
MySQL安装
打开上面的网站(科学上网)
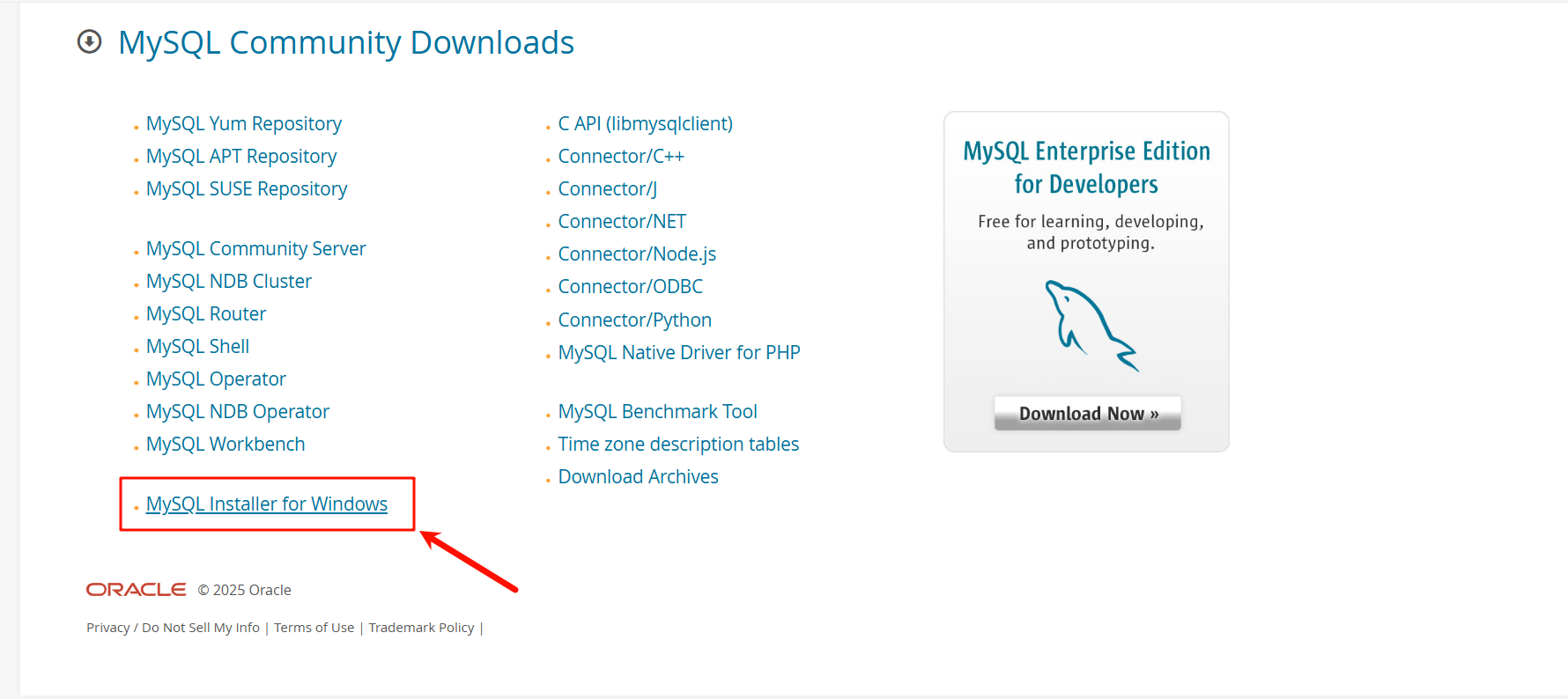
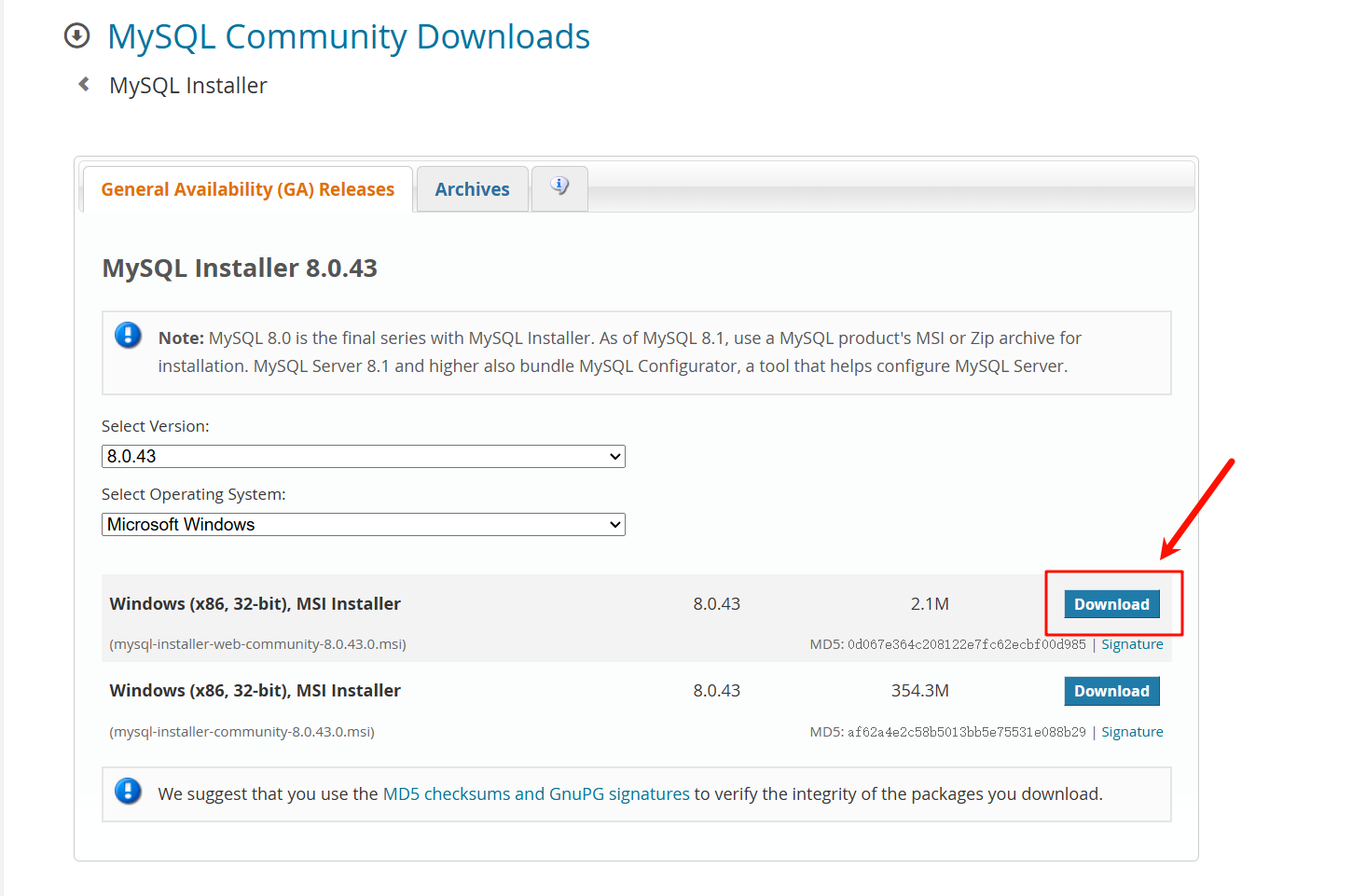
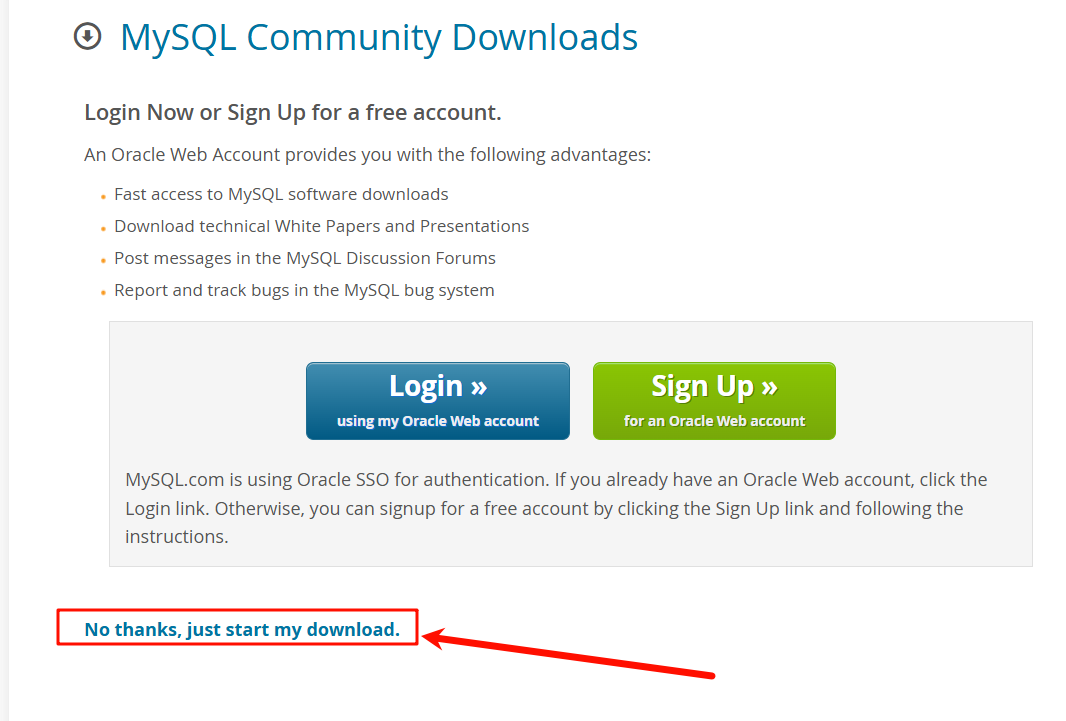
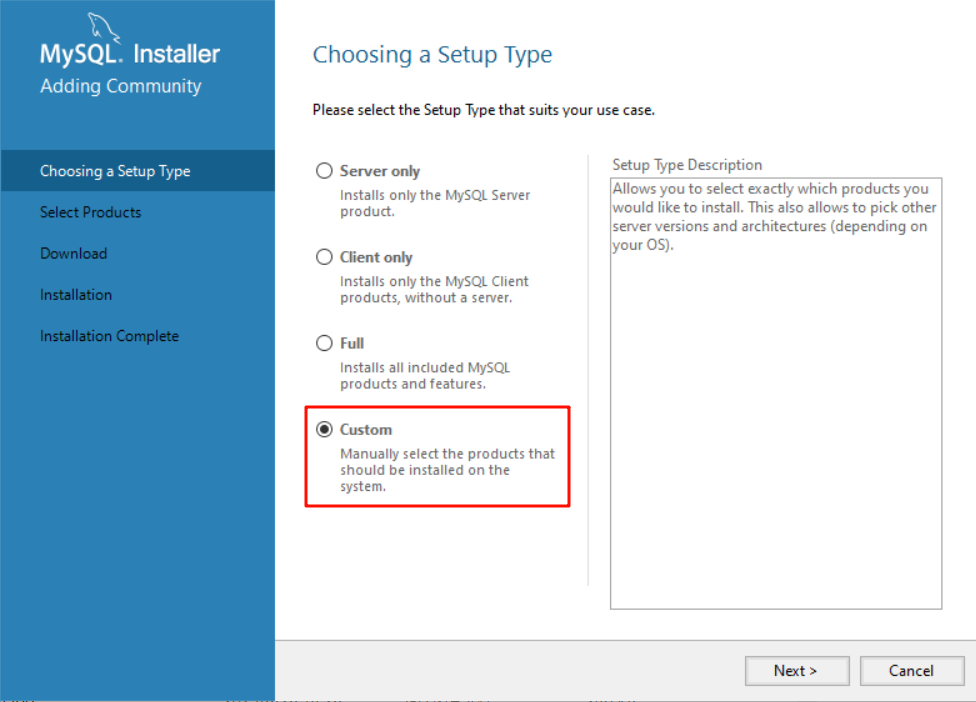
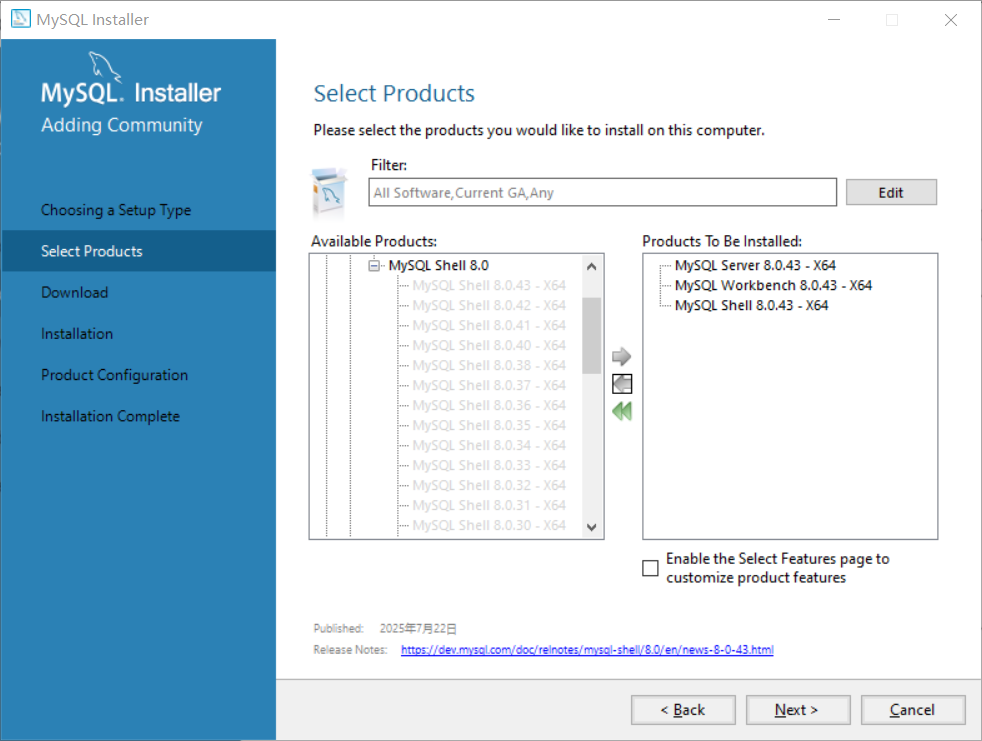
点击next—>execute—>next—>execute—>next—>next
PS:需要网络代理并关掉杀毒软件,不然安装会报错
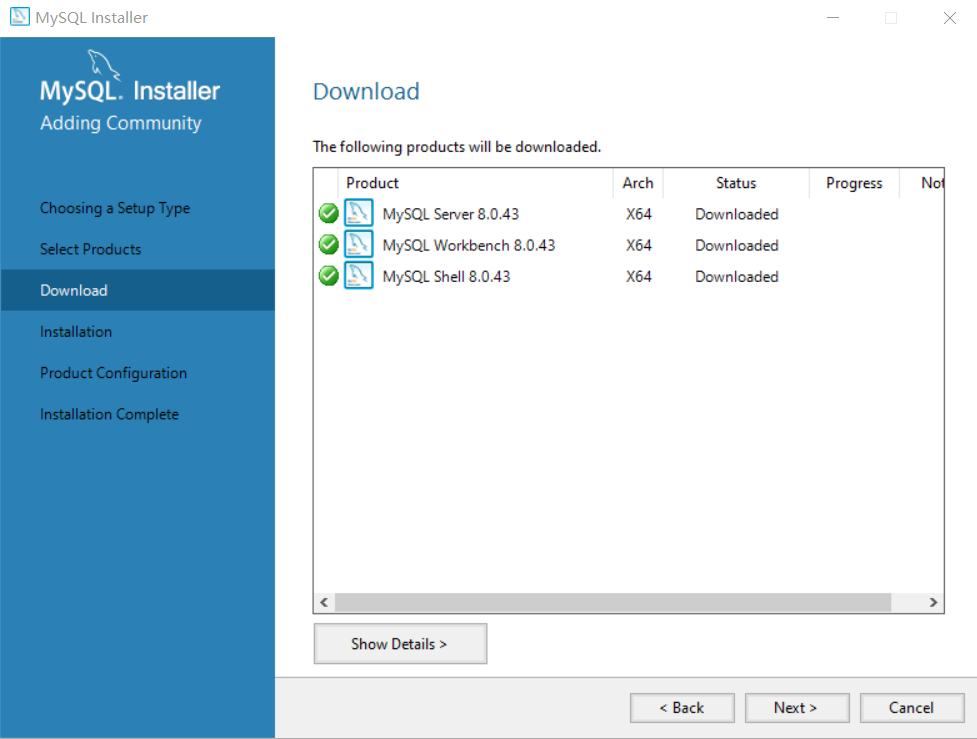
预设即可,点next
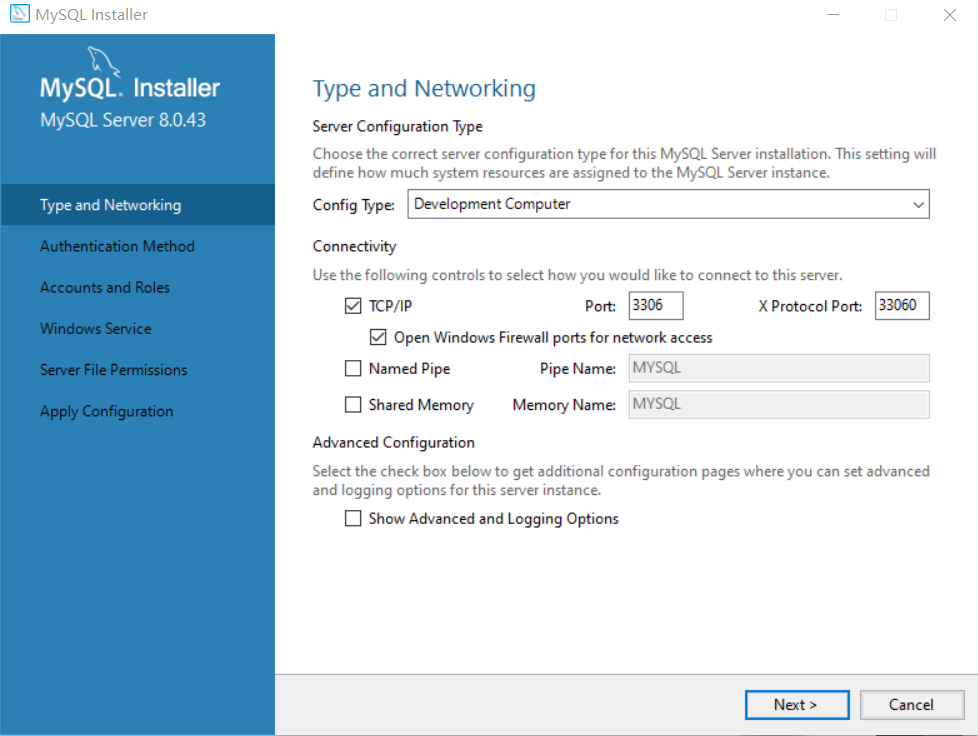
同样不改变,点next
