
最近在学习大模型微调,但是在实战阶段遇到了一个大问题——高质量的微调数据集实在太难找了。在人工智能领域,数据从来不只是原料,而是模型的生命线。它贯穿模型训练、优化与落地的全流程,直接决定模型能力的上限。当前行业的核心痛点,早已不仅仅是算力或算法瓶颈,更是在于缺乏高质量、高领域适配性的数据集。
最近在GitHub上找到了一个不错的开源的数据集创建工具——Easy Dataset
在本篇博客中,我会用两种方法带领大家获取自身所需的数据集:一是让大家了解一些公开数据集的获取途径和注意事项;二是教会大家使用Easy Dataset工具,批量转换垂直领域的文献到构建数据集的过程。
一、公开数据集的获取途径
当你只想通过微调提升模型的某一专项能力,且没有特殊数据保密要求时,完全不必从零构造数据集——开源社区的海量优质数据正在等你调用!这些经过预处理的公开数据集,不仅能节省90%+的数据准备时间,更自带行业验证标签,大幅降低试错成本。
下面我将系统梳理几大类主流数据集获取平台,并详解其核心特性与实战用法,助你快速获取“领域适配性强、标注质量高、即拿即用”的数据集!
PS:重要提示:本文推荐数据集仅限学习与研究目的,商用前请务必确认原始许可协议,禁止未经授权的商业用途。
Kaggle
https://www.kaggle.com
定位:全球最大数据科学竞赛平台,覆盖金融、医疗、图像等 20+领域,提供34万+数据集,附带社区分析案例与代码模板。
核心资源:
竞赛级数据:如Titanic生存预测、COVID-19病例数据,含高质量标注与特征工程范例。
行业专题库:医疗影像(如COVID Radiography)、金融时序数据(NASDAQ股票历史)等垂直领域数据。
