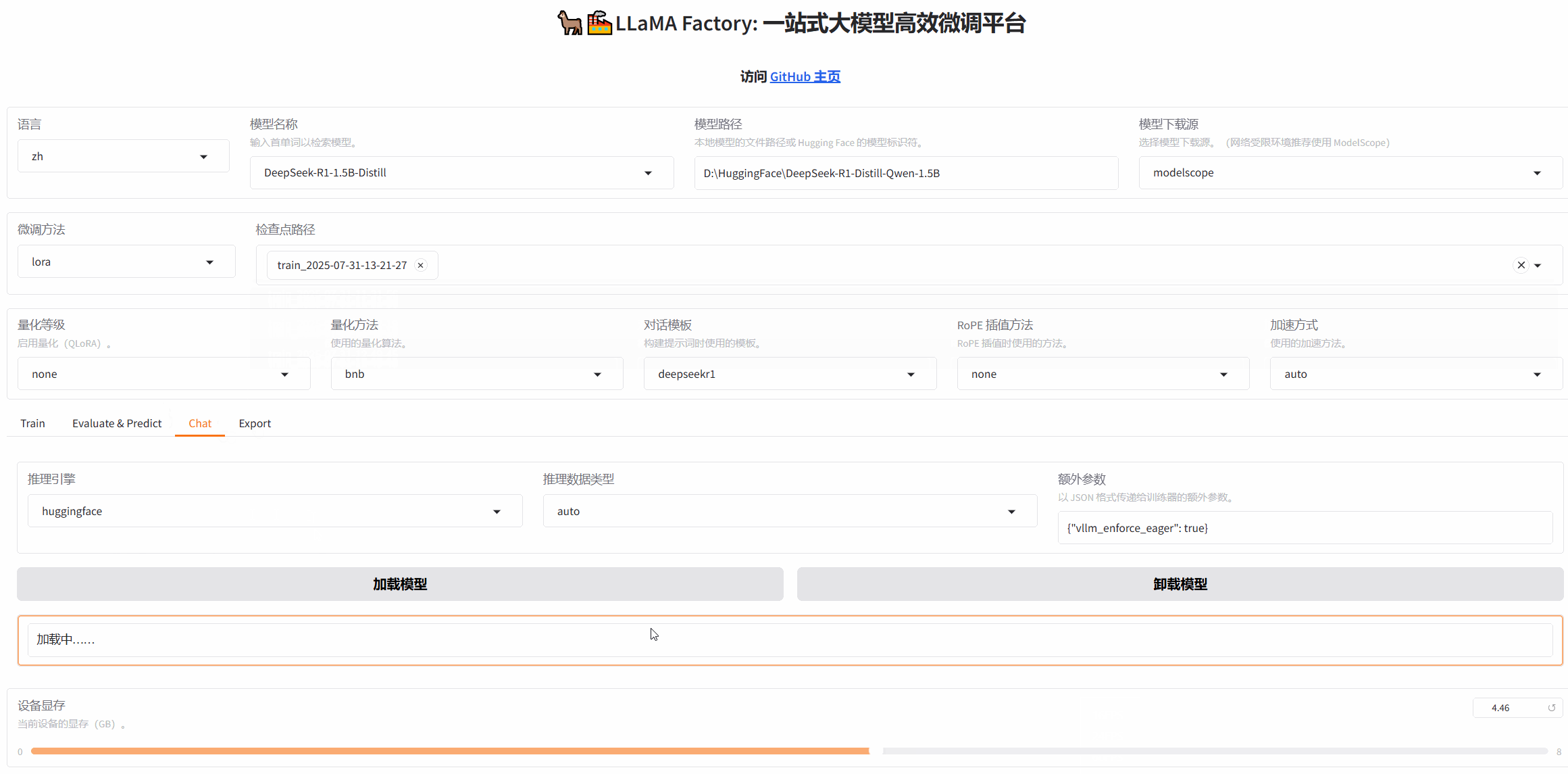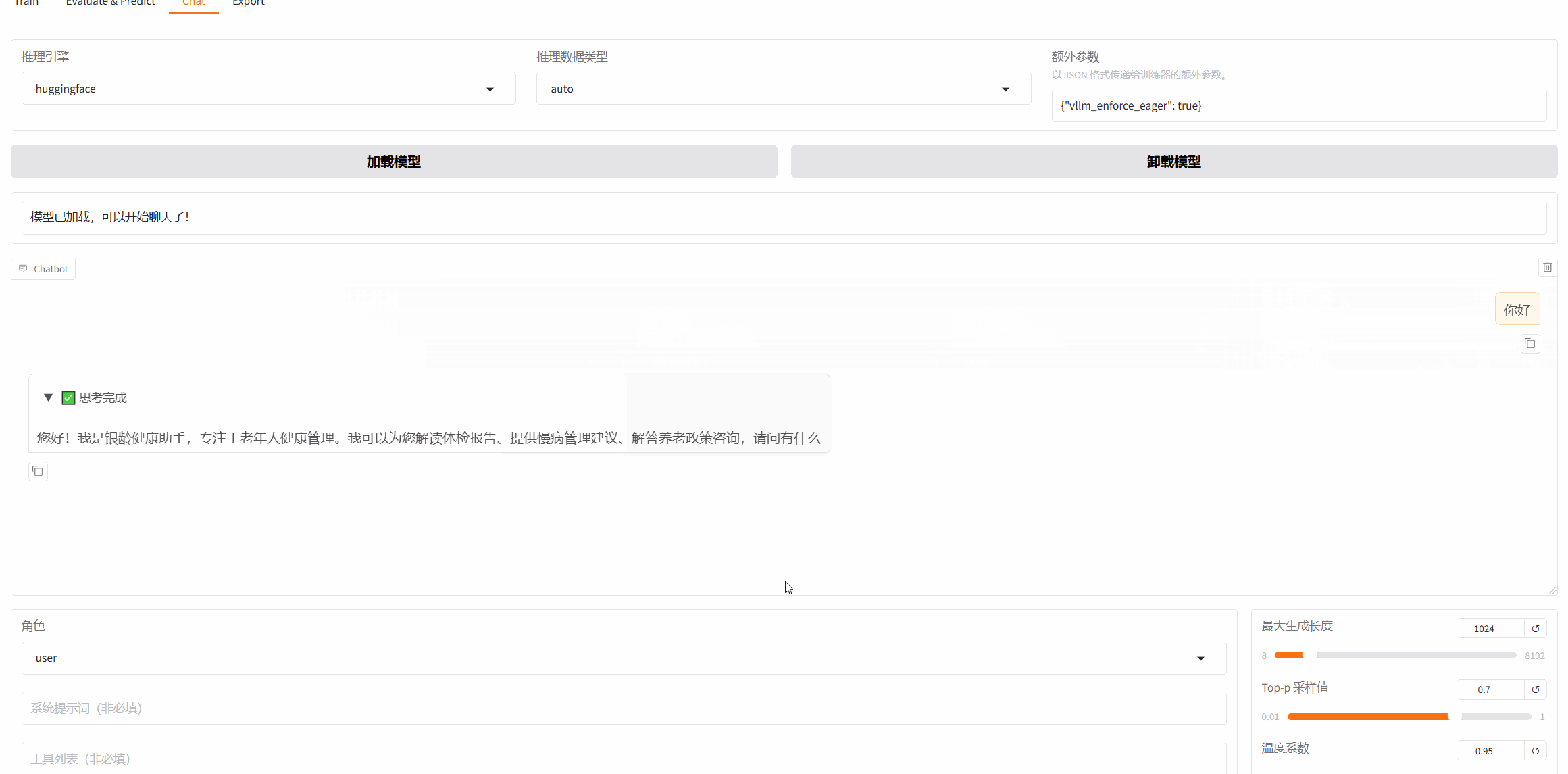
载入模型:
首先点击Chat目录,加载模型【有两种方式一种是用在线的模型标识符,另一种是用本地路径】,点击加载模型,网站会提示是否成功;
使用模型标识符:

使用本地路径:

可以下划到对话窗口,输入语句验证模型是否加载成功;
调整训练参数:
点击Train,加载数据集,调整参数开始训练;
注意要先点击保存训练参数→载入训练参数;
Llama-factory中的具体参数可以看下面这篇文章:
开始训练:
有两种训练方式,一种是在llama-factory页面上点击开始:

另一种是使用命令行来开始训练:
点击预览命令,然后复制下面的命令到终端执行:
PS:实践中推荐用命令将训练任务放到后台执行,这样即使关闭终端任务也会继续运行。同时将日志重定向到文件中保存下来

训练完成后,可以看到损失的图表;