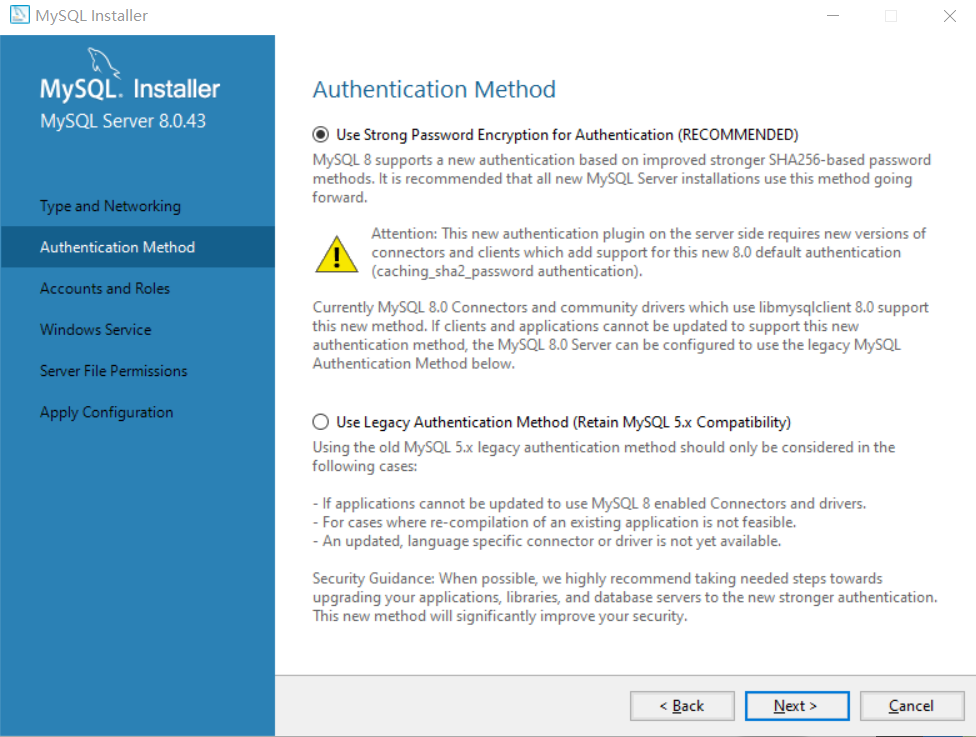
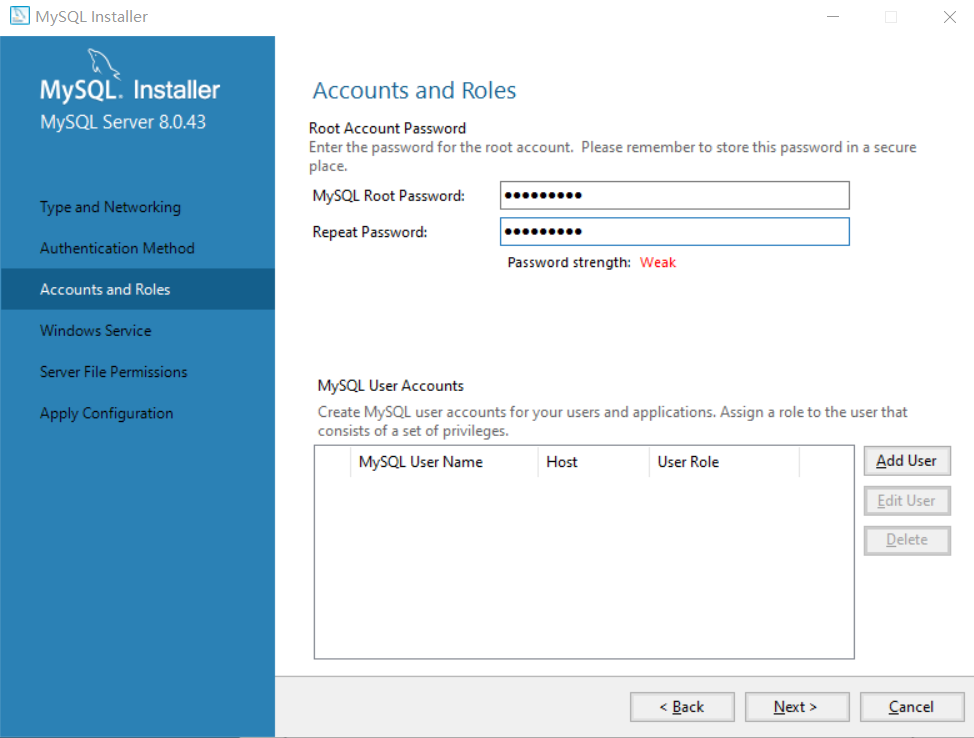
这里输入数据库管理员密码,点next
PS:一定要记起来
预设即可,下一步next,后面就shi
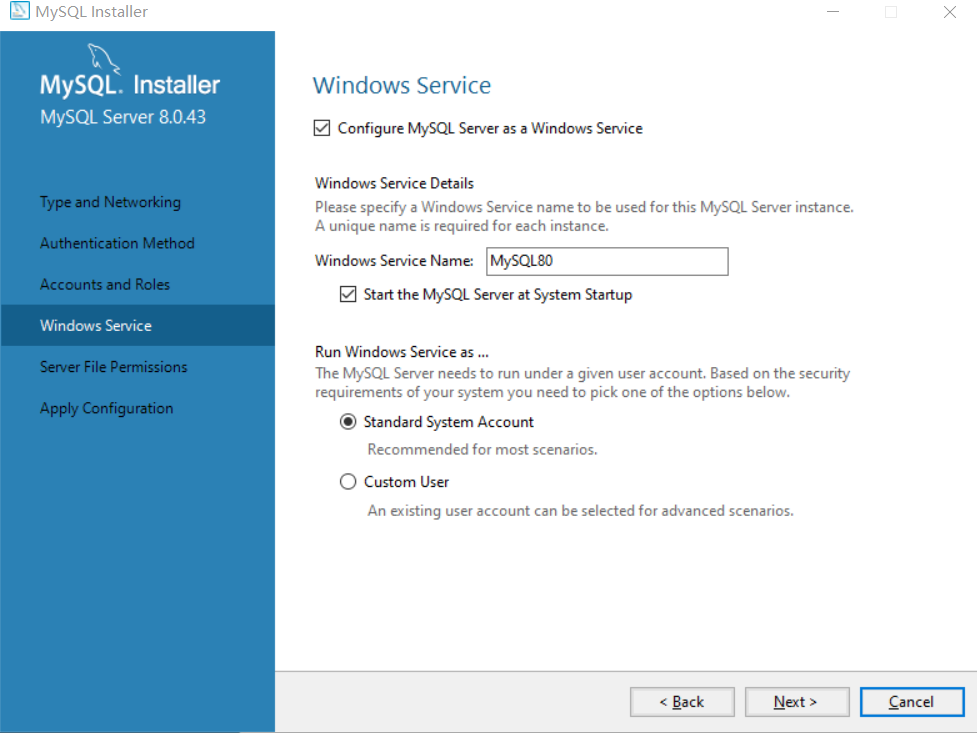
next—>execute—>finish—>next—>finish
然后他会自动弹出Shell和Wrokbench的窗口,这样就算安装完成了。
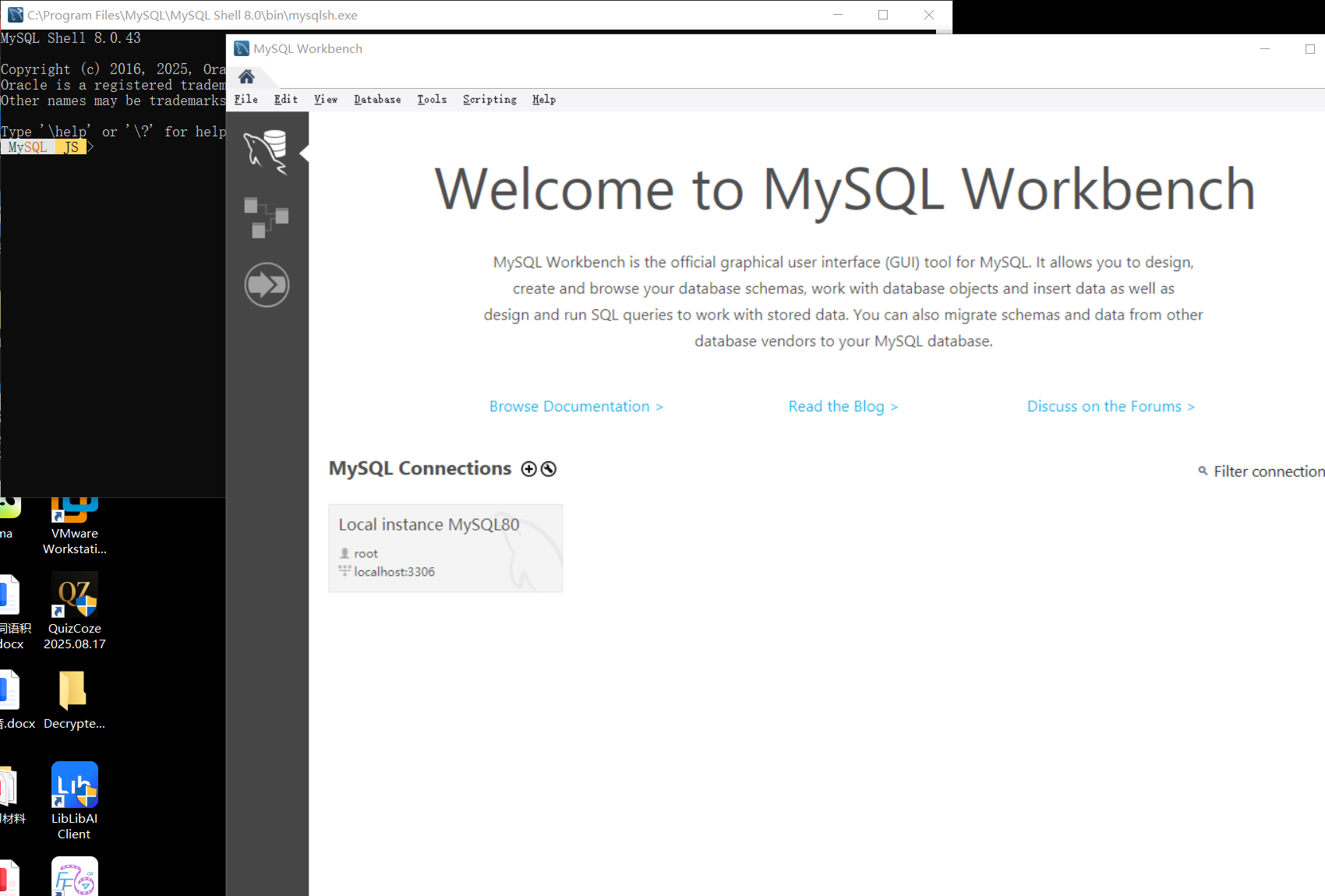
建立数据库连接
在Workbench界面,我们可以看到系统已经自带了一个数据库连接“Local instance MySQL80”;
点击“+”号,我们可以新增数据库连接
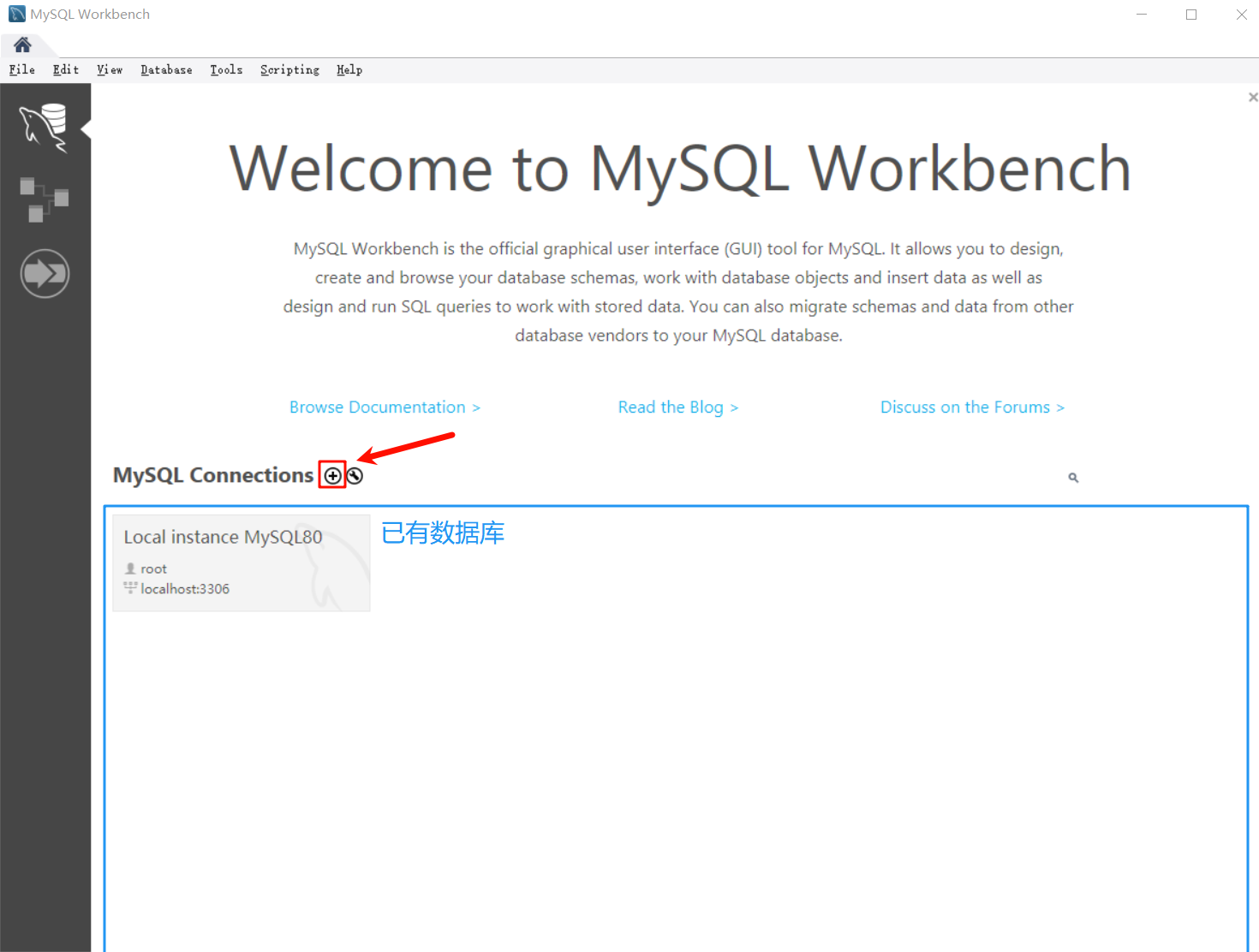