适用场景:快速获取带标注的竞赛级数据,适配分类、回归任务模型微调;学习数据清洗与特征工程最佳实践。
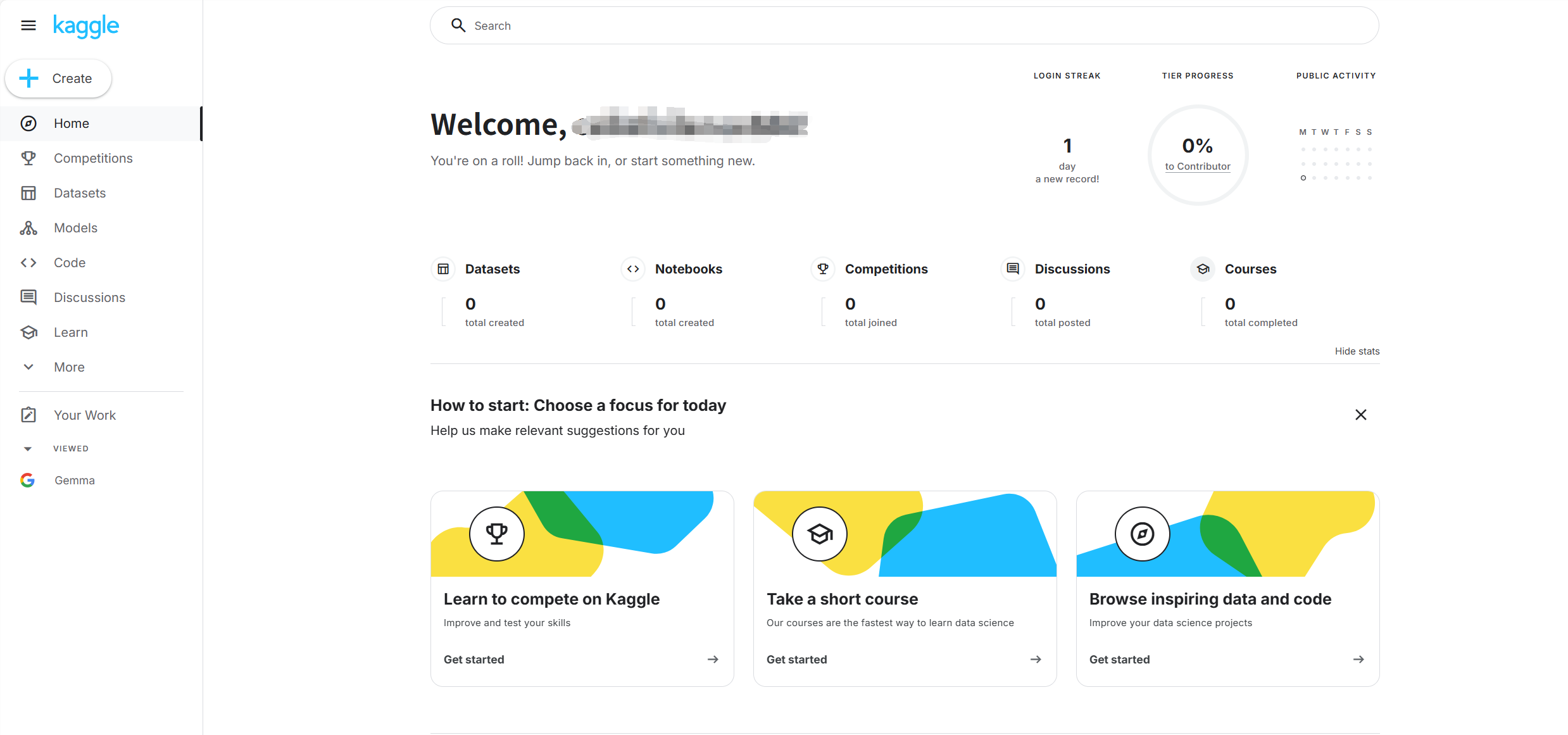
步骤:
点击左侧栏的Datasets
选择点击一个你想要的数据集
点击Download
有两种加载方式
直接下载zip格式的数据集压缩包,解压后通过yaml配置文件加载数据集
通过调用数据集的API
import kagglehub
# Download latest version
path = kagglehub.dataset_download("harishthakur995/mcdonald-vs-burger-king")
print("Path to dataset files:", path)
Hugging Face
https://huggingface.co
定位:NLP领域首选平台,集成16万+开源模型和2.6万+数据集,支持文本、语音、多模态任务,提供一键加载API。
核心资源:
NLP黄金集:IMDb情感分析、SQuAD问答、多语言翻译语料(如wmt14)。
中文加速方案:HF Mirror提供国内镜像,解决下载延迟问题。
适用场景:指令微调(如COIG中文对齐数据)、多模态训练(如COCO图文数据集);快速调用预训练模型推理。
注意:Hugging Face在国内不是很好用,我们可以使用Hugging Face的国内镜像网站MF Mirror
https://hf-mirror.com
我们可以看到这个MF Mirror镜像网站跟Hugging Face几乎一摸一样,只有域名上的区别。
步骤:
在站内搜索你想要的数据集
到对应页面进行下载,这里推荐两钟方式