评估微调模型效果:
首先是看训练完成后的损失曲线的变化,观察最终损失。
点击Chat→在检查点栏选择训练好模型→重新加载模型→下滑输入观察
让我们来看看微调前后的结果对比,微调前:

微调后:

若微调效果不理想,你可以:
使用更强的预训练模型
增加数据量
优化数据质量(数据清洗、数据增强等,可学习相关论文如何实现)
调整训练参数,如学习率、训练轮数、优化器、批次大小等等
导出模型:
点击Export→选auto→填写导出路径→点开始导出

导出成功

模型部署并用FastAPI调用接口:
参考文章:https://blog.csdn.net/my_name_is_learn/article/details/109819127
1. 创建新的 conda 虚拟环境用于部署模型;
conda create -n Fastapi python=3.10
conda activate Fastapi下载依赖
conda install -c conda-forge fastapi uvicorn transformers pytorch
pip install safetensors sentencepiece protobuf2. 通过 FastAPI 部署模型并暴露 HTTP 接口
首先,新建个文件夹app存放项目文件;
在文件里面创建 main.py 文件,作为启动应用的入口;
参考:https://blog.csdn.net/qq_39172059/article/details/136518206
import torch
import uvicorn
from fastapi import FastAPI, Request, Body
from fastapi.exceptions import RequestValidationError
from fastapi.responses import JSONResponse
from transformers import AutoModelForCausalLM, AutoTokenizer