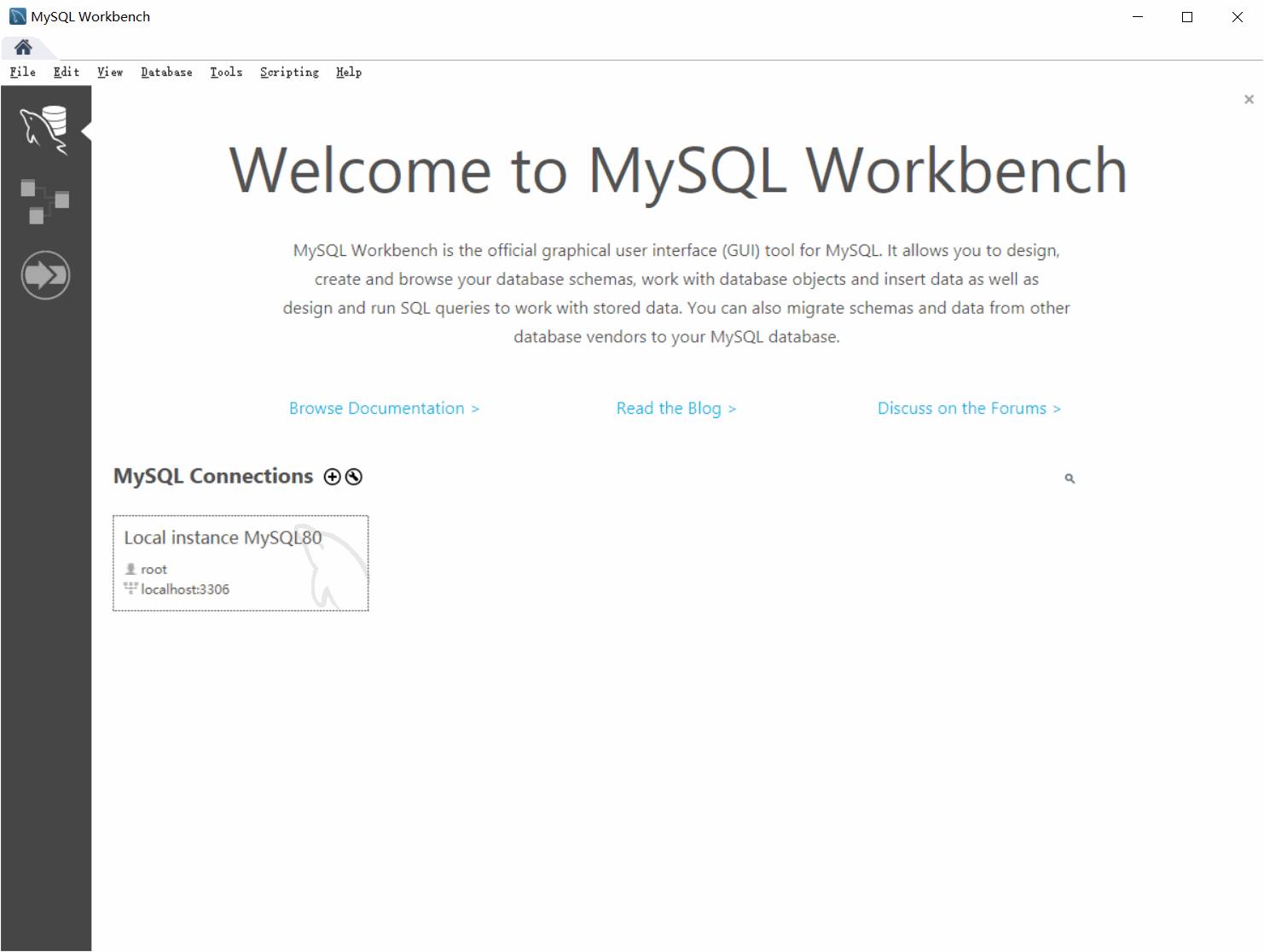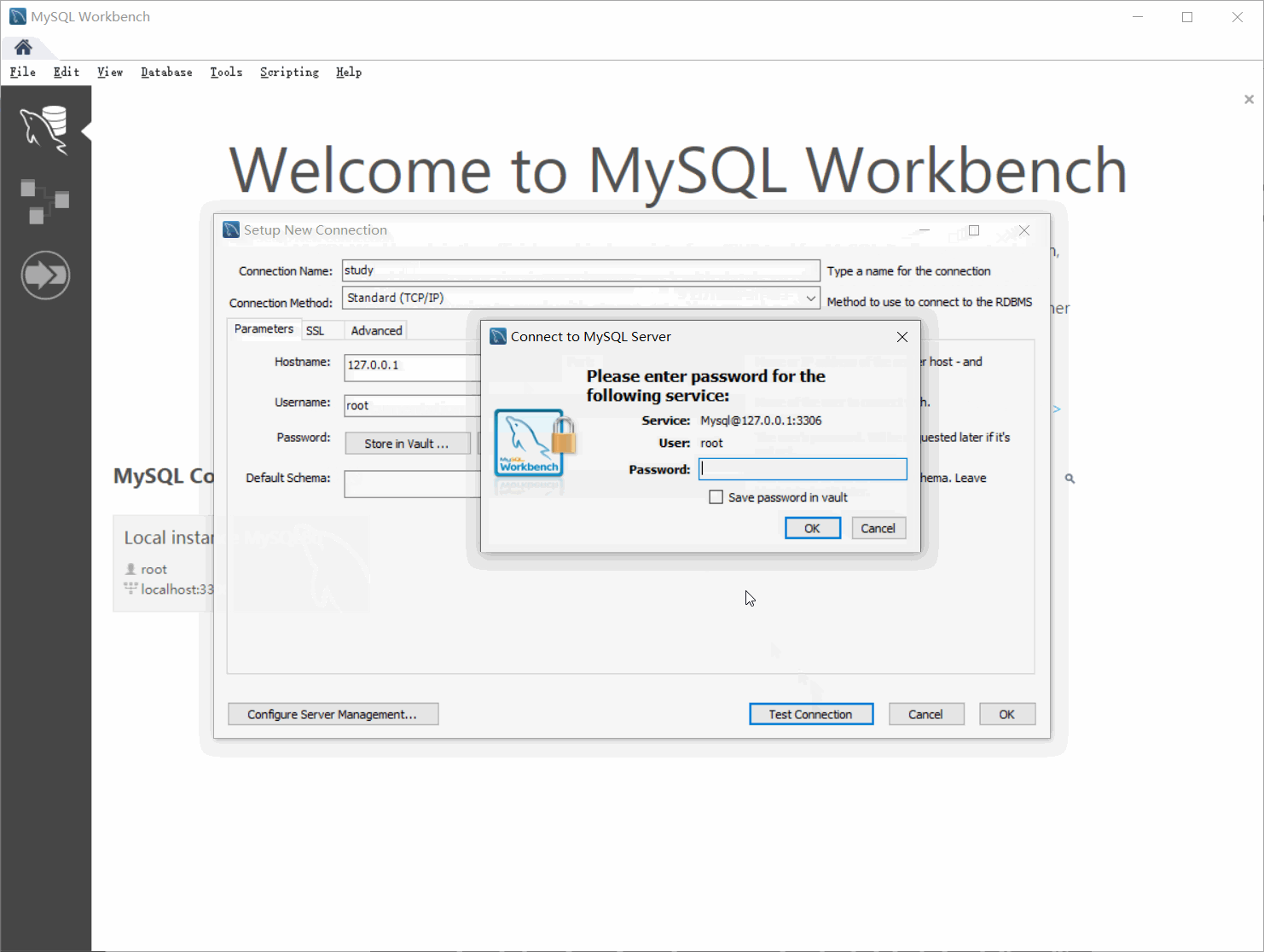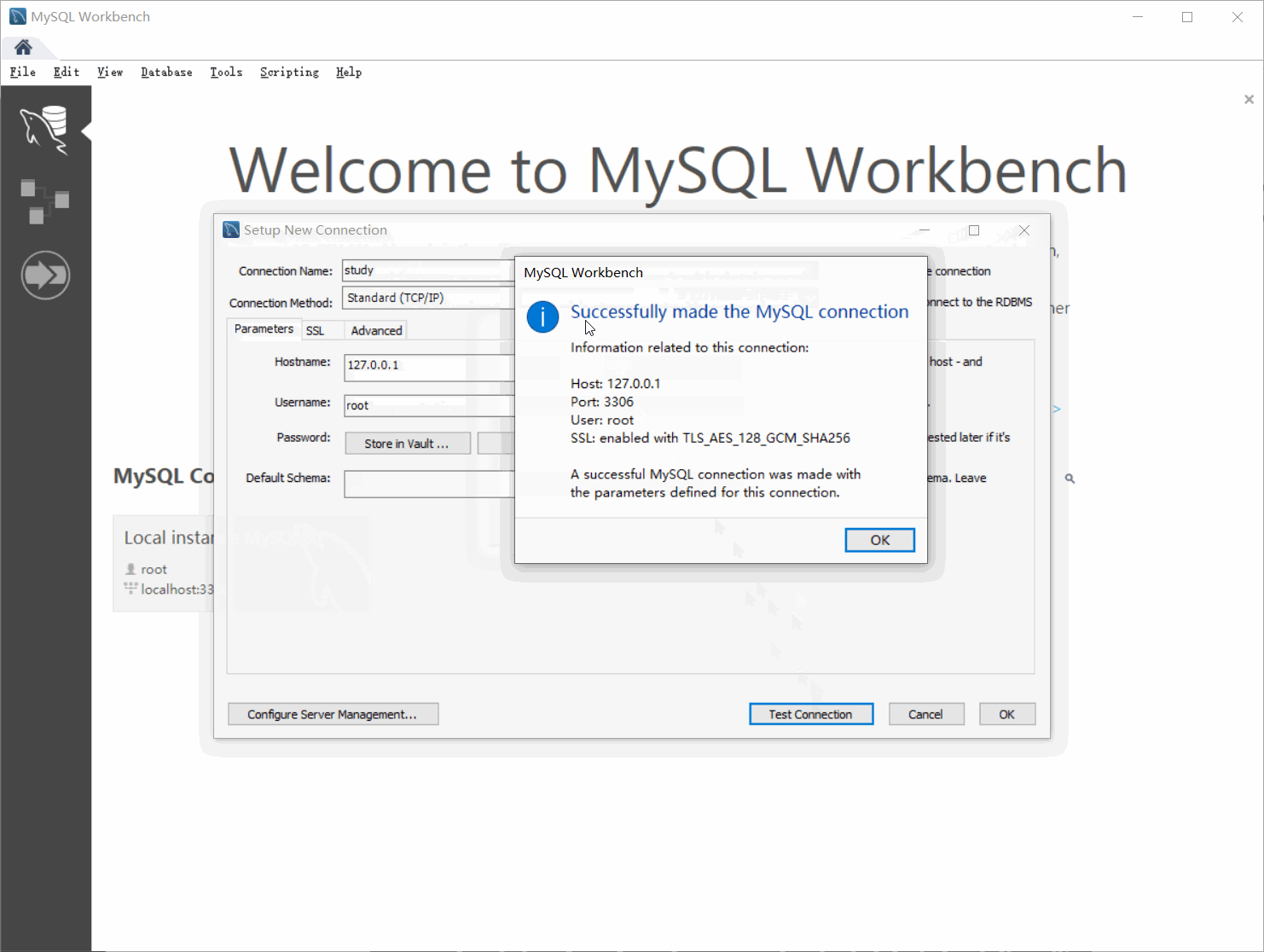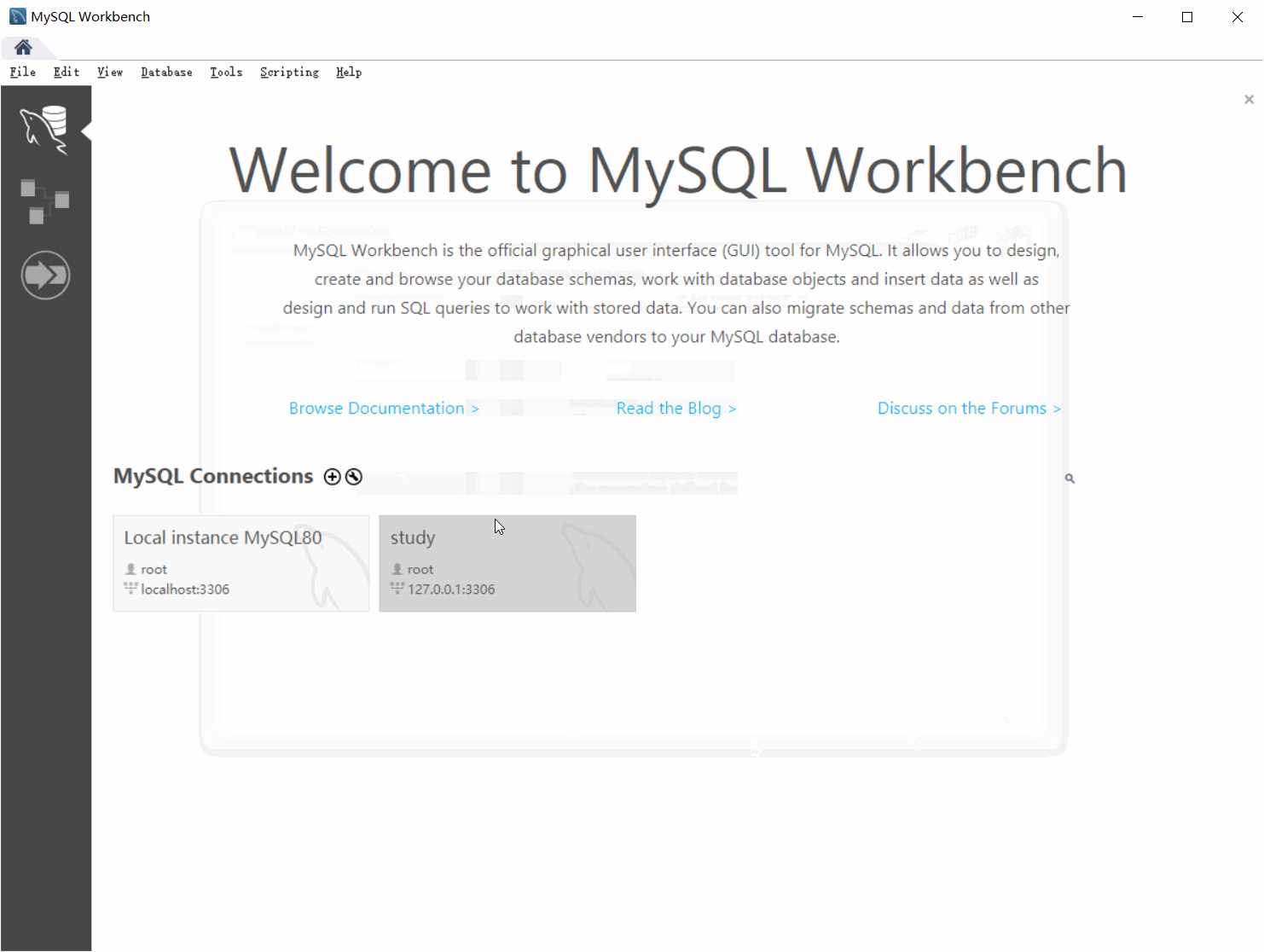
按我下面的动图操作(输入名字—>测试连接—>OK)
SQL语句
表和键(Tables and keys)
表是由行(具体的数据值)和列(定义数据类型)组成的数据集合,每一行就是一条完整的数据记录,就像Excel中除标题行外的每一行数据。
键:“键”的主要作用是唯一标识记录和建立表之间的关系,以确保数据的唯一性和参照完整性
主键 (Primary Key)
它是表中唯一确定一条记录的(或列的组合)
值必须唯一且不允许为NULL