一:在代码钟添加python脚本,如下面的gif
下载git
点击黑色按钮“Use this dataset”——>选第一个——>在代码中添加此代码
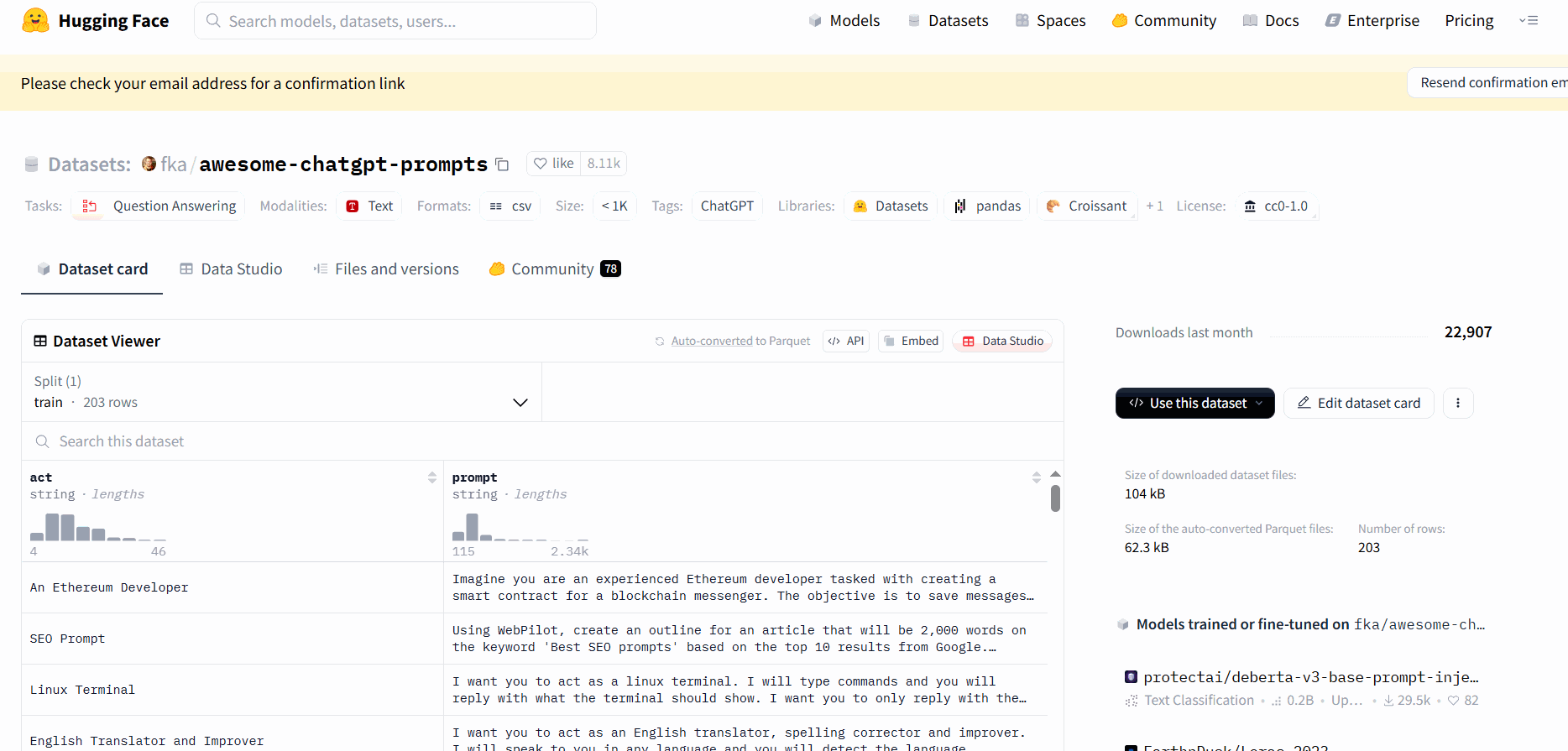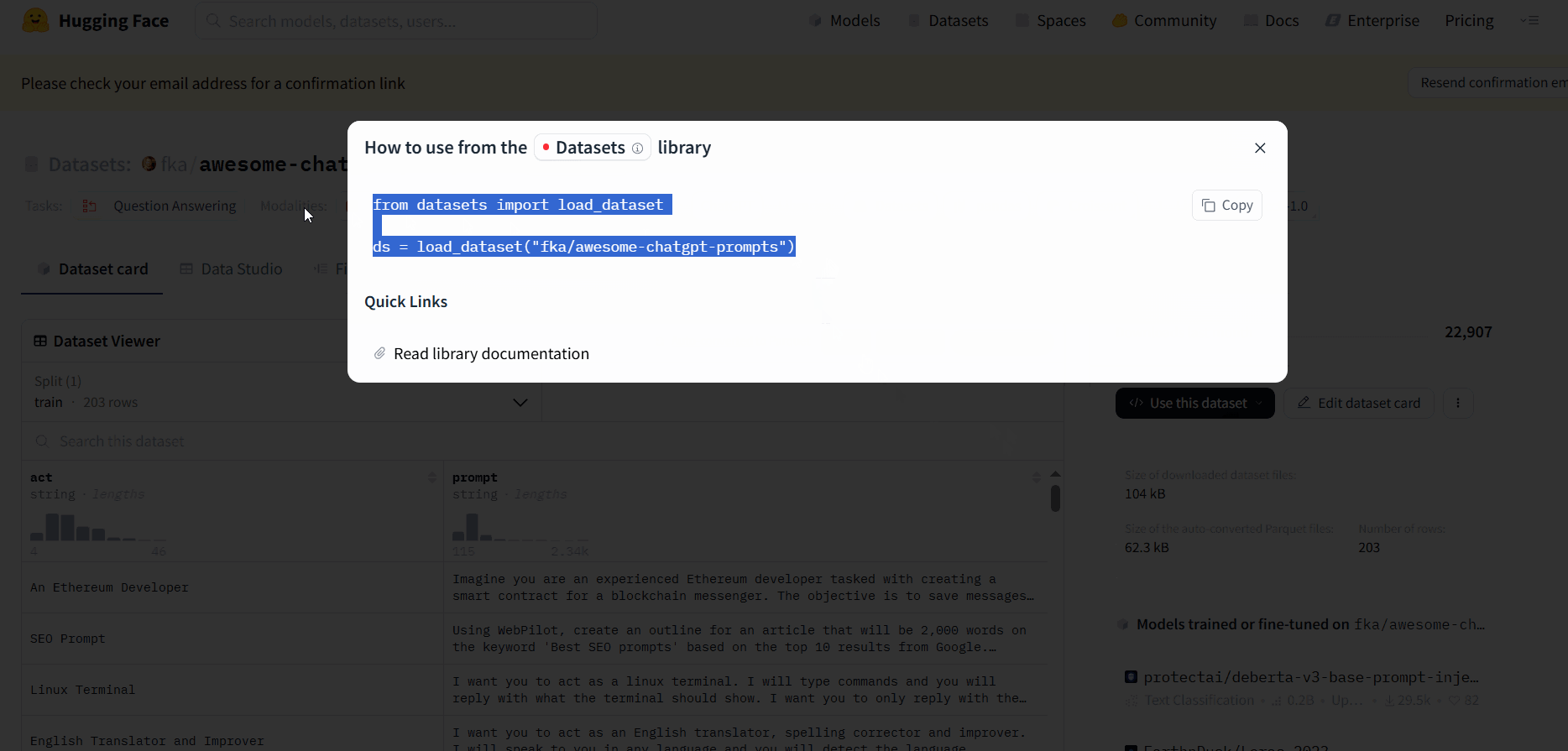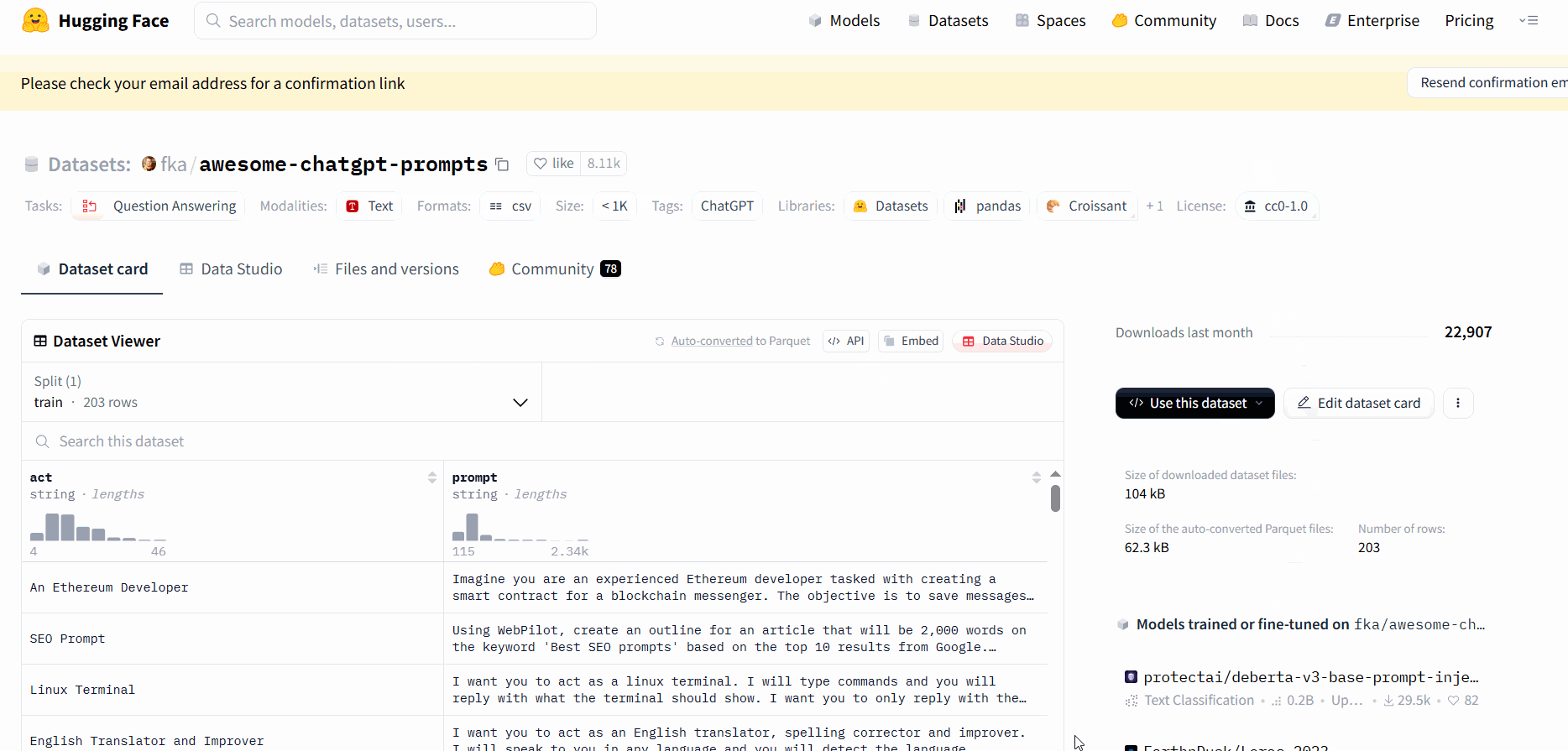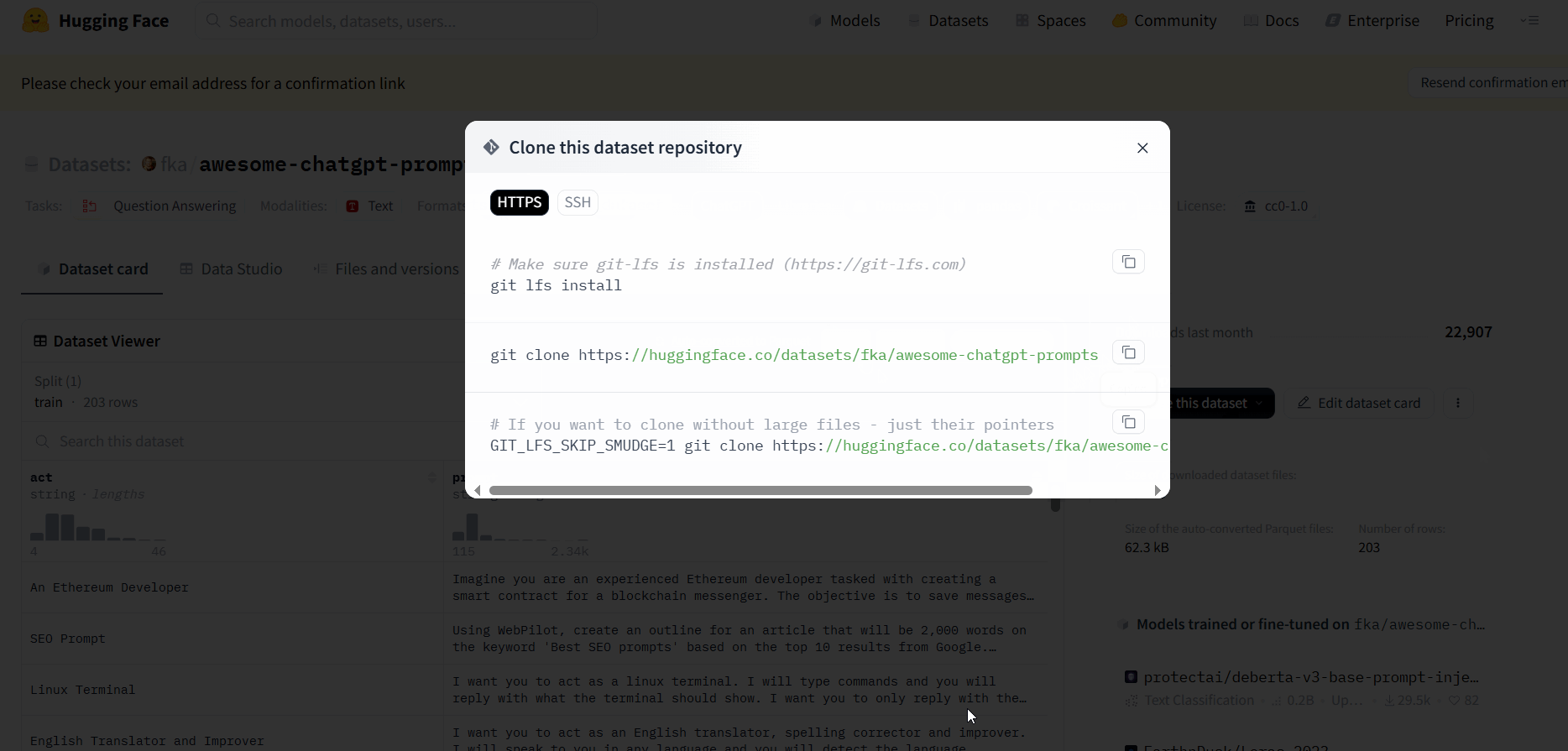
二:使用git clone
在页面侧边的点击三个点
复制第二个
在cmd命令窗口cd你想要的路径,复制刚刚的命令,回车
OpenDataLab
https://sso.openxlab.org.cn
定位:由上海人工智能实验室推出,专注中文及多模态数据,支持快速国内下载。
核心资源:
中文特色集:如金融文本分析、气象预测时序数据。
预格式化视觉集:图像-文本对齐数据、视频动作识别数据集。
适用场景:中文模型本土化微调;CV/NLP任务预训练数据获取;无需VPN的国内高速下载。
ModelScope
定位:阿里云推出的中文优先社区,覆盖NLP、CV、语音、科学计算领域。
核心资源:
中文优化集:古诗生成、法律文书解析、电商评论情感分析数据。
工业多模态集:工业质检图像、蛋白质结构预测数据。
适用场景:中文场景微调;工业视觉检测模型训练;开箱即用的模型推理与微调API。
步骤
进入站点,点击上方栏“数据集”,选择你所需的数据集
点数据集文件,再点击右侧下载数据集,它提供了三种命令行下载的方法,选择其中一种即可
Roboflow
https://universe.roboflow.com