app = FastAPI()
# 模型路径(请根据实际路径修改)
model_path = "D:\\01_KenShan\\AI_creater\\model_factory\\output"
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(model_path)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModelForCausalLM.from_pretrained(model_path).to(device)
# 捕获参数验证错误
@app.exception_handler(RequestValidationError)
async def request_validation_exception_handler(request: Request, exc: RequestValidationError):
print(f"参数不对: {request.method} {request.url}")
return JSONResponse(status_code=400, content={"code": 400, "message": exc.errors()})
# POST 接口
@app.post("/generate")
async def generate_text(prompt: str = Body(..., media_type="text/plain")):
inputs = tokenizer(prompt, return_tensors="pt").to(device)
outputs = model.generate(
inputs["input_ids"],
max_length=150,
do_sample=True,
top_p=0.95,
top_k=50,
temperature=0.7,
pad_token_id=tokenizer.eos_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
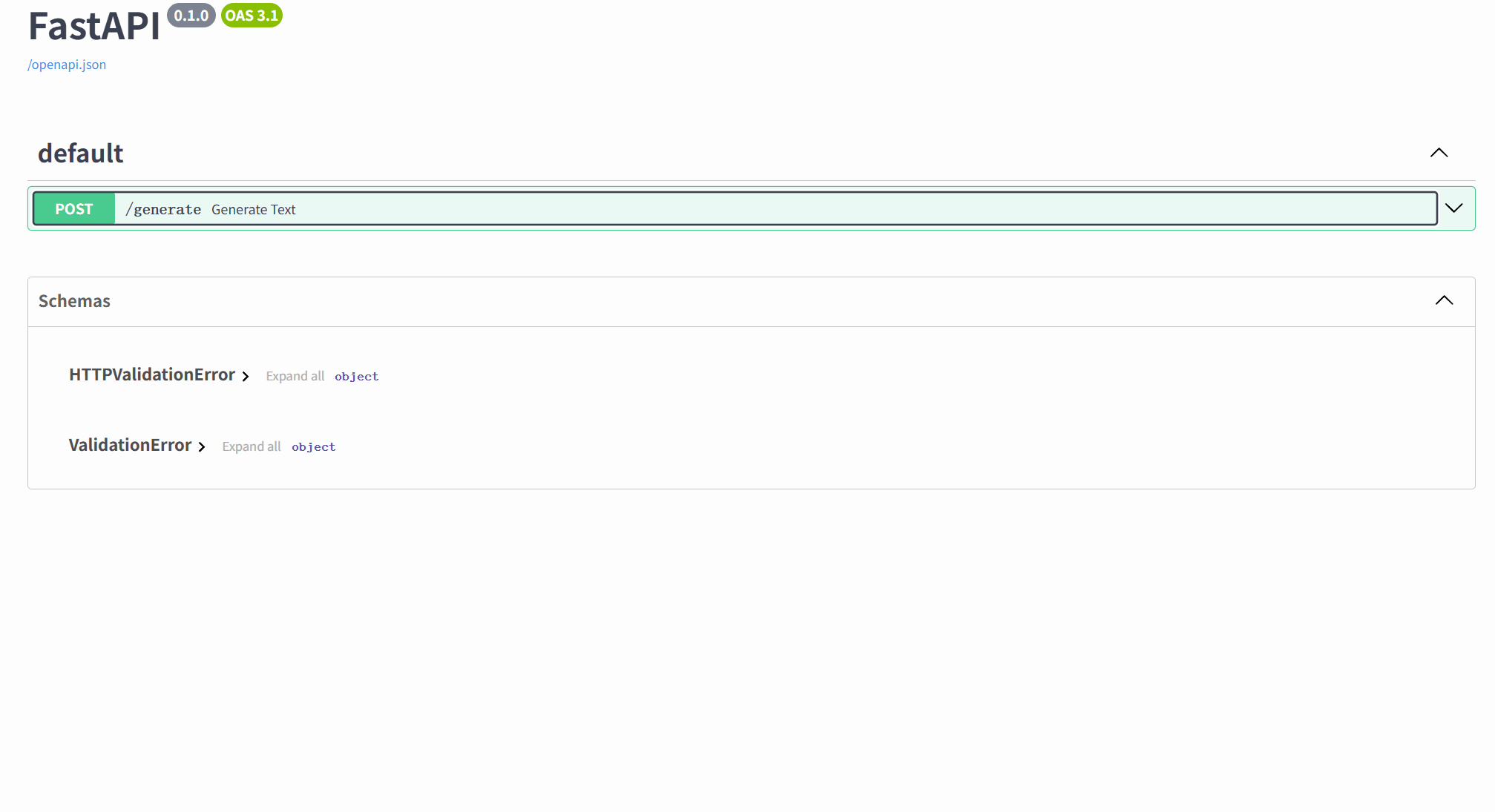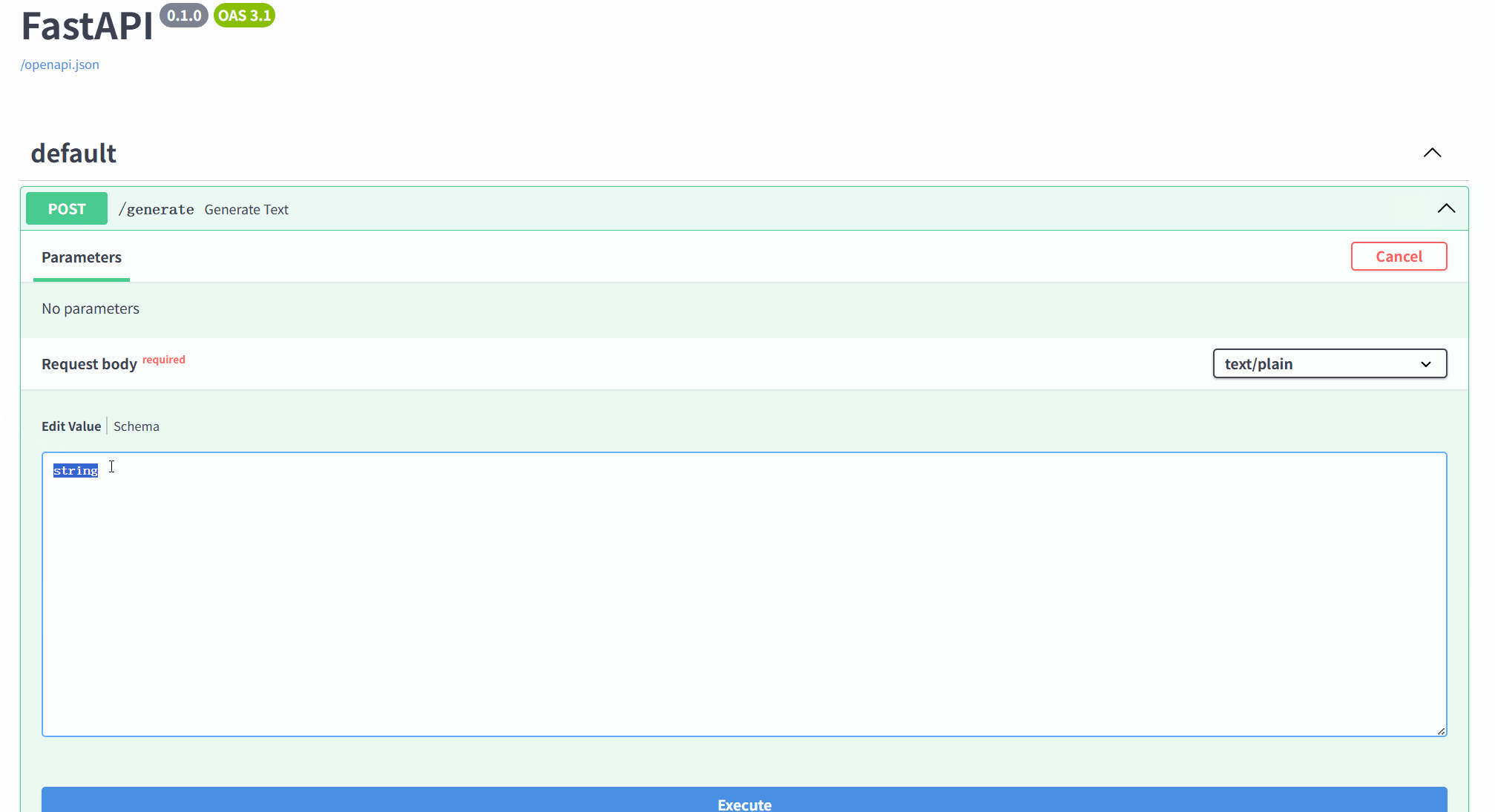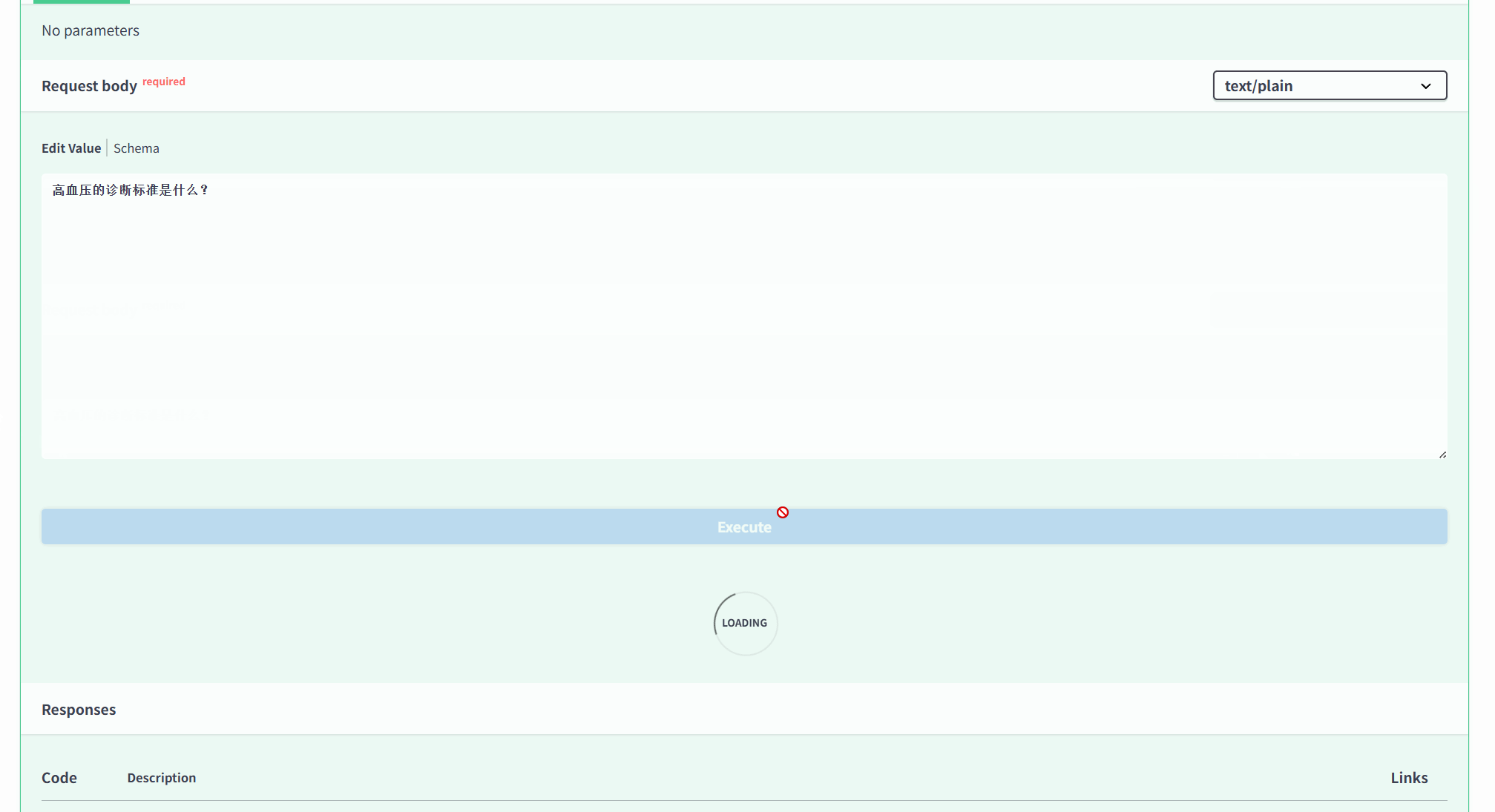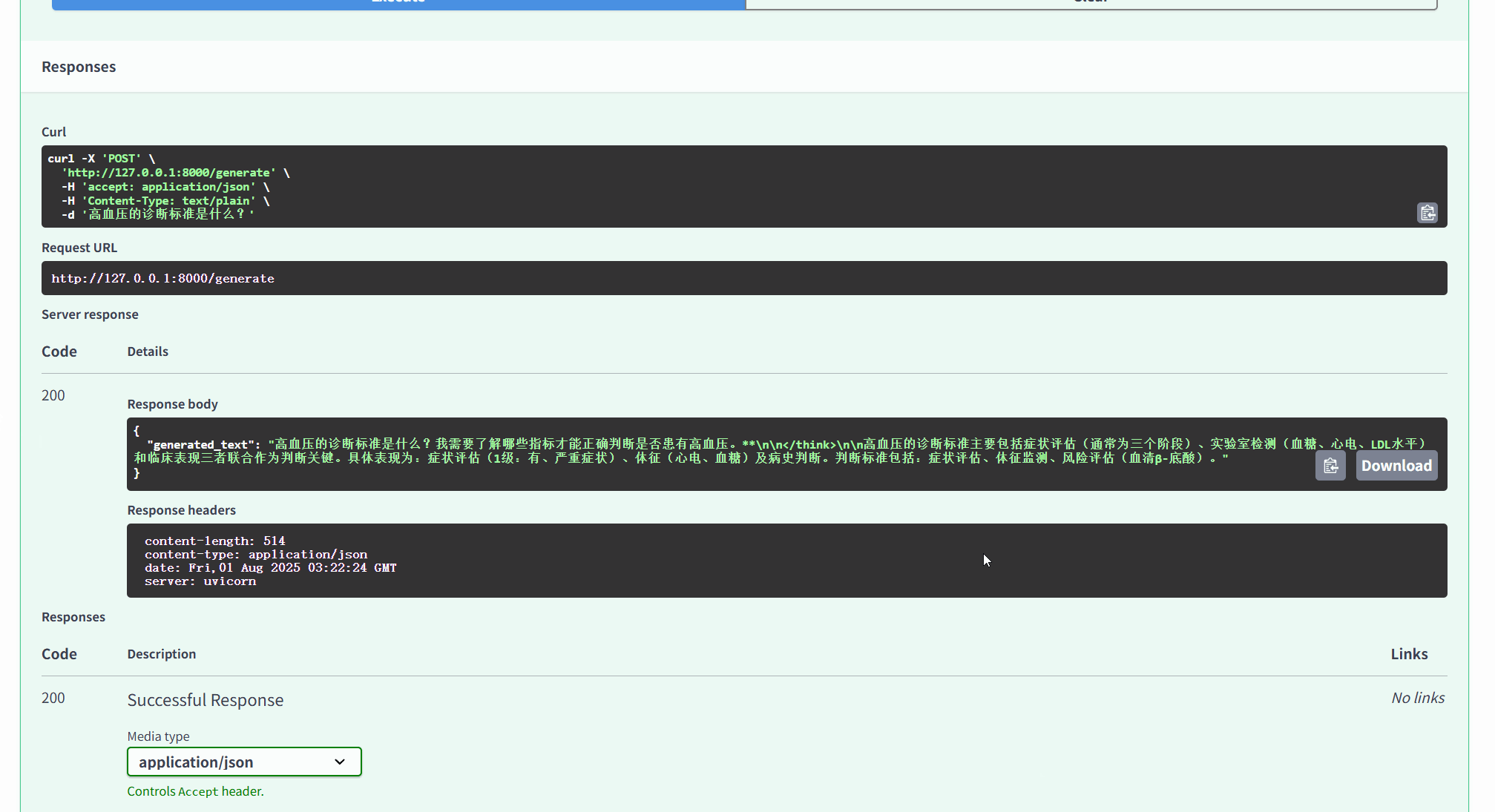
return {"generated_text": generated_text}
if __name__ == "__main__":
uvicorn.run(app="main:app", host="127.0.0.1", port=8000, reload=True)在终端输入命令行,观察是否报错
输入:
uvicorn main:app --reload
输出:
INFO: Will watch for changes in these directories: ['D:\\01_KenShan\\AI_creater\\model_factory\\app']
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [29432] using WatchFiles
INFO: Started server process [31316]
INFO: Waiting for application startup.
INFO: Application startup complete. 然后在浏览器输出http://127.0.0.1:8000/docs,注意:你们的本机地址可能不是http://127.0.0.1:8000,要看自己输出的是什么;
打开的页面如下,接着按照下面进行操作:点POST→Try it out→输入提示词→execute;

评论区