如果一个主键无法唯一标识一条数据,那么则需要两列组合起来作为主键,叫复合主键
一个表只能有一个主键(复合主键算一个主键)
下表格红色字的列则是主键
外键 (Foreign Key)
它用于建立和加强两个表之间的链接。一个表中的外键通常是另一个表的主键。
作用:维护数据库的参照完整性。可以防止出现“无效”的数据。
例如,有了外键约束,你就无法在“订单表”中插入一个不存在的“客户ID”。
注意:如果有了外键约束,则先要把父表如下的Branch表先删除,然后才能删子表Employee表。
下表格绿色字的列则是外键
Employee 员工表
Branch 部门表
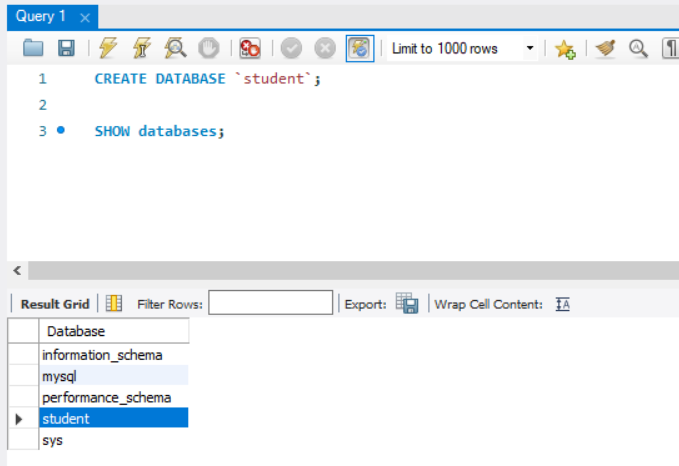
创建数据库
-- 创建数据库 CREATE DATABASE `<data-name>`;
CREATE DATABASE `student`;
-- 显示已有数据库