定位:专注CV数据预处理,提供标注工具、格式转换、自动增强一站式服务,积累50万+图像/视频数据集(含5亿+图像)。
核心资源:
目标检测集:预格式化的COCO、PASCAL VOC版本。
合成数据工具:支持光照/遮挡增强,解决小样本问题。
适用场景:CV模型快速迭代;工业质检、医疗影像分析领域数据定制。
平台核心特色对比
二、使用Easy Dataset构建微调数据集
Easy Dataset是一款专为简化大模型微调数据构建而生的强大工具。它的核心使命是将用户手头的各种非结构化文档——比如常见的PDF、Markdown、Word文件等等——高效地转化为标准的高质量指令数据集。通过其创新的智能文本分割、自动化的问答对生成引擎以及灵活的领域标签管理系统,Easy Dataset 显著拉低了为特定领域打造专属AI模型的数据准备门槛和研发成本。
作为一款开源免费的工具,它不仅提供了用户友好的可视化操作界面,还强调数据处理在本地运行,最大限度地保障了用户数据的私密性与安全性,因此在开发者社区中备受推崇,成为快速构建领域知识助手的热门选择。
项目地址:
https://github.com/ConardLi/easy-dataset
功能特点
智能文档处理:支持 PDF、Markdown、DOCX 等多种格式智能识别和处理
智能文本分割:支持多种智能文本分割算法、支持自定义可视化分段
智能问题生成:从每个文本片段中提取相关问题
领域标签:为数据集智能构建全局领域标签,具备全局理解能力
答案生成:使用 LLM API 为每个问题生成全面的答案、思维链(COT)
灵活编辑:在流程的任何阶段编辑问题、答案和数据集
多种导出格式:以各种格式(Alpaca、ShareGPT)和文件类型(JSON、JSONL)导出数据集
广泛的模型支持:兼容所有遵循 OpenAI 格式的 LLM API
用户友好界面:为技术和非技术用户设计的直观 UI
自定义系统提示:添加自定义系统提示以引导模型响应
项目部署
Easy Dataset目前有三种方式可以在计算机上使用:
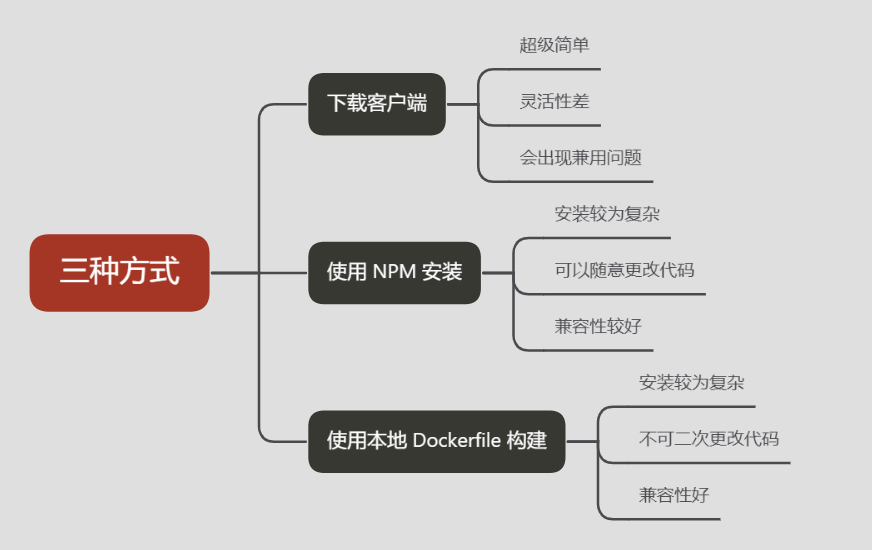
1.下载客户端
操作非常简单
首先到上面的项目地址,根据下面的视频下载安装包;
打开安装包,参考下面的进行选择(下一步→选路径→安装→完成)
ps:如果打开软件报错,请使用管理员身份运行
2.使用 NPM 安装
克隆仓库:
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset注意:如果出现下列的报错,请使用管理员权限运行命令窗口
fatal: could not create work tree dir 'easy-dataset': Permission denied
安装依赖:
npm install启动开发服务器:
npm run build
npm run start打开浏览器并访问
http://localhost:1717
3.使用本地 Docker file 构建
1.克隆仓库:
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset注意:如果出现下列的报错,请使用管理员权限运行命令窗口
fatal: could not create work tree dir 'easy-dataset': Permission denied