SHOW DATABASES;
-- 删除数据库
DROP DATABASE `student`;运行结果如下;(另外四个数据库是MySQL自带的:
information_schema:元数据仓库,存储MySQL服务器中所有数据库、表、列、权限等结构信息;
mysql:核心系统库,管理用户账户、权限、存储过程、事件调度器等;
performance_schema:性能监控,实时采集服务器内部运行指标;
sys:诊断工具箱,基于 performance_schema和 information_schema提供友好视图;)
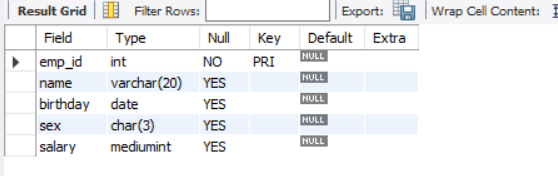
创建表格
-- 创建表格前,先进入所要操作的数据库
USE `employee`;
-- 创建表格
CREATE TABLE `employee`(
-- 列名:`<name>` 数据类型,
`emp_id` INT PRIMARY KEY, -- 主键
`name` VARCHAR(20),
`birthday` DATE,
`sex` CHAR(3),
`salary` MEDIUMINT
-- 主键也可以这样写
-- PRIMARY KEY(`emp_id`)
);
-- 显示表格
-- 不是DESCRIBE TABLE `employee`;
DESCRIBE `employee`;
-- 添加/删除表格内属性: 使用ALTER
ALTER TABLE `employee` ADD `branch_id` INT;
ALTER TABLE `employee` DROP COLUMN `branch_id`;
-- 删除表格
DROP TABLE `employee`;注意:如果是要设置外键的话,需要先把另张表(外键所对的主键的表)创建好,然后才能设置外键!