2.构建 Docker 镜像:
docker build -t easy-dataset .3.运行容器:
docker run -d -p 1717:1717 -v {YOUR_LOCAL_DB_PATH}:/app/local-db --name easy-dataset easy-dataset注意: 请将 {YOUR_LOCAL_DB_PATH} 替换为你希望存储本地数据库的实际路径。
4.打开浏览器,访问 http://localhost:1717
使用方法
首先,按照上面的内容,打开Easy Dataset,打开后的界面如下:
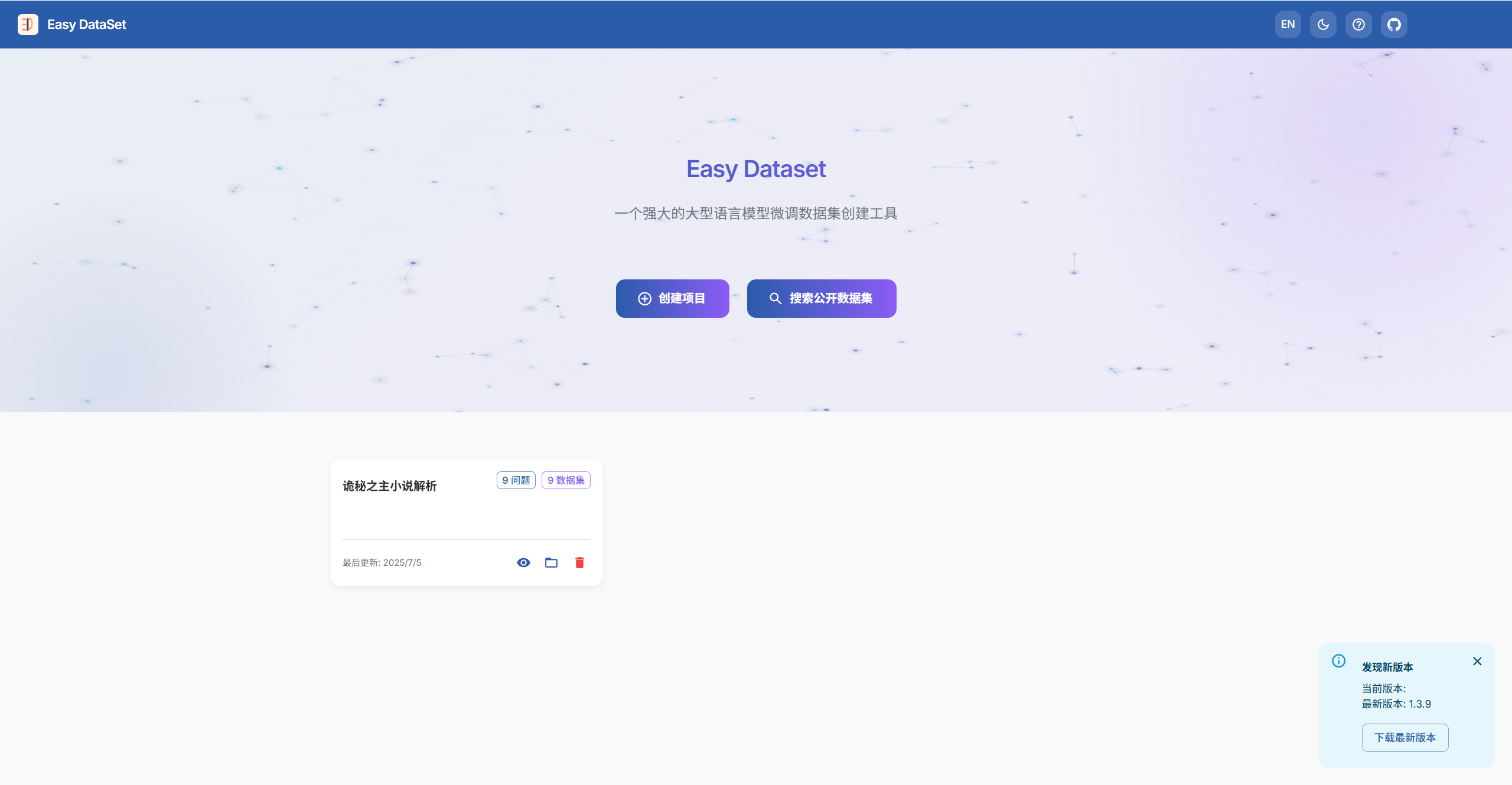
基本介绍
Easy Dataset具有两个大的功能,一个是自己创建数据集项目,另一个是搜索公开数据集

先介绍搜索公开数据集,该模块直接整合 HuggingFace、OpenDataLab、谷歌开源等10+平台数据源,避免反复切换网站。
创建个人数据集
接下来,我要介绍另一个部分——创建数据集项目,点击创建项目,根据自己的需求填写项目名称和信息,随后点击右下角创建项目
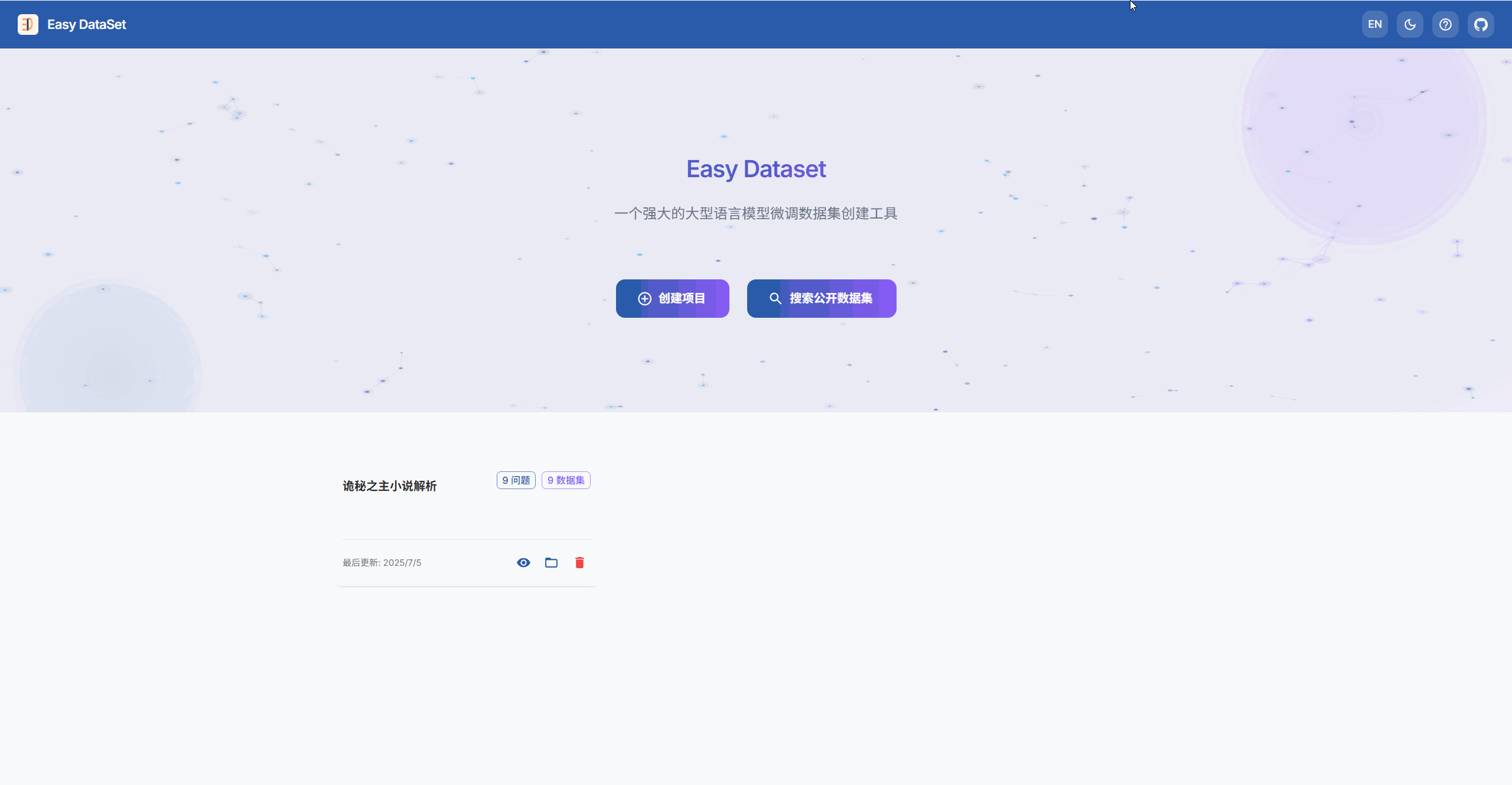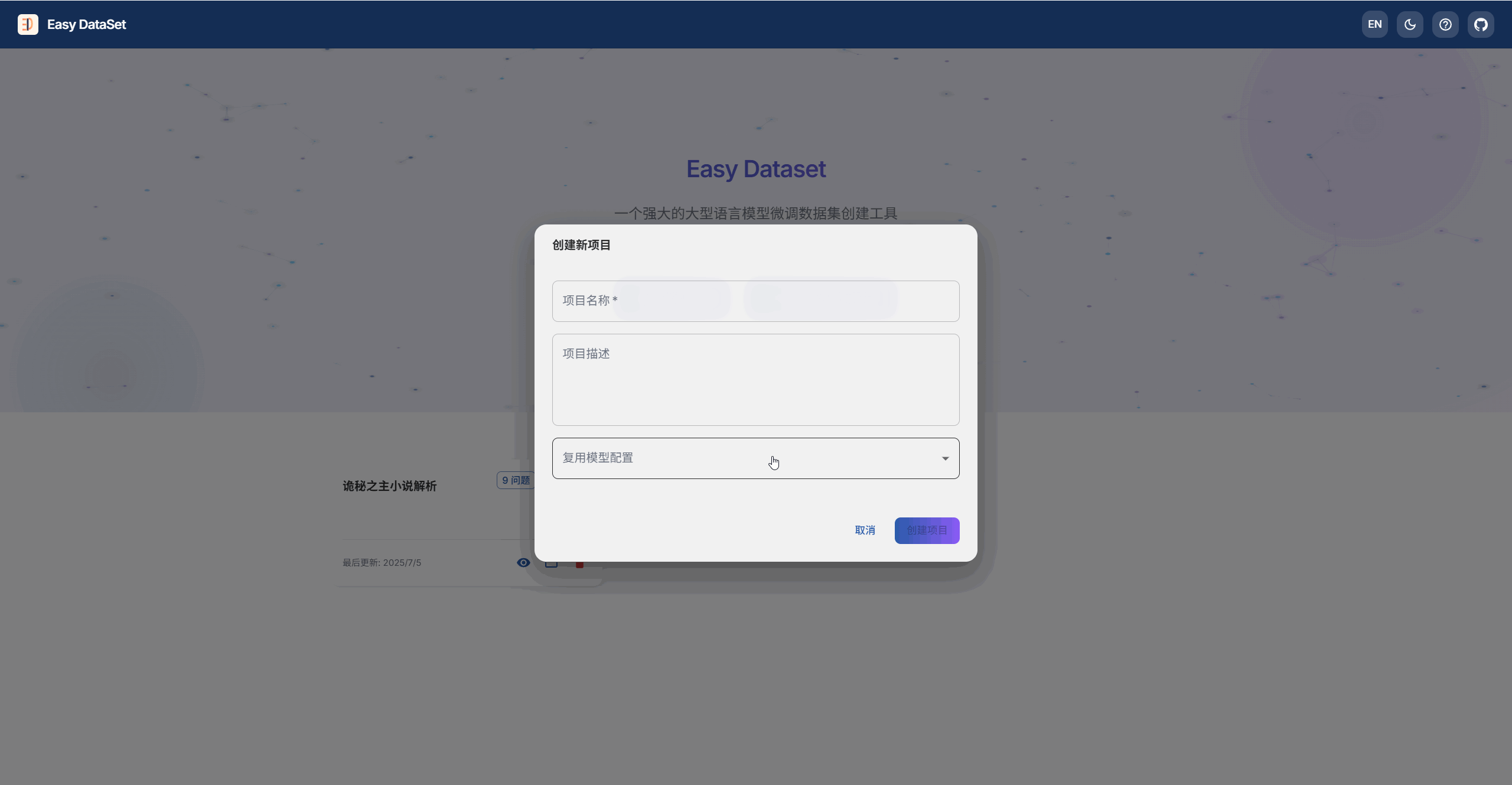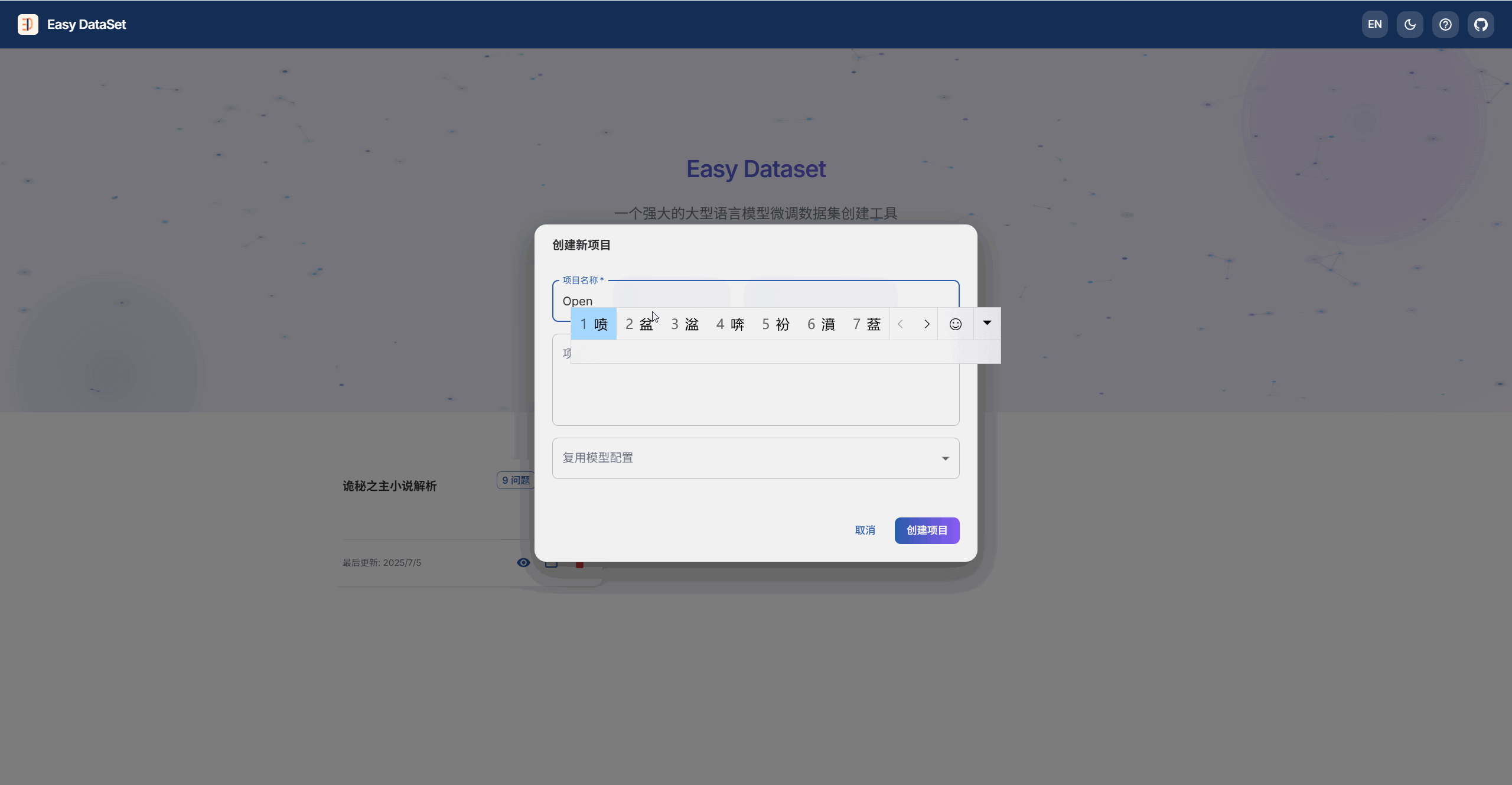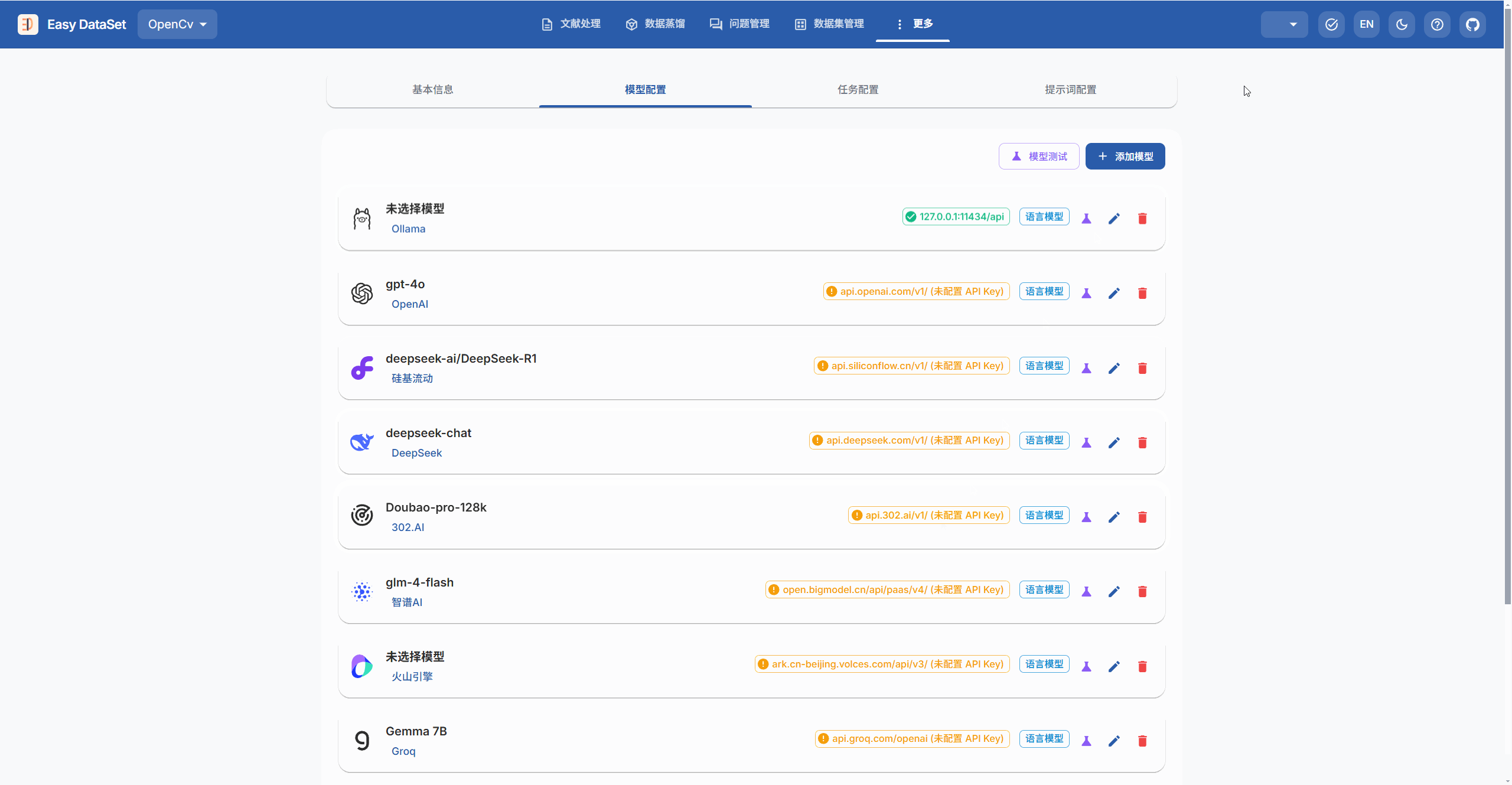
然后,选择你想要的模型,不要的直接删去,新增的点击添加模型;点击下图所指的编辑按钮
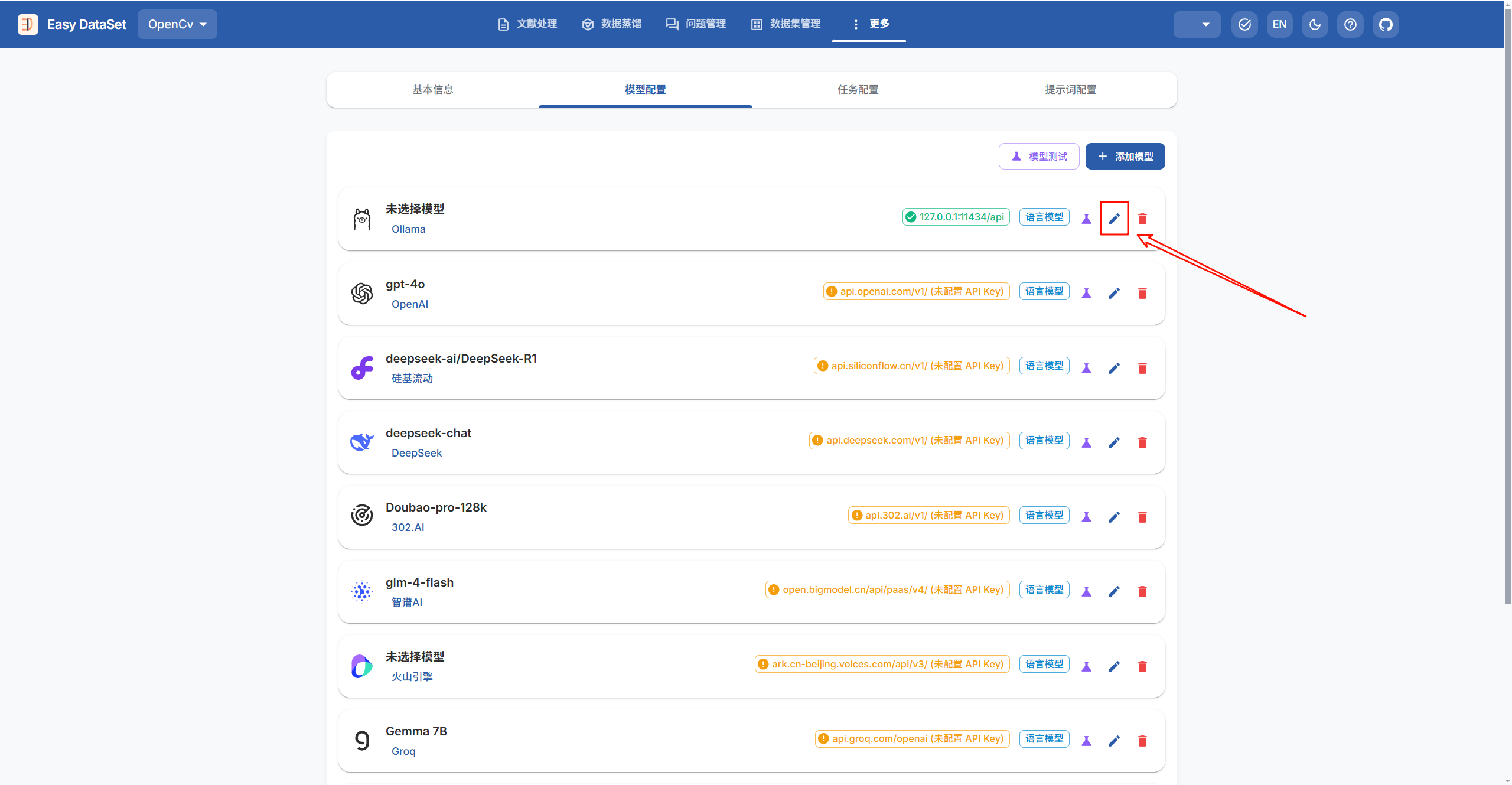
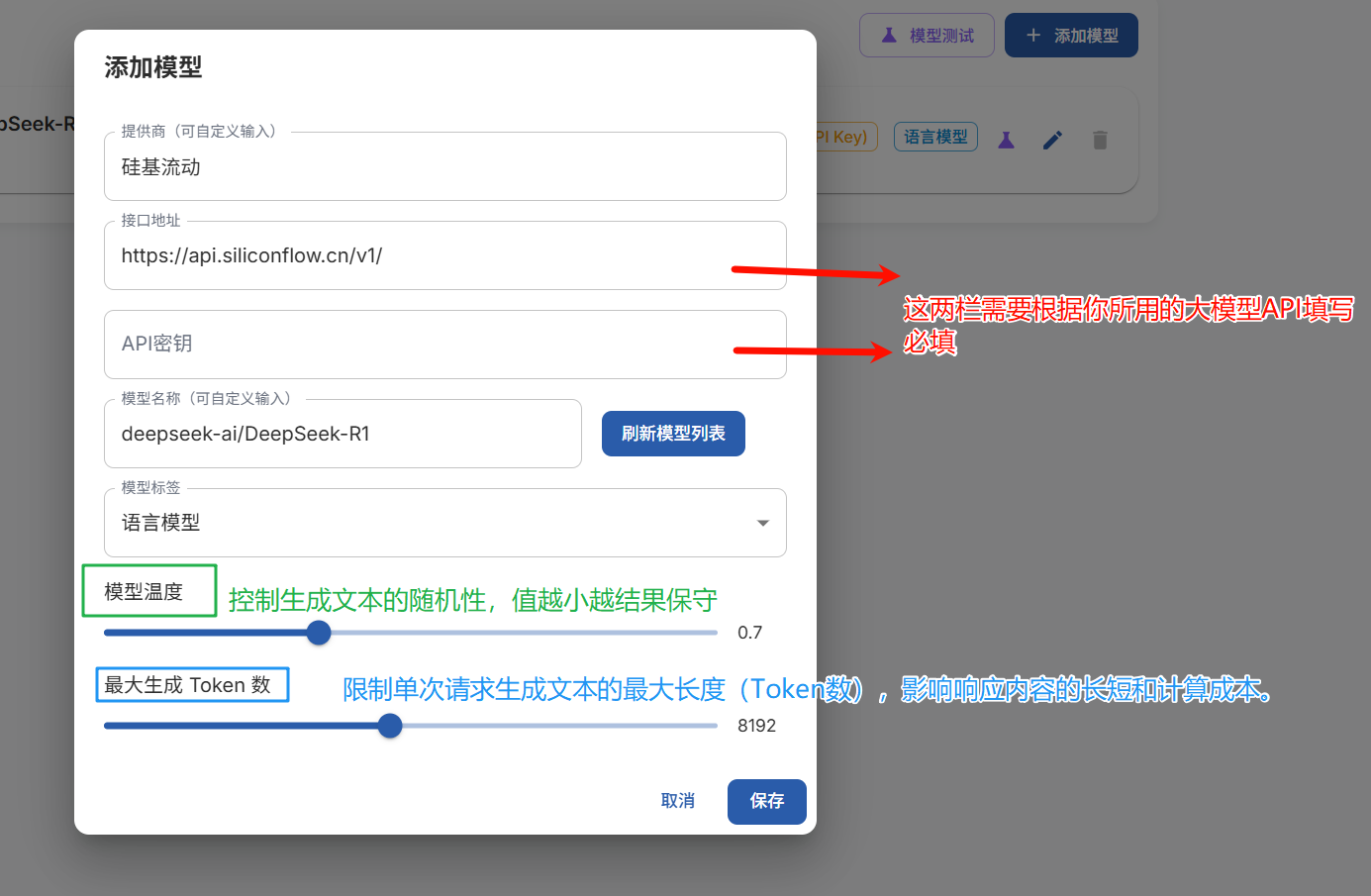
点击后,根据自身需求填写,接口地址和API密钥是必填的,可以按照网上的方法填写
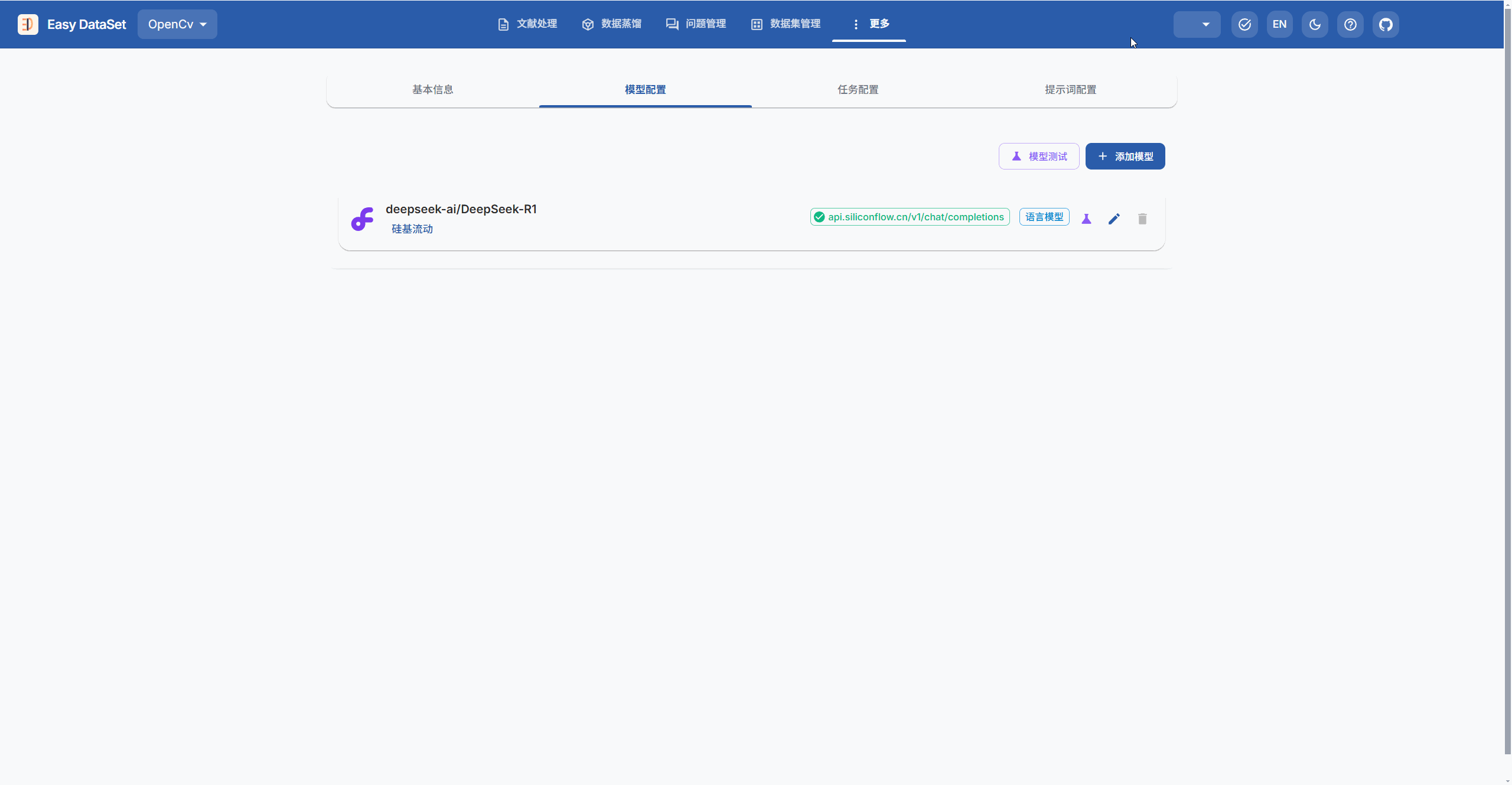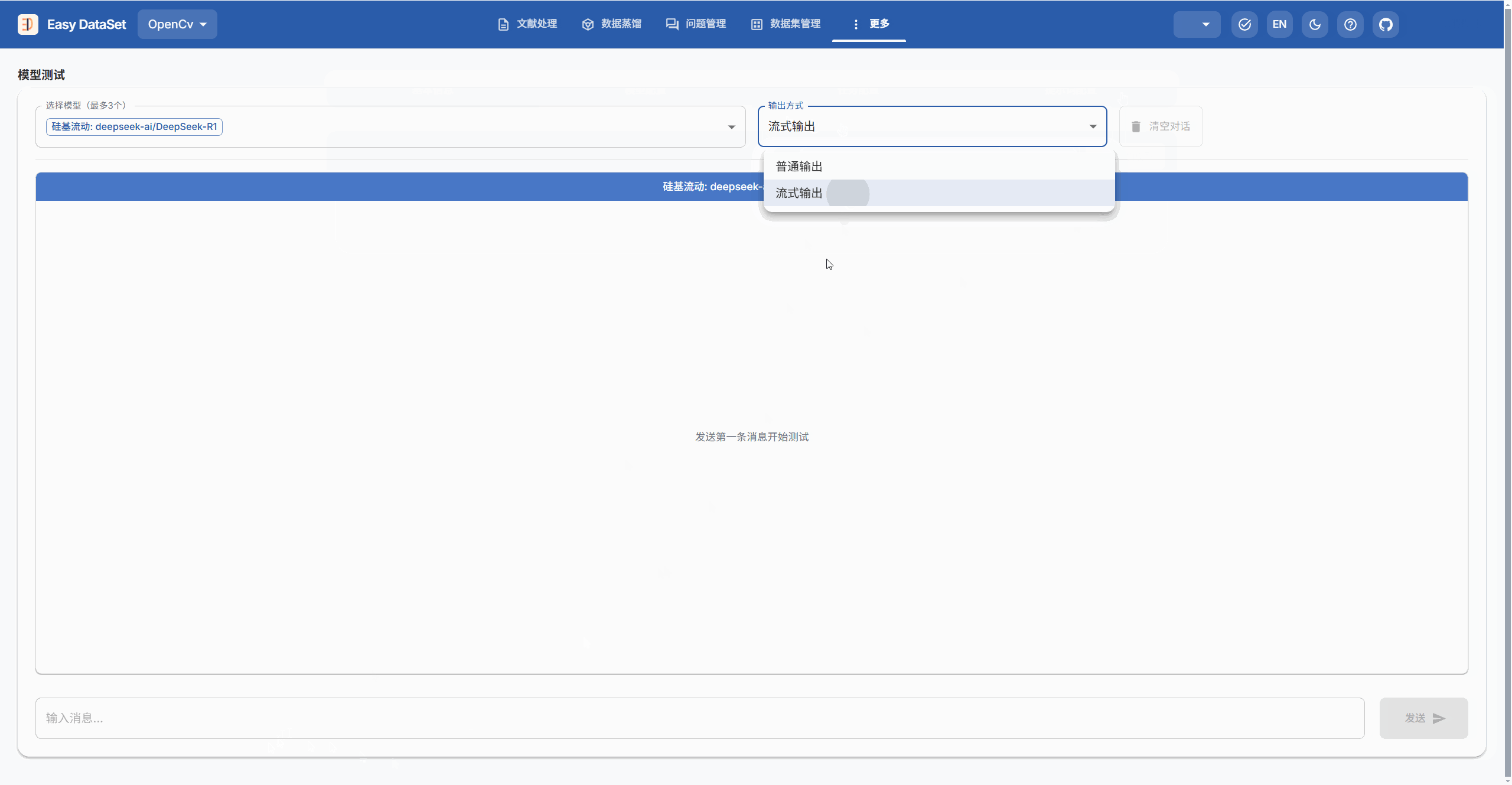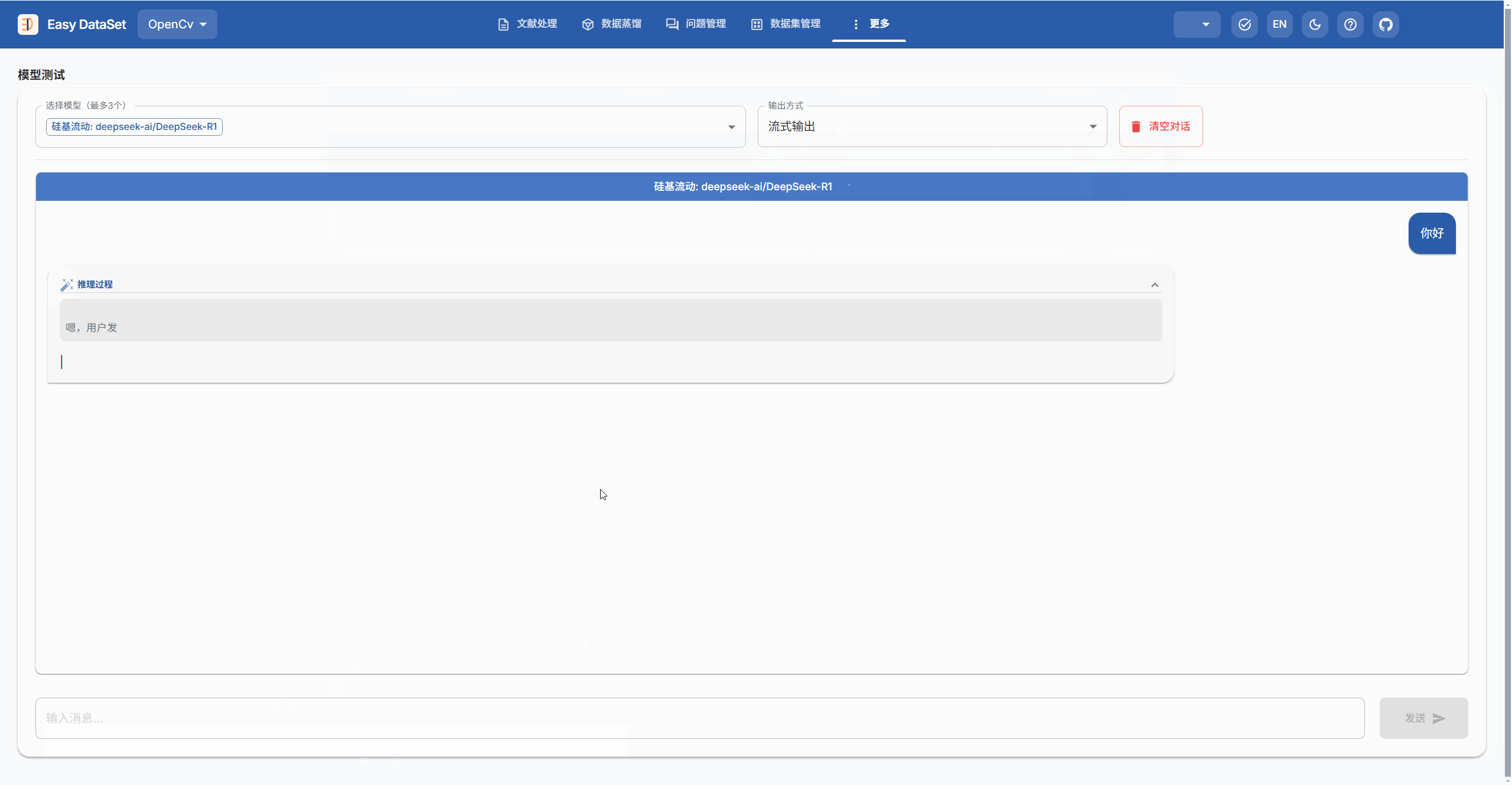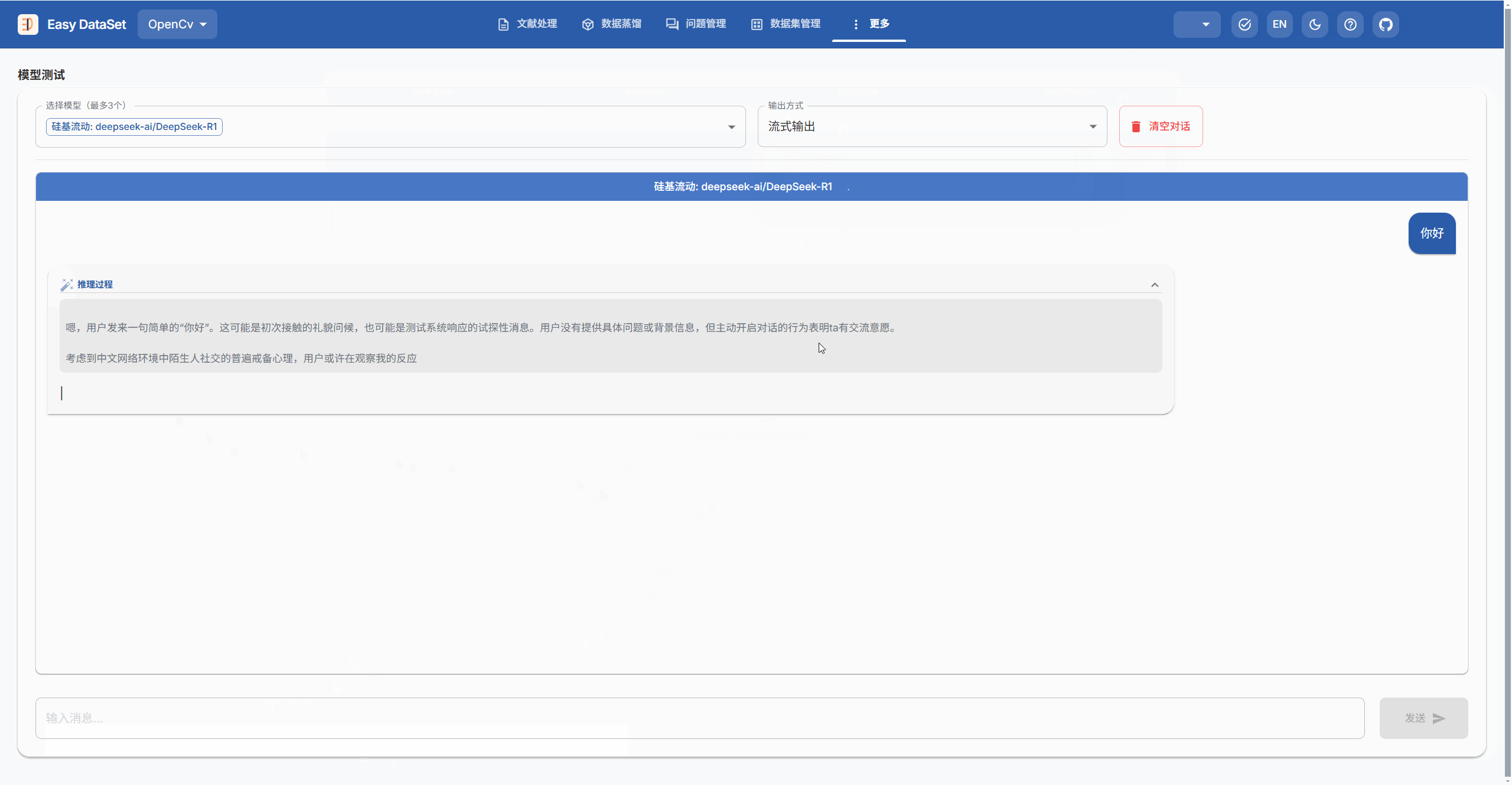
模型配置完成后,可以点击在编辑按钮左边的模型测试按钮,对刚刚配置好的模型进行测试,看看能否正常使用
然后依次点击最上方文献处理,上传所需文献,点击上传并处理文件按钮,软件会自动把文献分割成文本块
注意:PDF格式上传不了,必须转化为markdown或者txt格式
处理完成后,我们需要对每一个文本块来生成问题,选择文本块,点击批量生成问题或者自动提取问题
PS:批量生成问题点击后就不能操作了,而自动提取问题是将任务放在后台,你依然可以使用软件的其他功能,但速度会变慢
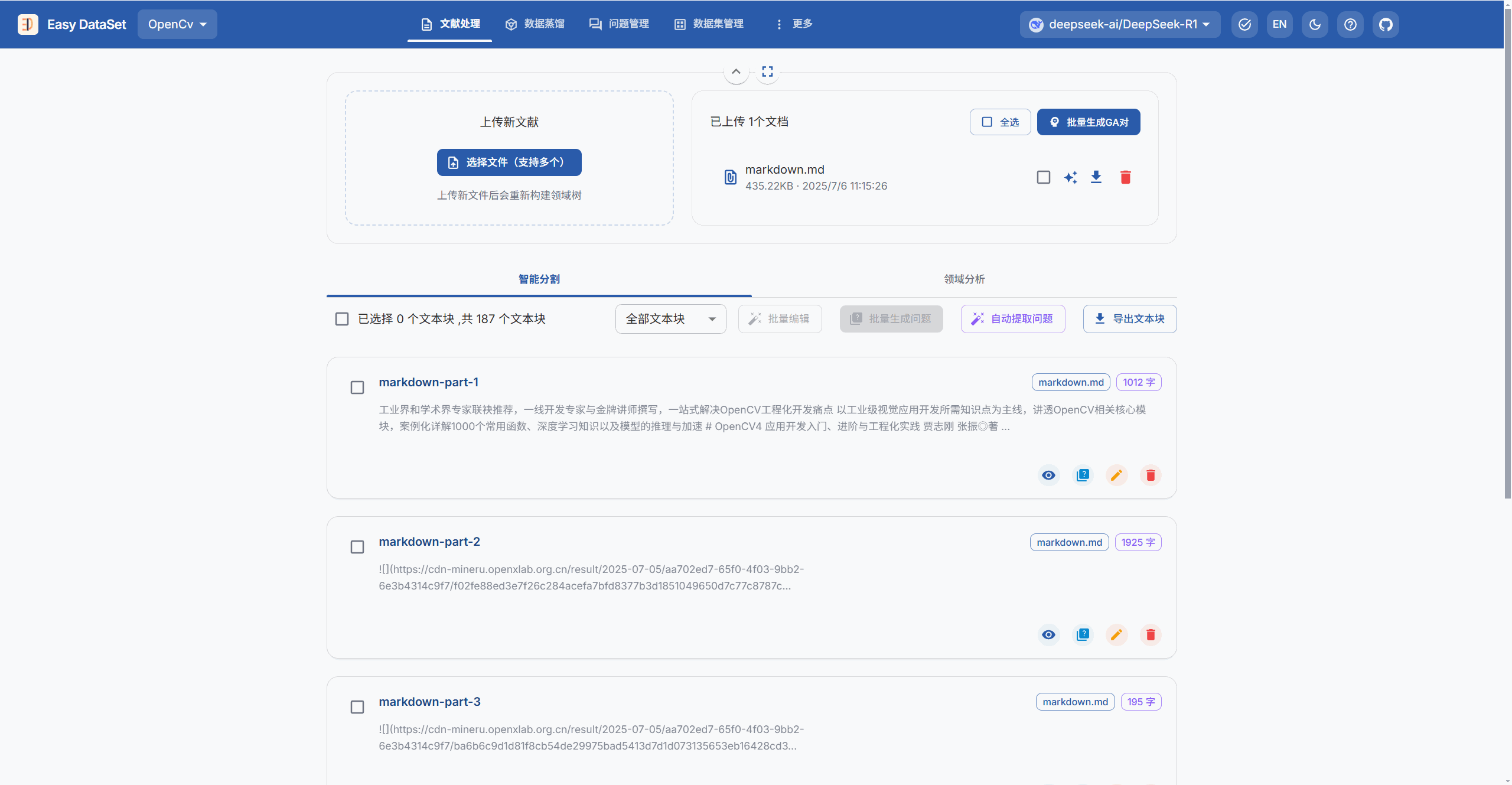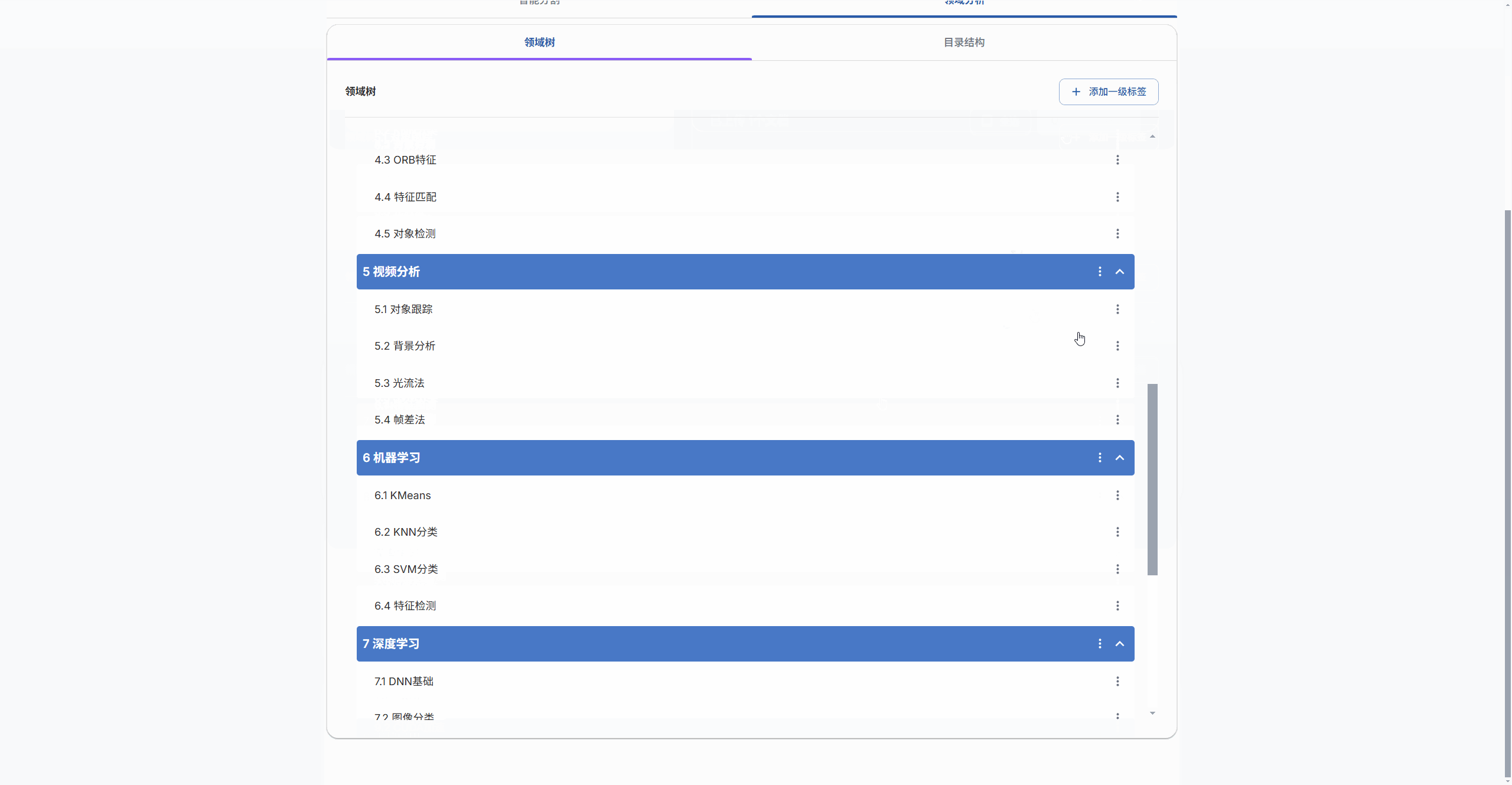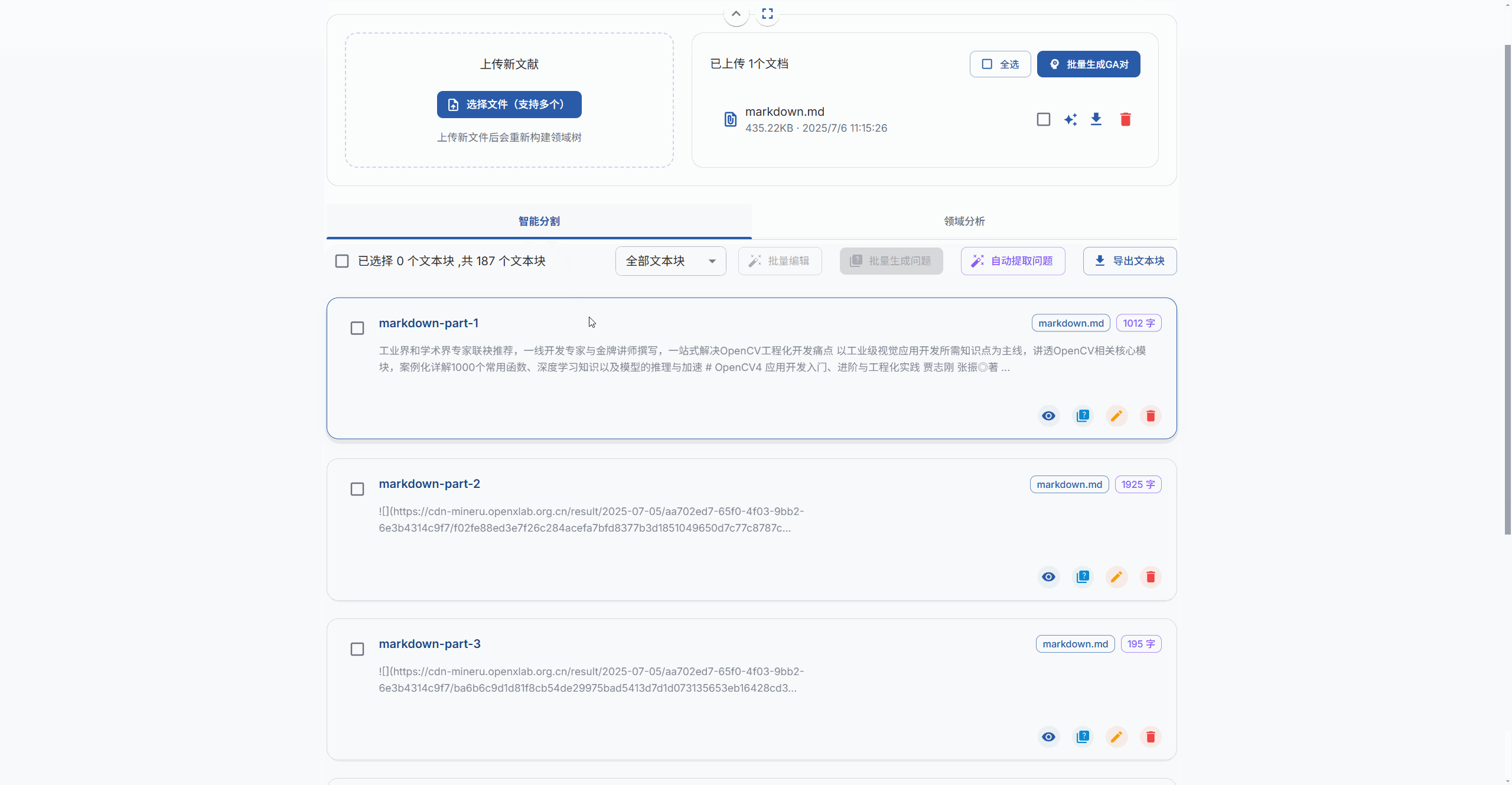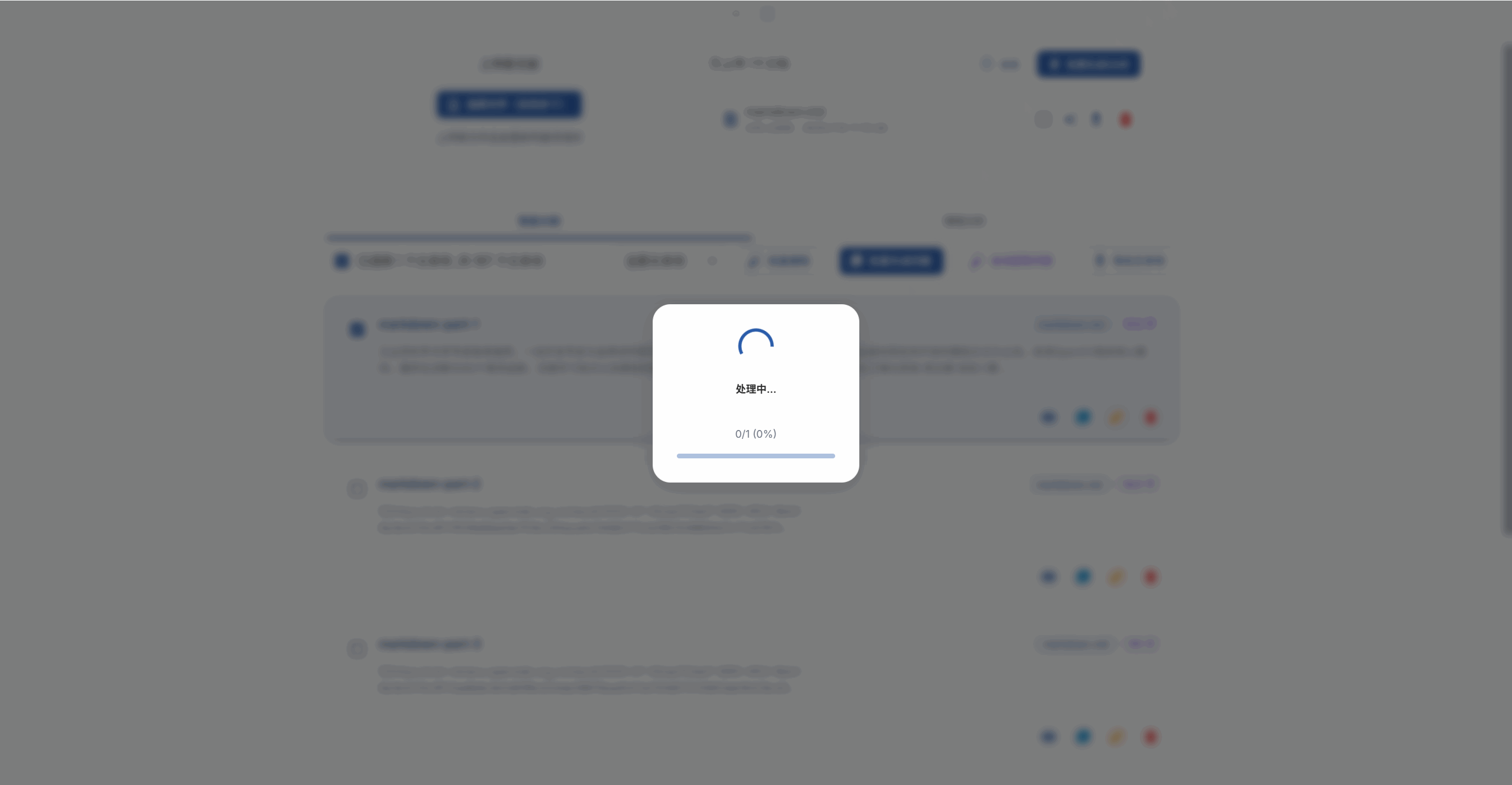
稍等片刻,你可以看到我这一个文本块便生成了4个问题
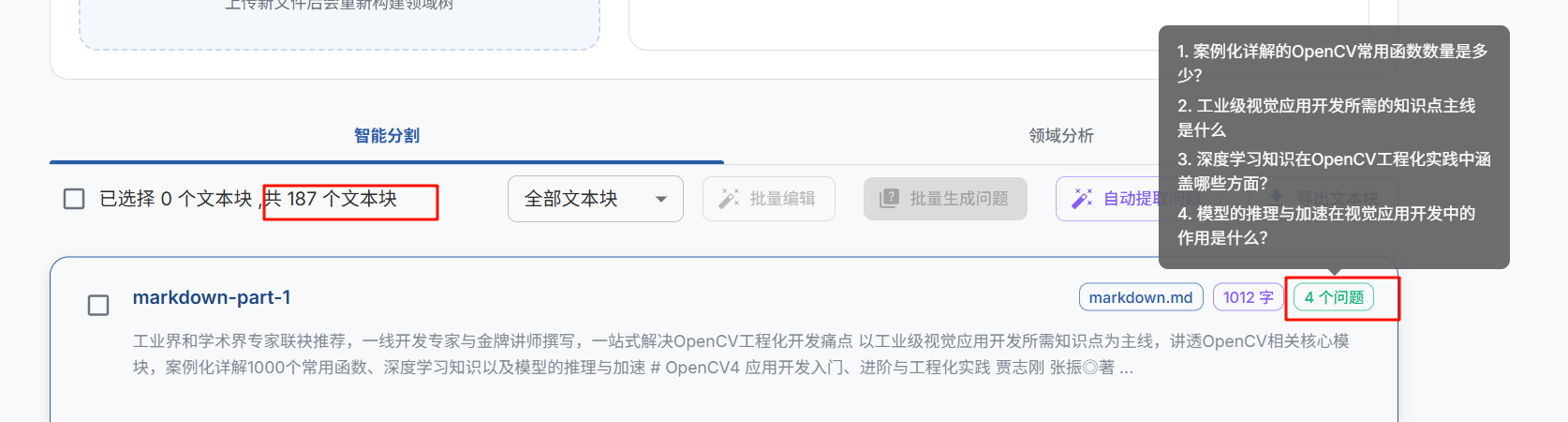
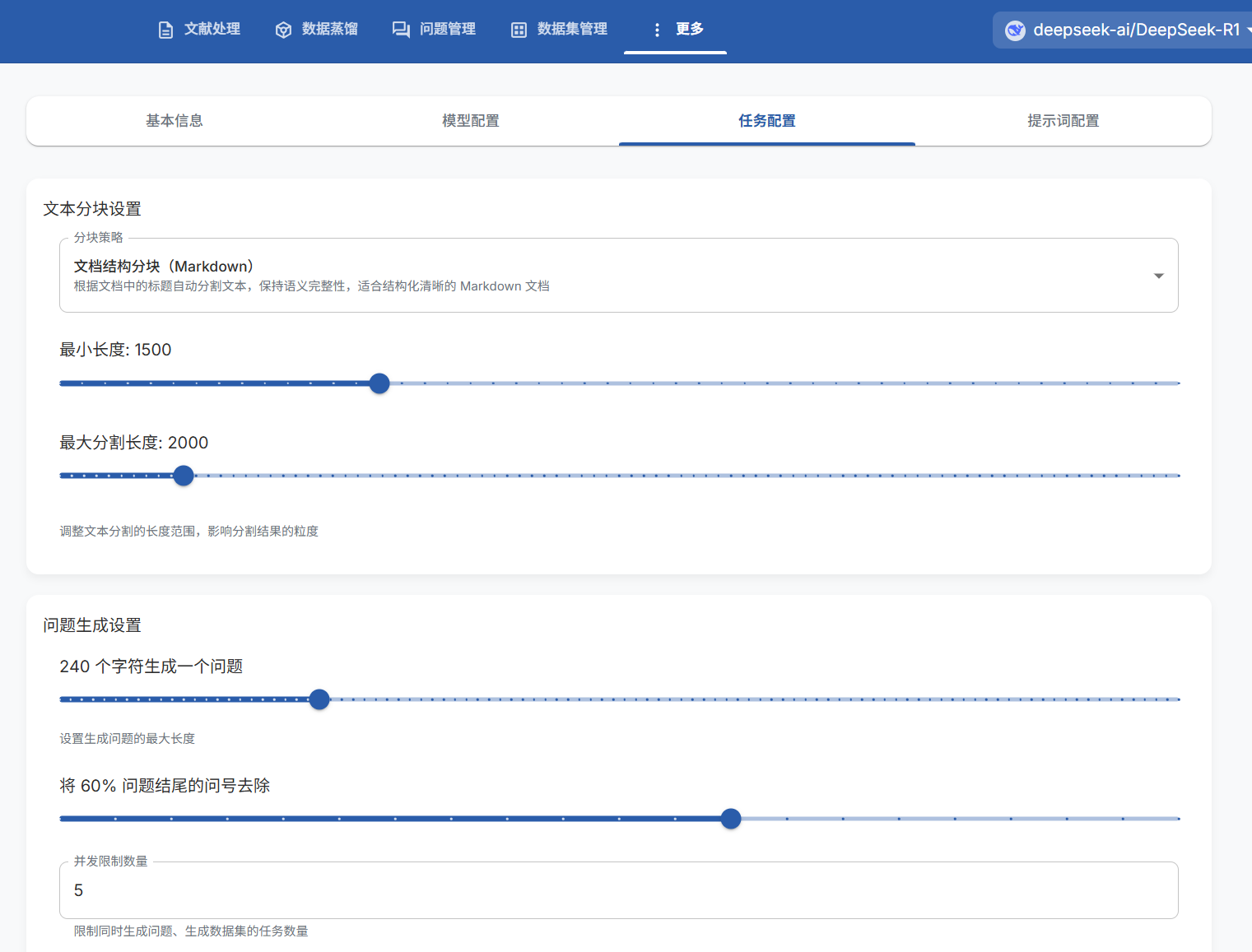