SQL的数据结构:
存入数据(insert)
用INSERT语句,如下图的代码,填入的使用要按照TABLE的数据结构顺序来填入;
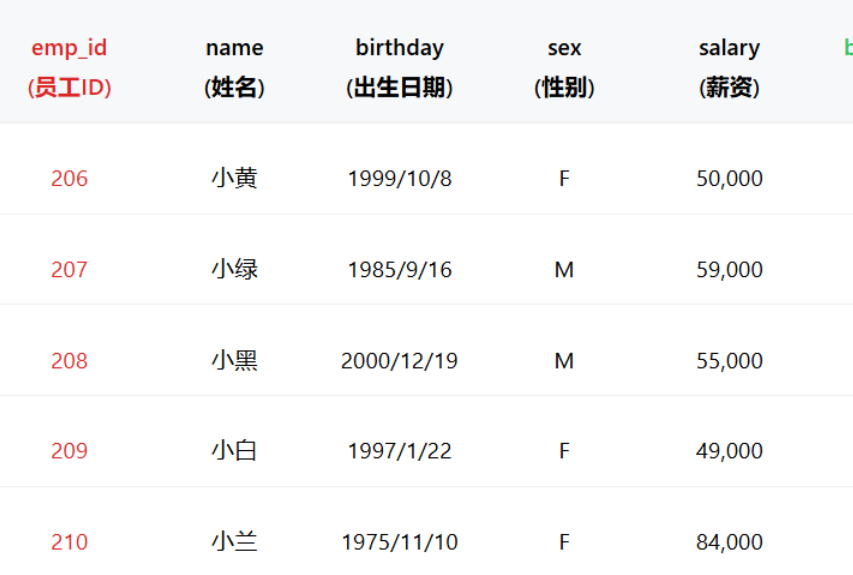
按照上表的内容存入;
-- 存入数据(insert)
INSERT INTO `employee` VALUE(206, "小黄", "1999-10-08", "F" ,50000);
INSERT INTO `employee` VALUE(207, "小绿", "1985-09-16", "M" ,59000);
INSERT INTO `employee` VALUE(208, "小黑", "2000-12-19", "M" ,55000);
INSERT INTO `employee` VALUE(209, "小白", "1997-01-22", "F" ,49000);
INSERT INTO `employee` VALUE(210, "小兰", "1975-11-10", "F" ,84000);
-- 你也可以如下自定输入顺序
INSERT INTO `employee`(`name`, `birthday`, `sex`, `emp_id`, `salary`) VALUES("小凡", "1995-12-08", "F" , 211, 74000);
-- 删除数据
DELETE FROM `employee` WHERE `emp_id` = 211;
-- 检索填入的数据
SELECT * FROM `employee`;结果如下:
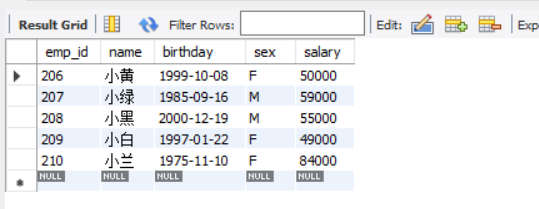
注意:最下面一行全是NULL是正常的,这只是在你的计算机中显示出来,实际上数据库是没有这条值的!
限制、约束(constraint)
CREATE TABLE `employee` (
-- 主键约束,确保唯一标识每条记录。AUTO_INCREMENT 让数据库自动生成递增ID,简化插入操作。
`emp_id` INT NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT '员工ID,主键',
-- NOT NULL 约束,确保姓名必须填写,避免数据不完整。
-- COMMENT是一个用于为数据库对象添加描述性文本的语句,不是constraint。纯粹是为了提高代码的可读性和维护性,数据库系统本身不会解析或执行它们
`name` VARCHAR(20) NOT NULL COMMENT '员工姓名',
`birthday` DATE COMMENT '出生日期',
-- CHECK约束确保性别字段只能是指定值之一,DEFAULT约束为未明确指定性别的记录提供默认值'U'。
`sex` CHAR(1) DEFAULT 'U' CHECK (`sex` IN ('M', 'F', 'U')) COMMENT '性别(M:男, F:女, U:未知)',
-- CHECK约束防止薪资出现负值,DEFAULT约束确保即使未提供薪资也有默认值0。
`salary` MEDIUMINT NOT NULL DEFAULT 0 CHECK (`salary` >= 0) COMMENT '薪资(必须≥0)',
-- UNIQUE约束确保每位员工的邮箱地址在表中是唯一的,防止重复。
`email` VARCHAR(100) UNIQUE COMMENT '邮箱地址',
`dept_id` INT COMMENT '部门ID',
-- 表级约束语法(外键):
-- 外键约束确保dept_id的值必须存在于另一个表的主键中,维护数据一致性。
-- ON DELETE SET NULL表示当引用的部门被删除时,此处设置为NULL;
-- ON UPDATE CASCADE表示引用的部门ID更新时,此处自动同步更新。
CONSTRAINT `fk_employee_dept_id` FOREIGN KEY (`dept_id`) REFERENCES `department` (`dept_id`) ON DELETE SET NULL ON UPDATE CASCADE,
-- 表级约束语法(复合唯一键):如果需要在多列组合上确保唯一性,可以使用类似下面的语句
-- CONSTRAINT `uniq_emp_name_birthday` UNIQUE (`name`, `birthday`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='员工表';修改、删除数据(update、delete)
/*
UPDATE table_name
SET column1 = new_value1, column2 = new_value2, ...
WHERE condition;
*/
-- 修改(更新)
UPDATE `employee`
SET `salary` = 58000 , `name` = "小改"
WHERE `emp_id` = 208;
-- 删除数据
DELETE FROM `employee`
WHERE `employee_id` = 203;TRUNCATE、DELETE、DROP三者的核心区别:
检索数据(select)
SELECT [DISTINCT] * | 字段名1, 字段名2, ...
FROM 表名
[WHERE 条件表达式]
[GROUP BY 字段名 [HAVING 条件表达式]]
[ORDER BY 字段名 [ASC | DESC]]
[LIMIT [偏移量,] 记录数];select及其子语句:
聚合函数
以下是 MySQL 中最核心和常用的五个聚合函数,以及一个实用的字符串聚合函数:
-- COUNT()- 计数函数 用于统计记录的数量
-- 统计总行数(包括NULL行)
SELECT COUNT(*) AS total_employees FROM employees;
-- 统计特定列非NULL值的数量
SELECT COUNT(manager_id) AS have_manager_count FROM employees;
-- SUM()- 求和函数,用于计算数值列的总和
-- 计算所有员工的工资总和
SELECT SUM(salary) AS total_salary FROM employees;
-- AVG()- 平均值函数
-- 计算公司的平均工资
SELECT AVG(salary) AS average_salary FROM employees;
-- MAX()/ MIN()- 最值函数,用于查找最大值或最小值
-- 查找最高和最低工资
SELECT MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees;
-- GROUP_CONCAT()- 字符串聚合函数,这是一个非常实用的函数,用于将分组内的多个值拼接成一个字符串
-- 将所有员工的名字拼接起来
SELECT GROUP_CONCAT(first_name) AS all_names FROM employees;
-- 按部门分组,拼接员工名,并使用特定分隔符
SELECT department_id, GROUP_CONCAT(first_name SEPARATOR ' | ') AS dept_employees
FROM employees
GROUP BY department_id;通配符(wildcard)
通配符是 SQL 中用于进行模糊匹配的强大工具,一般配合LIKE操作符来进行模糊查询。
MySQL 主要支持两个通配符:
-%:匹配任意数量的字符(包括零个字符)
-_:匹配单个任意字符
-- 查找所有姓“黄”的用户名
SELECT username FROM users WHERE username LIKE '黄%';
-- 查找第二个字符为 'a' 的所有名字
SELECT name FROM customers WHERE name LIKE '_a%';
-- 可能结果: 'David', 'Sarah', 'Nathan' 集合(union)
SQL 中的 UNION是一个用于合并多个查询结果的强大操作符。它可以将两个或多个 SELECT语句的结果集垂直堆叠在一起,组合成一个单一的结果集。
-- 使用 UNION 查询员工和客户的基本信息(会自动去重)
SELECT `emp_id` AS `id`, name, '员工' AS `类型` FROM `employee`
UNION
SELECT `client_id`, `client_name`, '客户' FROM `client`
ORDER BY `id`;
-- 使用 UNION ALL 查询员工和客户的基本信息(保留所有记录)
SELECT `emp_id` AS `id`, `name`, '员工' AS `类型` FROM `employee`
UNION ALL
SELECT `client_id`, `client_name`, '客户' FROM `client`
ORDER BY `id`;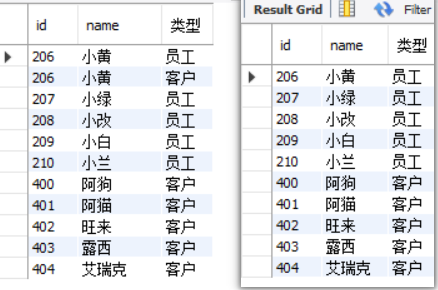
使用 UNION 必须遵守的规则
使用 UNION时,必须遵循几个核心规则:
列数相同:所有
SELECT语句必须拥有相同数量的列。数据类型兼容:对应列的数据类型必须相似或兼容(例如,可以合并
CHAR和VARCHAR,但合并INT和TEXT可能导致错误或意外结果)。列顺序一致:每条
SELECT语句中列的顺序必须相同。
在SQL优化中,要避免使用OR查询,使用UNION/UNIONALL代替,因为OR查询有时会使索引失效,降低查询效率。
-- 查询薪资大于 55000 或 姓名包含 '张' 的员工
--用OR
SELECT emp_id, name, salary, '员工' as type
FROM employee
WHERE salary > 55000 OR name LIKE '%张%';
-- 使用 UNION ALL 替代 OR
SELECT emp_id, name, salary, '员工' as type
FROM employee
WHERE salary > 55000
UNION ALL
SELECT emp_id, name, salary, '员工' as type
FROM employee
WHERE name LIKE '%张%';连接(join)
SQL 中的 JOIN 用于将多个表中的行基于它们之间的相关列组合起来。
以下是主要的 JOIN 类型及其区别
-- 内连接
SELECT e.emp_id, e.name AS employee_name, c.client_id, c.client_name
FROM employee e
INNER JOIN client c ON e.emp_id = c.client_id;
-- 左连接
SELECT e.emp_id, e.name AS employee_name, c.client_id, c.client_name
FROM employee e
LEFT JOIN client c ON e.emp_id = c.client_id;
-- 右连接
SELECT e.emp_id, e.name AS employee_name, c.client_id, c.client_name
FROM employee e
RIGHT JOIN client c ON e.emp_id = c.client_id;
-- 全外连接
SELECT e.emp_id, e.name AS employee_name, c.client_id, c.client_name
FROM employee e
LEFT JOIN client c ON e.emp_id = c.client_id
UNION
SELECT e.emp_id, e.name AS employee_name, c.client_id, c.client_name
FROM employee e
RIGHT JOIN client c ON e.emp_id = c.client_id;
-- 交叉连接
SELECT e.emp_id, e.name AS employee_name, c.client_id, c.client_name
FROM employee e
CROSS JOIN client c;!!在 MySQL 中,没有直接用于全外连接(FULL OUTER JOIN)的专用关键字。这是 MySQL 与一些其他数据库系统(如 SQL Server、Oracle 或 PostgreSQL)的一个差异点
子查询,又名嵌套查询(subquery)
1. 标量子查询(返回单个值)
-- 查询薪资高于平均薪资的员工信息
SELECT `emp_id`, `name`, `salary`
FROM `employee`
WHERE `salary` > (
SELECT AVG(`salary`)
FROM `employee`
); 2.列子查询(返回一列数据)
-- 查询有对应客户记录的员工信息(client_id 与 emp_id 有交集)
SELECT `emp_id`, `name`, `salary`
FROM `employee`
WHERE `emp_id` IN (
SELECT `client_id`
FROM `client`
); 3. 相关子查询(依赖于外层查询的当前行值)
-- 查询薪资超过其自身平均薪资的员工及其薪资
SELECT e1.emp_id, e1.name, e1.sex, e1.salary
FROM employee e1
WHERE e1.salary > (
SELECT AVG(e2.salary)
FROM employee e2
WHERE e2.sex = e1.sex -- 子查询依赖外层查询的e1.sex
);4. 在 FROM 子句中使用子查询(派生表)
-- 查询每个性别的员工人数和平均薪资
SELECT sex, COUNT(*) AS num_employees, AVG(salary) AS avg_salary
FROM (
SELECT *
FROM employee
) AS emp_derived -- 这里子查询简单选择所有记录,实际可以更复杂
GROUP BY sex;5. 使用 EXISTS 和 NOT EXISTS
-- 在 EXISTS 子查询中,必须用别名(如下面的“e”、“c”)来建立内外层查询的关联
SELECT `emp_id`, `name`
FROM `employee` e
WHERE EXISTS (
SELECT 1 -- '1' 就是一个简单的占位符,表示“只要存在就行”
FROM client c
WHERE c.client_id = e.emp_id -- 子查询使用外层查询的e.emp_id
);
-- 查询没有对应客户记录的员工信息(使用 NOT EXISTS)
SELECT `emp_id`, `name`
FROM employee e
WHERE NOT EXISTS (
SELECT 1
FROM client c
WHERE c.client_id = e.emp_id
);注意:在sql优化方面,需要避免子查询,使用JOIN代替
on delete
ON DELETE是定义外键约束时的一个关键子句,它决定了当父表(被引用表)中的一条记录被删除时,子表(引用表)中那些引用了该记录的记录该如何处理。其核心目的是为了维护数据库的参照完整性。
MySQL 主要支持以下几种ON DELETE操作:
-- 写在表结构定义时用到on delete
-- 定义外键并指定 ON DELETE CASCADE
CONSTRAINT fk_order_item FOREIGN KEY (order_id) REFERENCES orders(order_id) ON DELETE CASCADE -- 当订单被删除,订单项自动级联删除
-- 修改现有表添加约束 (ALTER TABLE)用到on delete时
ALTER TABLE employee ADD CONSTRAINT fk_employee_department FOREIGN KEY (department_id) REFERENCES departments(department_id) ON DELETE SET NULL; -- 当部门被删除,员工部门ID自动置为NULL事务
事务是数据库管理系统(DBMS)中一个非常重要的概念。你可以把它理解为一个不可分割的工作单元,它包含了一系列的操作步骤,这些步骤要么全部成功执行,要么全部不执行,不会存在中间状态。
事务具备ACID这四大特性:
-- 原子性:事务中的所有操作是一个不可分割的整体,要么全部成功,要么全部失败回滚;
-- 一致性:事务执行后,数据库必须从一种一致性状态变换到另一种一致性状态,不会破坏预定义的业务规则和约束;
-- 隔离性:多个并发执行的事务之间相互隔离,互不干扰。一个事务的执行不会影响其他事务;
-- 持久性:一旦事务成功提交,它对数据库的修改就是永久性的,即使系统发生故障也不会丢失。
USE database_name;
CREATE TABLE accounts (
id INT PRIMARY KEY,
name VARCHAR(50),
balance DECIMAL(10, 2)
)
-- 开始一个新事务
START TRANSACTION;
-- 操作1:从用户A的账户中扣除100元
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
-- 操作2:向用户B的账户中添加100元
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
-- 提交事务,使所有更改永久生效
COMMIT;事务的隔离性体验表:
⚠️ 注意事项
引擎选择:务必使用 InnoDB 引擎,因为 MyISAM 引擎不支持事务。
自动提交:确保 MySQL 的
autocommit参数是打开的(默认通常为1,即开启)。我们在实验时手动用START TRANSACTION或BEGIN开启事务,可以暂时覆盖autocommit的设置。会话与连接:两个操作必须在两个独立的数据库连接/会话中进行,才能在 MySQL 中真正模拟并发事务。
MySQL数据库的备份和恢复
一、手动备份恢复方法
数据文件手动备份
1.定位数据存储位置
使用以下命令查看MySQL数据文件目录:
SHOW GLOBAL VARIABLES LIKE '%datadir%'; 2.创建备份目录
在指定位置建立备份文件夹,例如:D:\backup
3.执行文件备份
将数据目录中的所有文件复制到备份文件夹中
数据恢复操作
模拟数据库故障
DROP DATABASE mydb;执行恢复流程
停止MySQL服务
将备份文件复制回原数据目录
重新启动MySQL服务
验证数据库恢复情况
二、mysqldump工具使用
备份操作命令
完整数据库备份
mysqldump -u用户名 -p密码 --all-databases > 备份文件.sql多数据库备份
mysqldump -u用户名 -p密码 --databases 数据库1 数据库2 > 备份文件.sql单表备份
mysqldump -u用户名 -p密码 数据库名 表名 > 备份文件.sql
数据恢复方法
登录MySQL系统
mysql -u用户名 -p密码执行恢复命令
SOURCE 备份文件绝对路径;
三、使用其他工具
很多的数据库连接工具都可以实现数据库的备份与恢复的操作,例如:navicat、workbench等。
MySQL-Workbench数据库备份_mysqlworkbench备份数据库-CSDN博客
Navicat备份数据库和还原数据库详解_navicat备份还原数据库-CSDN博客
用DBeaver进行数据备份与恢复_dbeaver备份数据库-CSDN博客

评论区