注意:这里的文本块和问题的数目不是随机的,是自己设置的。
在更多→项目设置→任务配置中,可以看到我设置了1500—2000字符为一个文本块,每240个字符一个问题
上面这个文本块有1012个字符,大概就是1012÷240≈4(下取整)
生成完问题后,点击上方栏问题整理→选择文本块→自动生成数据集,软件会自己生成问题的答案
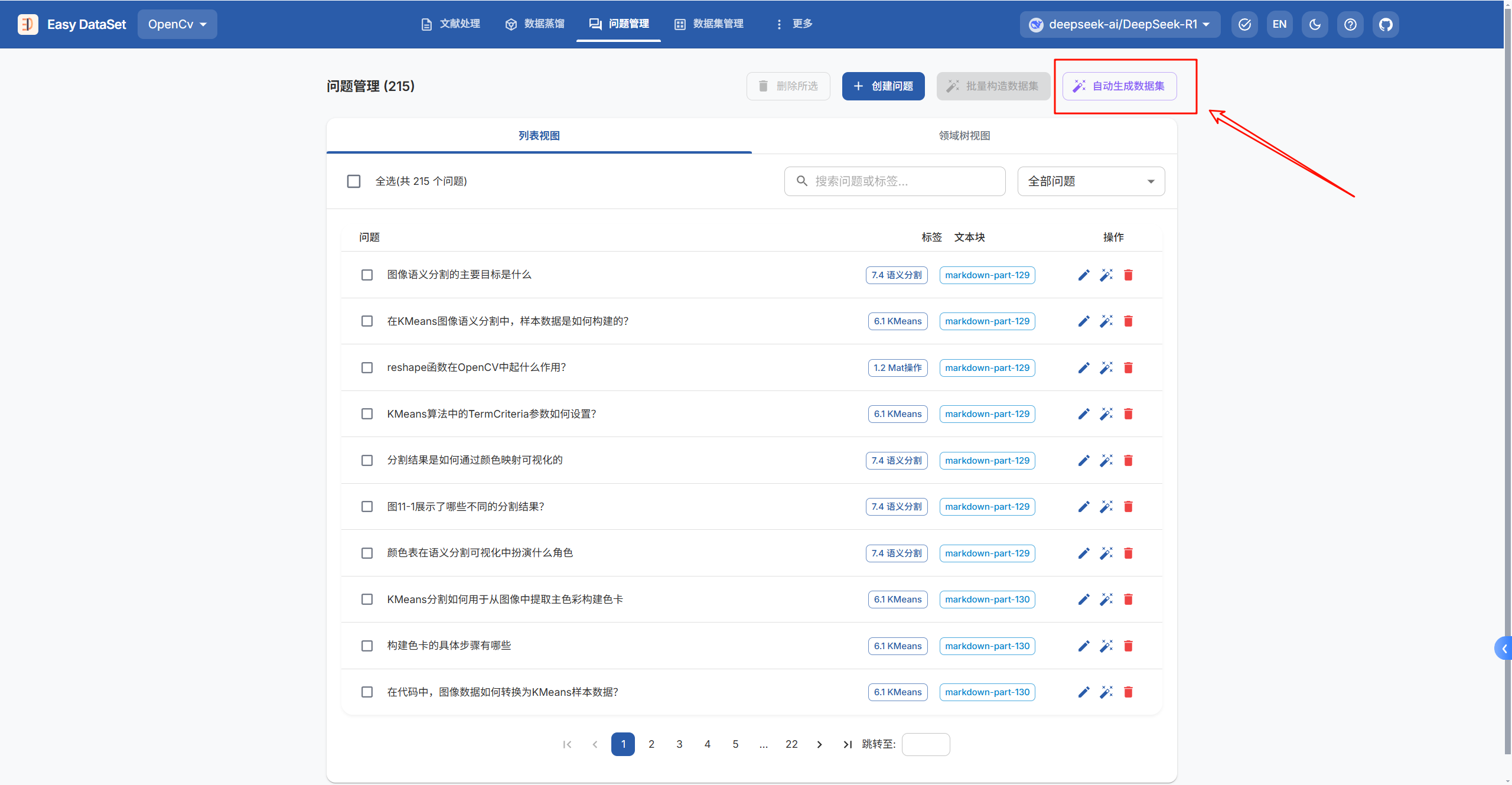
生成完答案后,我们需要在数据集管理→点击一个问题,对问题的答案进行确认,合适的点击确认按钮,不合适的直接删掉。
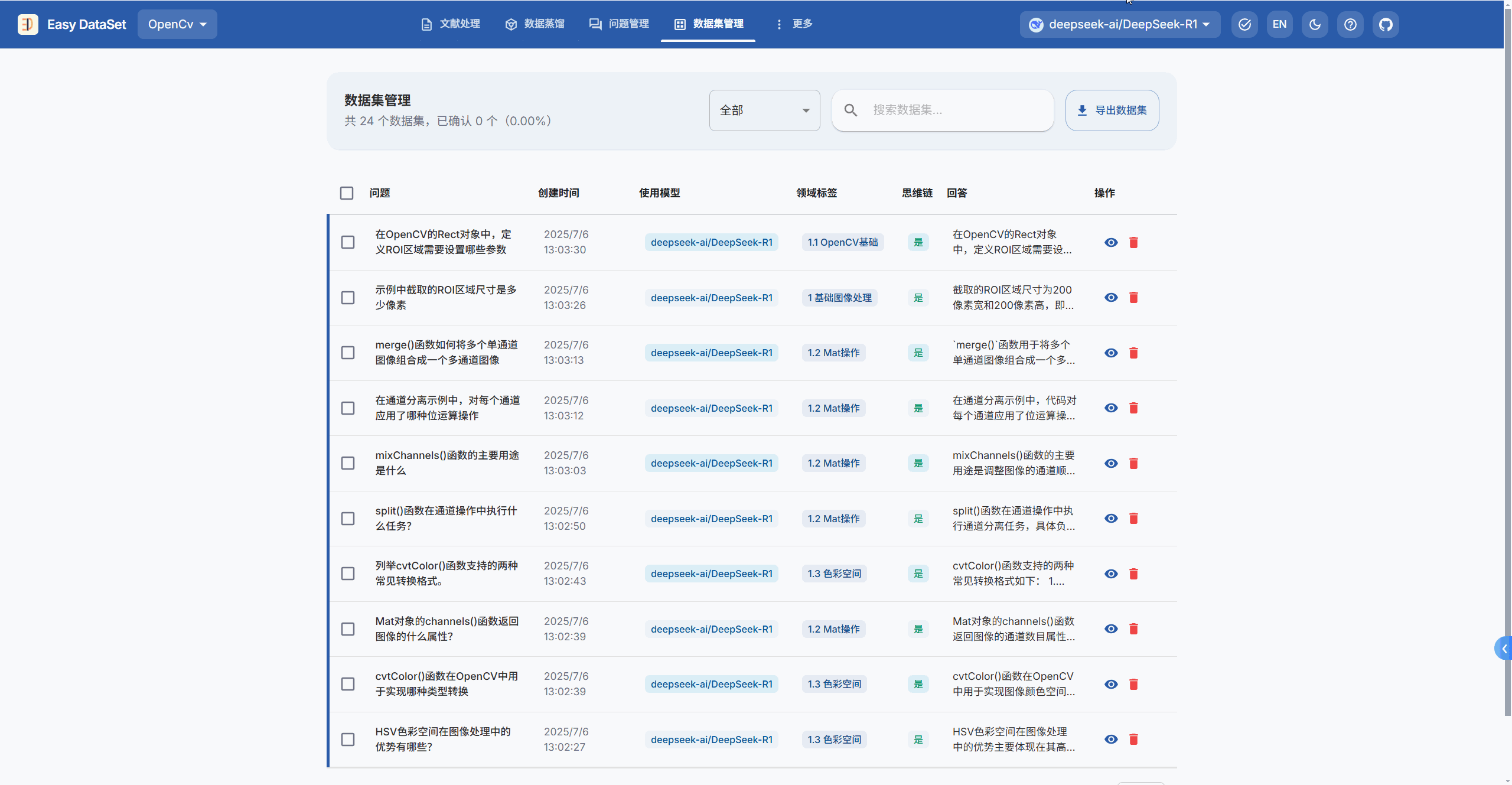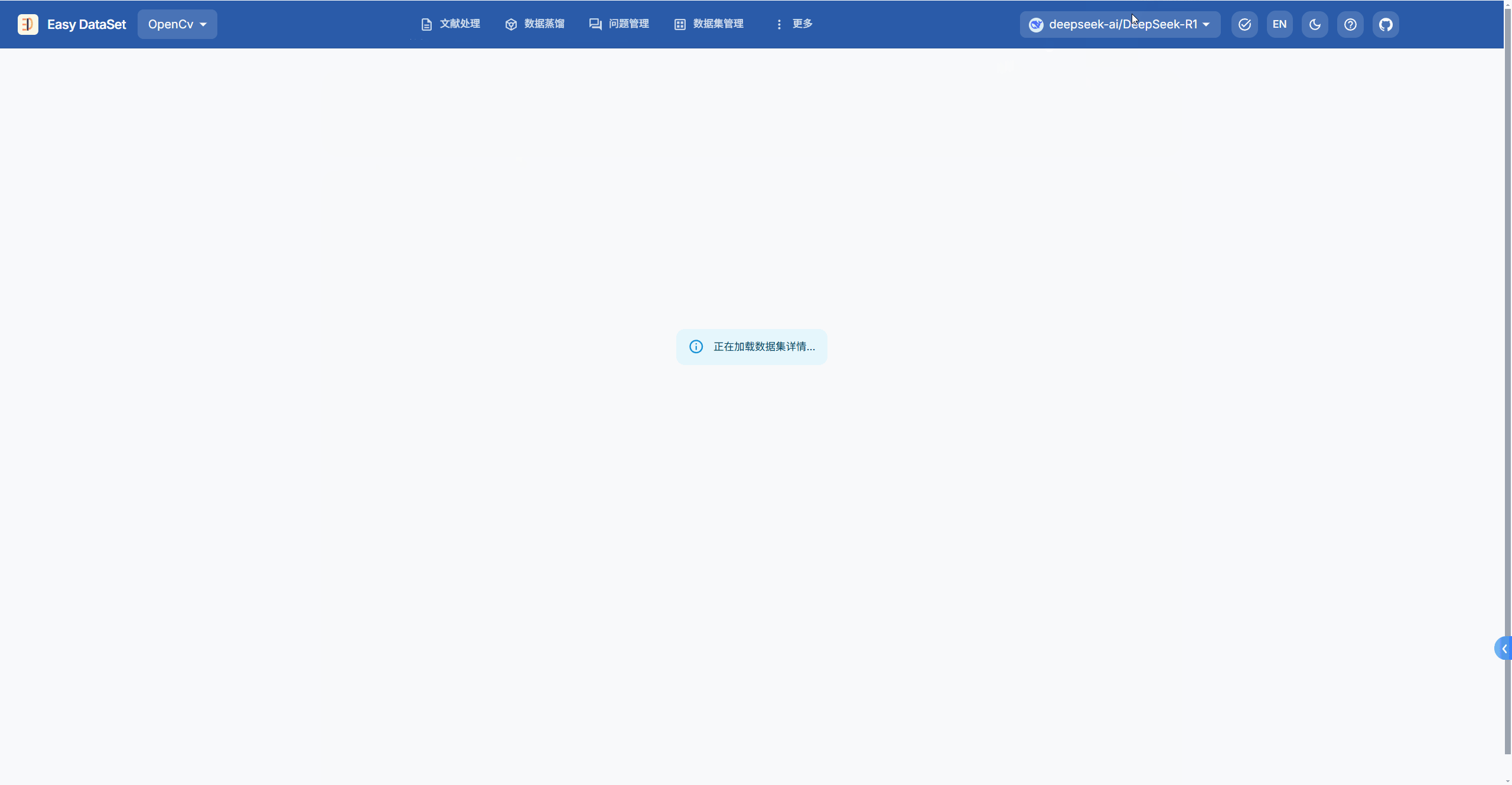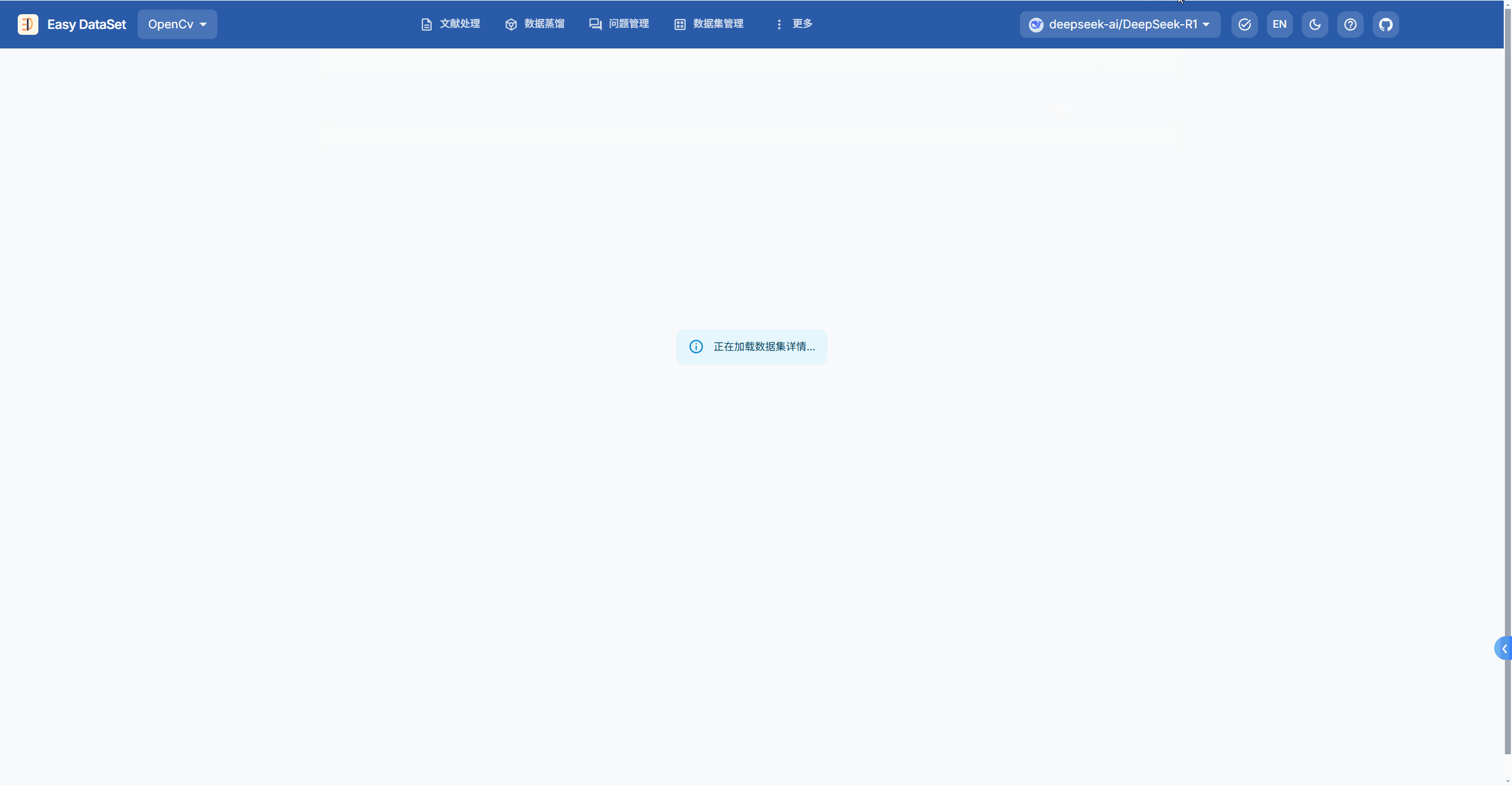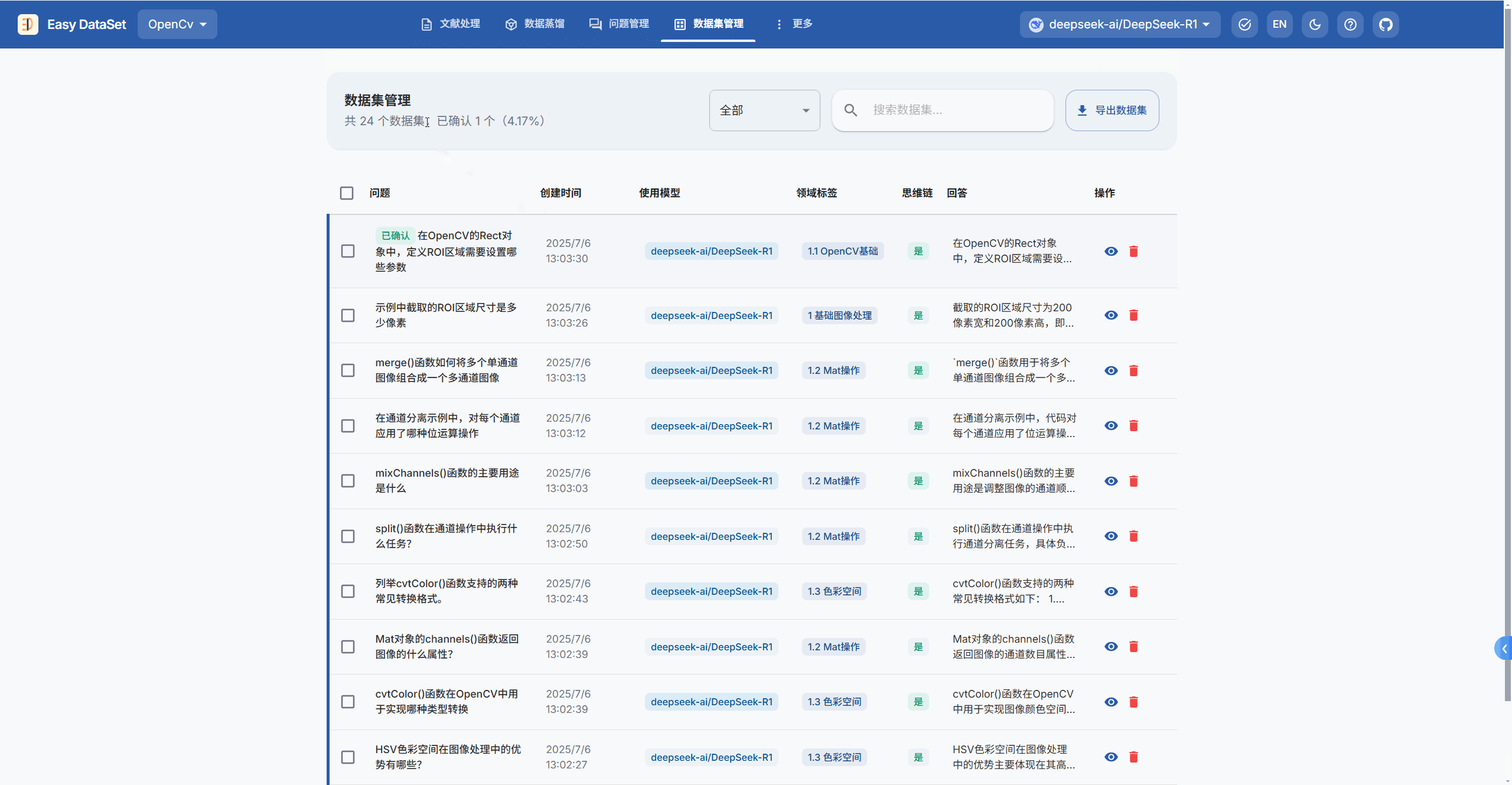
最后点击导出数据集
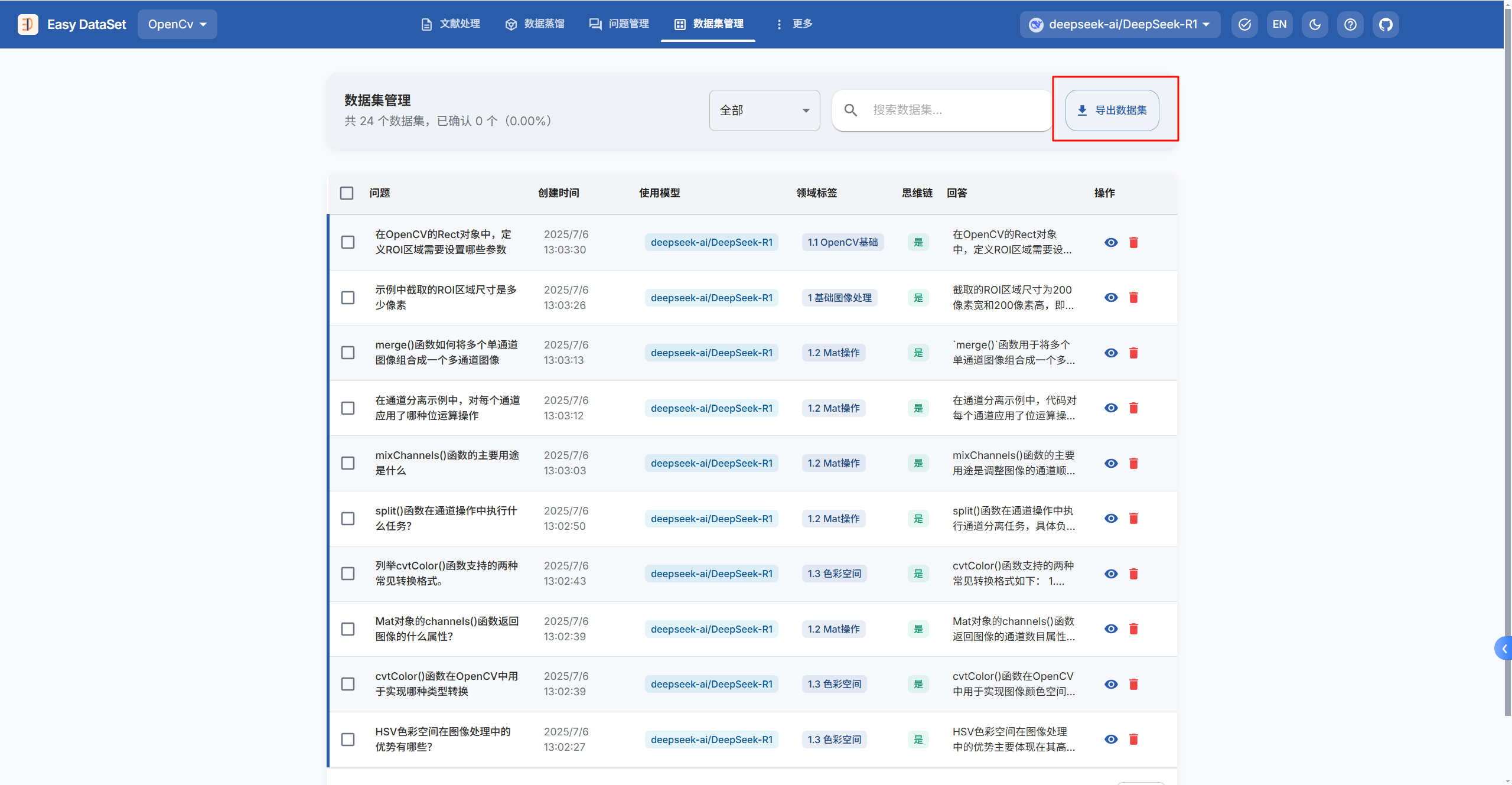
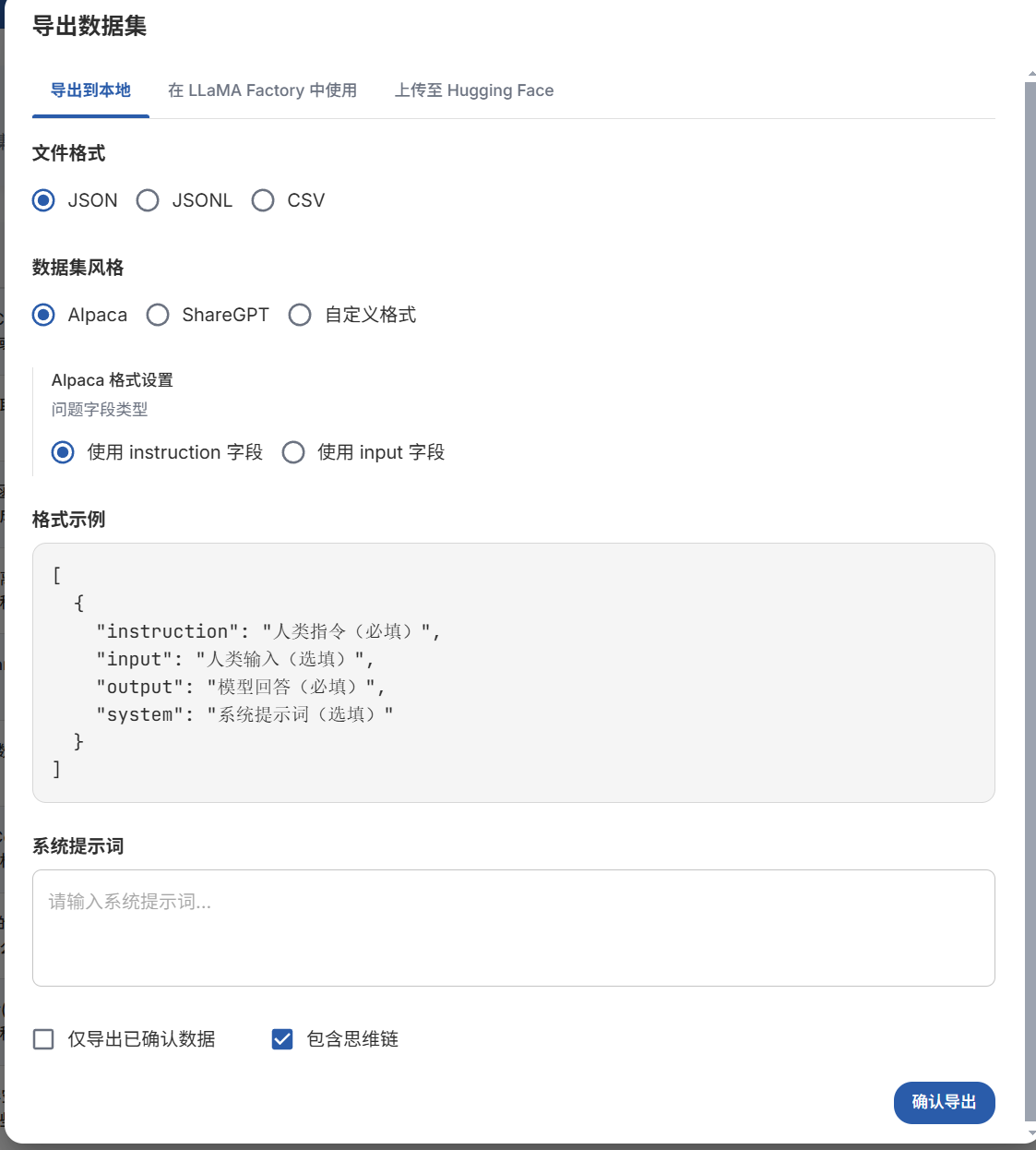
选择好导出格式配置后,数据集就会下载到本地
数据集格式
Easy Dataset支持导出到本地、一键生成 LLaMA Factory 配置、一键上传 Hugging Face 三种方式。
选择文件格式:支持 JSON、JSONL、Excel 三种格式;
选择数据集风格:固定风格支持 Alpaca、ShareGPT;
当然也支持自定义格式和风格。
Alpaca 格式的指令微调数据集:

ShareGPT 格式的指令微调数据集:
